

Before we learn about the money, let’s get this question out of the way:
What Does an iOS App Developer Do?
An iOS app developer is a programmer who focuses on software creation for Apple mobile devices such as iPhones or wearables such as Apple Watches. Most mobile app developers create smartphone apps for the iOS or watchOS mobile operating systems using the Swift programming language.
Learn More:
iOS App Developer Stats

For your motivation, I’ve compiled some interesting stats and facts about mobile app development:
- The revenue of the mobile app market worldwide is mobile app revenue in 2022 is $437 billion USD. (Statista)
- The number of iOS mobile app developers in the world is 2.8 million. (EvansData)
- For comparison, the number of Android mobile app developers in the world is 5.9 million. (EvansData)
- The average revenue per mobile app developer worldwide is $50,229 USD/year. (Finxter)
- The average annual income of a mobile app developer in the US is $101,000 USD. (Finxter)
- The average annual income of a mobile app developer in India is ₹5,17,819. (Glassdoor)
So, are you motivated? Great, let’s have a look on the skills you need next!
What Skills Does an iOS App Developer Need?

As an iOS app developer, your skillset varies depending on the concrete set of applications you’re working on. However, these skills will proof useful no matter what, and most successful mobile iOS app developers have these seven skills:
- General programming skills (e.g., Swift)
- Specific app framework skills (e.g., Flutter)
- Distributed systems skills
- Web development skills (e.g., HTML, CSS, JavaScript)
- Design skills (e.g., Photoshop)
- Security skills (e.g., SSL encryption)
- Soft skills (e.g., communication, presentation, marketing)
Of course, these are only the top seven most important skills from my point of view.
Mobile (iOS) App Developer vs Desktop (macOS) Developer

What’s the difference between a mobile iOS app developer and a desktop developer focusing on macOS?
- An iOS developer creates applications for mobile operating systems iOS and watchOS.
- A desktop developer creates applications for desktop-based operating systems like macOS.
Unlike desktop developers, mobile iOS app developers tend to focus more on utilizing native sensors such as NFC and GPS for location-based applications and more natural human-computer interaction means such as speech and touch.
Of course, there’s a two-way exchange of ideas and technologies because more and more desktop developers integrate ubiquitous computing technologies in their applications. And app developers use traditional “desktop” means of user interfaces such as virtual keyboards.
Now that you know about what it is, let’s have a look at what it earns next!
Annual Income
How much does an iOS App Developer make per year?

Compare the significant income of an iOS developer with the income of a general app developer. iOS developer make $10,000 more than general mobile app developers, on average:

The average annual income of an iOS Developer in the United States is between $83,351 and $145,000 with an average of $110,331 and a statistical median of $111,716 per year.
This data is based on our meta-study of six (6) salary aggregators sources such as Glassdoor, ZipRecruiter, and PayScale.
| Source | Average Income |
|---|---|
| Glassdoor.com | $98,986 |
| ZipRecruiter.com | $108,906 |
| Zippia.com | $100,289 |
| Indeed.com | $128,480 |
| PayScale.com | $91,749 |
| Talent.com | $145,000 |
| Salary.com | $83,351 |
| NixUnited.com | $114,614 |
| BuiltIn.com | $116,145 |
| Comparably.com | $115,794 |
Let’s have a look at the hourly rate of Mobile App Developers next!
Hourly Rate
iOS Developers are well-paid on freelancing platforms such as Upwork or Fiverr.
- Related Article: What’s the best freelancing platform?
If you decide to go the route as a freelance Mobile App Developer, you can expect to make between $40 and $120 per hour on Upwork (source). Assuming an annual workload of 2000 hours, you can expect to make between $80,000 and $240,000 per year.

 Note: Do you want to create your own thriving coding business online? Feel free to check out our freelance developer course — the world’s #1 best-selling freelance developer course that specifically shows you how to succeed on Upwork and Fiverr!
Note: Do you want to create your own thriving coding business online? Feel free to check out our freelance developer course — the world’s #1 best-selling freelance developer course that specifically shows you how to succeed on Upwork and Fiverr!
Industry Demand
But is there enough demand? Let’s have a look at Google trends to find out how interest evolves over time (source):

Looks like the interest in becoming an iOS and watchOS developer slightly decreased over the last couple of years.
But don’t let this fool you—this makes an excellent opportunity for you as a freelance developer because people are searching for hiring iOS app developers like never before:

