In this article, we will use PyTorch to build a working neural network. Specifically, this network will be trained to recognize handwritten numerical digits using the famous MNIST dataset.

The code in this article borrows heavily from the PyTorch tutorial “Learn the Basics”. We do this for several reasons.
- First, that tutorial is pretty good at demonstrating the essentials for getting a working neural network.
- Second, just like importing libraries, it’s good to not reinvent the wheel when you don’t have to.
- Third, when building your own network, it is very helpful to start with something that is known to work, then modify it to your needs.
Knowledge Background

This article assumes the reader has some necessary background:
- Familiarity with Python, and Python object-oriented programming.
- Familiarity with how neural networks work. See the Finxter article “The Magic of Neural Networks: History and Concepts” to learn the basic ideas.
- Familiarity with how neural networks learn. See the Finxter article “How Neural Networks Learn” to learn this subject.
- Familiarity with tensors. See the Finxter article “Tensors: the Vocabulary of Neural Networks” to learn this subject.
- Familiarity with Matplotlib. While this is not necessary to follow along, it is necessary if you want to be able to view image data yourself on your own datasets in the future (and you will want to be able to do this).
You can run PyTorch on your own machine, or you can run it on publically available computer systems.
We will be running this exercise using Google Colab, which allows running world-class computing capability, all accessible for free.
 Recommended: Other options for publically available computing are shown in the Finxter article “Top 4 Jupyter Notebook Alternatives for Machine Learning”.
Recommended: Other options for publically available computing are shown in the Finxter article “Top 4 Jupyter Notebook Alternatives for Machine Learning”.
Process Overview

This article will cover all the necessary steps to build and test a working neural network using the PyTorch library.
PyTorch provides a framework that makes building, training, and using neural networks easier. Also under the hood, it is written using the very fast C++ language, so that those neural networks can provide world-class performance while using the popular Python language as the interface to create those networks.
Neural networks and the PyTorch library are rich subjects. So while we will cover all the necessary steps, each step will just scratch the surface of its respective subject.
For example, we will get the image data from datasets built into the PyTorch library. However, the user will eventually want to use neural networks on their own data, so the users will need to learn how to build and work with their own datasets.
So for each of these steps, the user will want to learn more on each subject to become a proficient PyTorch user.
Nevertheless, by the end of this article, you will have built your own working neural network, so you can be sure you will know how to do it!
Further learning will enrich those abilities. Throughout the article, we will point out some of the other things you will eventually want to learn for each step.
Here are the steps we will be taking:
- Import necessary libraries.
- Acquire the data.
- Review the data to understand it.
- Create data loaders for loading the data into the network.
- Design and create the neural network.
- Specify the loss measure and the optimizer algorithm.
- Specify the training and testing functions.
- Train and test the network using the specified functions.
Step 1: Import Necessary Libraries

Before we do anything, we will want to set up our runtime to use the GPU (again, assuming here you are using Colab).
Click on “Runtime” in the top menu bar, and then choose “Change runtime type” from the dropdown. Then from the window that pops up choose “GPU” under “Hardware accelerator”, and then click “Save”.
Next, we will need to import a number of libraries:
- We will import the
torchlibrary, making PyTorch available for use. - From the
torchmodule we will import thennlibrary, which is important for building the neural network. - From the
torchvisionmodule we will import thedatasetslibrary, which will help provide the image datasets. - From the
datautilities module, we will import theDataLoaderlibrary. Data loaders help load data into the network. - From the
torchvision.transformsmodule we will import theToTensorlibrary. This converts the image data into tensors so that they are ready to be processed through the network.
Here is the code importing the needed modules:
import torch from torch import nn from torchvision import datasets from torch.utils.data import DataLoader from torchvision.transforms import ToTensor
Step 2: Acquire the Data

As mentioned before, in this exercise, we will be getting the MNIST data as available directly through PyTorch libraries. This is the quickest and easiest approach to getting the data.
If you wanted to get the original datasets they are available at:
http://yann.lecun.com/exdb/mnist/
Even though we will get the data through the PyTorch libraries, it can still be helpful to review this page, as it provides some useful information about the dataset. (However we will provide everything you need to understand this dataset in the article).
 Note: Firefox has trouble accessing this page, for some reason requiring a login to access it. Either view it using another browser, or view it as recorded on the Internet Archive Wayback Machine.
Note: Firefox has trouble accessing this page, for some reason requiring a login to access it. Either view it using another browser, or view it as recorded on the Internet Archive Wayback Machine.
There are multiple datasets available through the PyTorch dataset libraries. Here are PyTorch webpages linking to Image Datasets, Text Datasets, and Audio Datasets.
To get data from a PyTorch dataset we create an instance from the respective dataset class. Here is the format:
dataset_instance = DatasetClass(parameters)
This creates a dataset object, and downloads the data. The data is then available by working with the dataset object.
Here is the code to create our MNIST datasets:
# Download MNIST data, put it in pytorch dataset mnist_data = datasets.MNIST( root='mnist_nn', train=True, download=True, transform=ToTensor() )
mnist_test_data = datasets.MNIST( root='mnist_nn', train=False, download=True, transform=ToTensor() )
You’ll use these parameters:
- The
rootparameter specifies the directory where the downloaded data will be placed. - The
trainparameter determines whether training or testing data is downloaded. - The
download=Trueparameter confirms the data should be downloaded if it hasn’t been already. - The
transformparameter converts the data into tensors, in this case.
What parameters are available vary from dataset to dataset, as does how the data is structured, so refer to the dataset web pages mentioned above to review the details of what is available and needed.
While this method of getting data is convenient and easy, remember that you will eventually want to work with your own data, so eventually, you will want to learn how to create your own datasets.
Also, not all datasets contain images with uniform image size, so images may need to be cropped or stretched to fit the fixed number of input neurons.
Also, other transformations can be helpful as well.
For example, you can effectively expand your dataset by including subcrops from your original dataset as additional images to train on. So data transformations is something else you will want to learn that you might use at this stage in the process.
Step 3: Review the Dataset

Now that we have downloaded the data and created a dataset, let’s review the dataset to understand its contents and structure.
type(mnist_data) # torchvision.datasets.mnist.MNIST
The