While the interest in iPhone app development stays constant, the demand for Apple mobile developers is growing continuously. This means that the gap in the market place increases, and you can expect hourly rates to increase in the years to come!
If demand for a scarce resource outstrips the supply growth, prices rise. Your prices. Your income. 
You can see that many freelancers now start creating apps for clients rather than creating apps for themselves—it’s just the more attractive market opportunity:
Learning Path, Skills, and Education Requirements

Do you want to become a Mobile App Developer? Here’s a step-by-step learning path I’d propose to get started with Mobile App :
- Step 1: Introduction to Computer Science (~40 hours)
- Step 2: Introduction to Mobile App Development (~20 hours)
- Step 3: Introduction to Mobile App Development (Free Video Courses) (~10 hours)
- Step 4: Introduction to Swift (Official) (~20 hours)
- Step 5: Swift (Apple Books) (~20 hours)
- Step 6: Introduction to Flutter (~20 hours)
- Step 7: Introduction to Flutter (Free Video Courses) (~10 hours)
The following video exemplifies one of the skills, Flutter, so you can get a quick glimpse into the development process with an app framework:
You can find many additional computer science courses on the Finxter Computer Science Academy (flatrate model).
But don’t wait too long to acquire practical experience!
Even if you have little skills, it’s best to get started as a freelance developer and learn as you work on real projects for clients — earning income as you learn and gaining motivation through real-world feedback.
 Tip: An excellent start to turbo-charge your freelancing career (earning more in less time) is our Finxter Freelancer Course. The goal of the course is to pay for itself!
Tip: An excellent start to turbo-charge your freelancing career (earning more in less time) is our Finxter Freelancer Course. The goal of the course is to pay for itself!
You can find more job descriptions for coders, programmers, and computer scientists in our detailed overview guide:
Related Income of Professional Developers
The following statistic shows the self-reported income from 9,649 US-based professional developers (source).
 The average annual income of professional developers in the US is between $70,000 and $177,500 for various programming languages.
The average annual income of professional developers in the US is between $70,000 and $177,500 for various programming languages.
Question: What is your current total compensation (salary, bonuses, and perks, before taxes and deductions)? Please enter a whole number in the box below, without any punctuation. If you are paid hourly, please estimate an equivalent weekly, monthly, or yearly salary. (source)
The following statistic compares the self-reported income from 46,693 professional programmers as conducted by StackOverflow.
The average annual income of professional developers worldwide (US and non-US) is between $33,000 and $95,000 for various programming languages.
Here’s a screenshot of a more detailed overview of each programming language considered in the report:
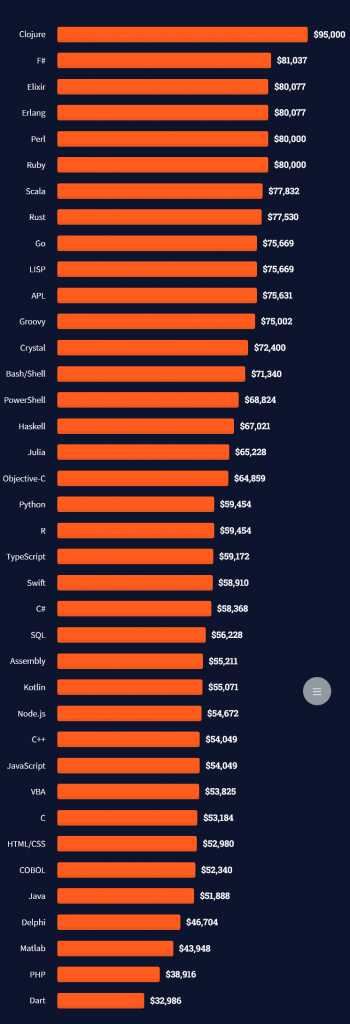
Here’s what different database professionals earn:

Here’s an overview of different cloud solutions experts:

Here’s what professionals in web frameworks earn:

There are many other interesting frameworks—that pay well!
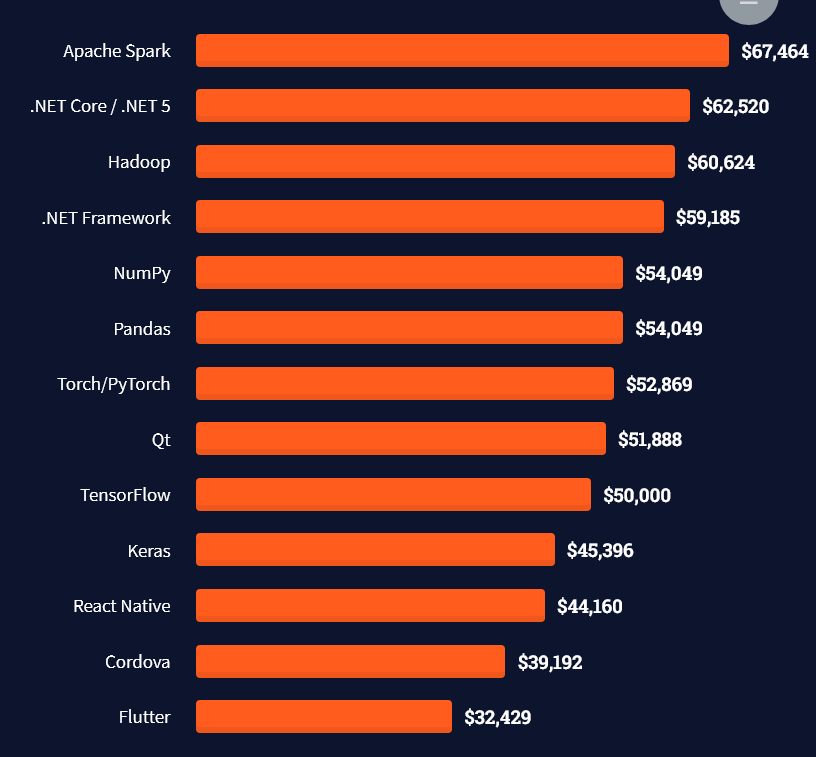
Look at those tools:
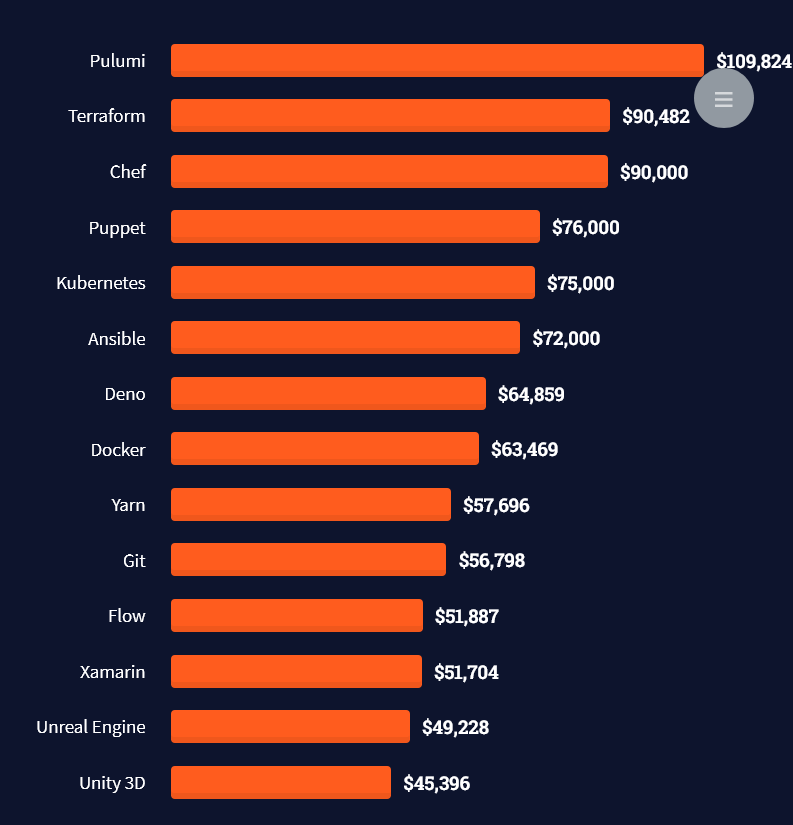
Okay, but what do you need to do to get there? What are the skill requirements and qualifications to make you become a professional developer in the area you desire?
Let’s find out next!
General Qualifications of Professionals
StackOverflow performs an annual survey asking professionals, coders, developers, researchers, and engineers various questions about their background and job satisfaction on their website.
Interestingly, when aggregating the data of the developers’ educational background, a good three quarters have an academic background.
Here’s the question asked by StackOverflow (source):
Which of the following best describes the highest level of formal education that you’ve completed?
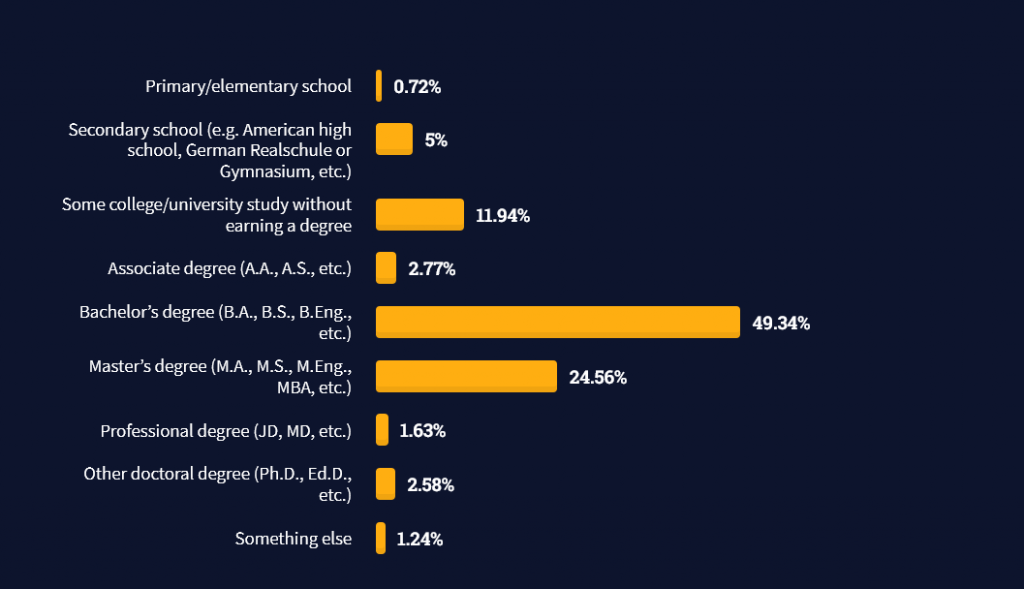
However, if you don’t have a formal degree, don’t fear! Many of the respondents with degrees don’t have a degree in their field—so it may not be of much value for their coding careers anyways.
Also, about one out of four don’t have a formal degree and still succeeds in their field! You certainly don’t need a degree if you’re committed to your own success!
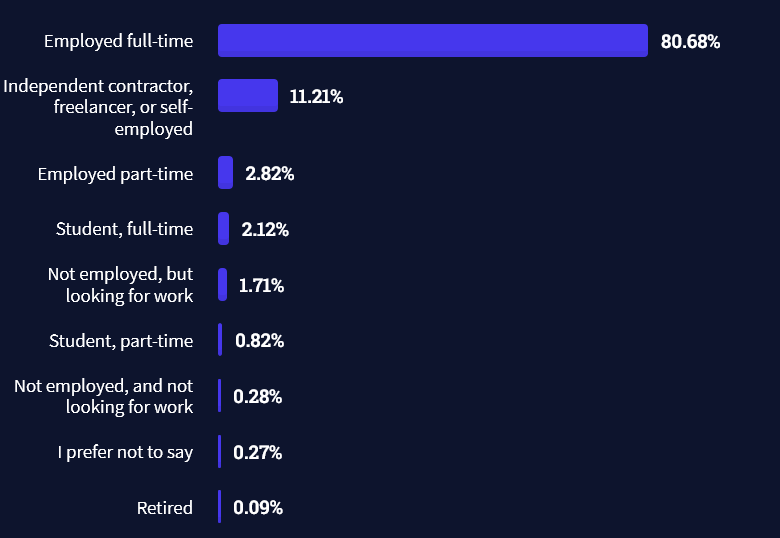
Freelancing vs Employment Status
The percentage of freelance developers increases steadily. The fraction of freelance developers has already reached 11.21%!
This indicates that more and more work will be done in a more flexible work environment—and fewer and fewer companies and clients want to hire inflexible talent.
Here are the stats from the StackOverflow developer survey (source):
Do you want to become a professional freelance developer and earn some money on the side or as your primary source of income?
Resource: Check out our freelance developer course—it’s the best freelance developer course in the world with the highest student success rate in the industry!
Other Programming Languages Used by Professional Developers
The StackOverflow developer survey collected 58000 responses about the following question (source):
Which programming, scripting, and markup languages have you done extensive development work in over the past year, and which do you want to work in over the next year?
These are the languages you want to focus on when starting out as a coder:

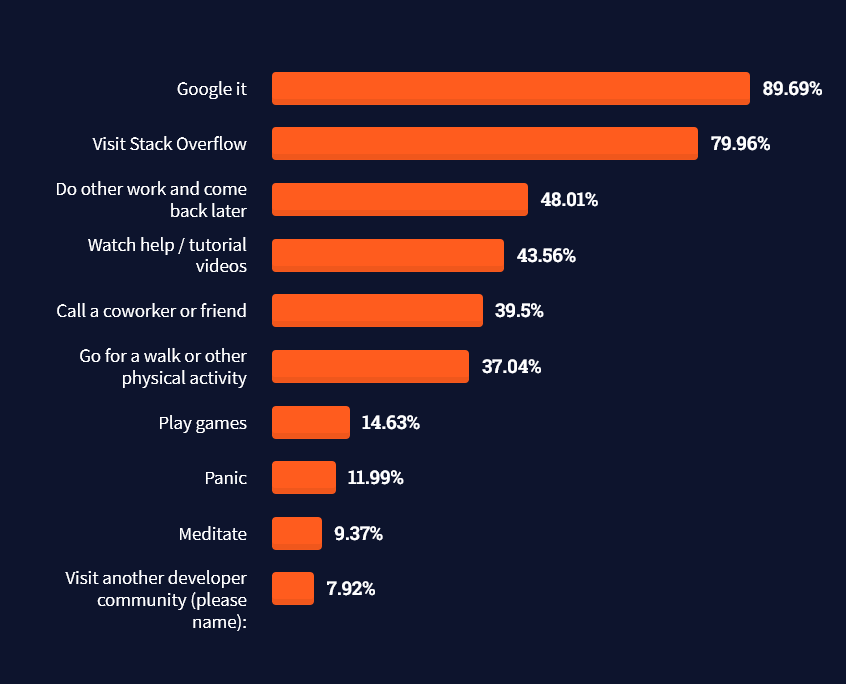
And don’t worry—if you feel stuck or struggle with a nasty bug. We all go through it. Here’s what SO survey respondents and professional developers do when they’re stuck:
What do you do when you get stuck on a problem? Select all that apply. (source)
Related Tutorials
To get started with some of the fundamentals and industry concepts, feel free to check out these articles:
- Freelance Developer – How to Code From Home and Earn Six Figures [Industry Report]
- How to Become a Python Freelancer—and Earn $1,000 on the Side? [A Step-by-Step Tutorial]
- How Adam Earns $5000 per Month as a Python Freelancer on Upwork [Month 4]
- Mobile App Wikipedia
- Learn iOS App Google
Where to Go From Here?
Enough theory. Let’s get some practice!
Coders get paid six figures and more because they can solve problems more effectively using machine intelligence and automation.
To become more successful in coding, solve more real problems for real people. That’s how you polish the skills you really need in practice. After all, what’s the use of learning theory that nobody ever needs?
You build high-value coding skills by working on practical coding projects!
Do you want to stop learning with toy projects and focus on practical code projects that earn you money and solve real problems for people?
If your answer is YES!, consider becoming a Python freelance developer! It’s the best way of approaching the task of improving your Python skills—even if you are a complete beginner.
If you just want to learn about the freelancing opportunity, feel free to watch my free webinar “How to Build Your High-Income Skill Python” and learn how I grew my coding business online and how you can, too—from the comfort of your own home.
Reference
[1] The figure was generated using the following code snippet:
import matplotlib.pyplot as plt
import numpy as np
import math data = [98986, 108906, 100289, 128480, 91749, 145000, 83351, 114614, 116145, 115794] labels = ['Glassdoor.com', 'ZipRecruiter.com', 'Zippia.com', 'Indeed.com', 'PayScale.com', 'Talent.com', 'Salary.com', 'NixUnited.com', 'BuiltIn.com', 'Comparably.com'] median = np.median(data)
average = np.average(data)
print(median, average)
n = len(data) plt.plot(range(n), [median] * n, color='black', label='Median: $' + str(int(median)))
plt.plot(range(n), [average] * n, '--', color='red', label='Average: $' + str(int(average)))
plt.bar(range(len(data)), data)
plt.xticks(range(len(data)), labels, rotation='vertical', position = (0,0.45), color='white', weight='bold')
plt.ylabel('Average Income ($)')
plt.title('iOS App Developer Annual Income - by Finxter')
plt.legend()
plt.show()









 Question: How would we write Python code to check to see if an internet connection has been established?
Question: How would we write Python code to check to see if an internet connection has been established? Problem: How to extract the filename from a path, no matter what the operating system or path format is?
Problem: How to extract the filename from a path, no matter what the operating system or path format is? 
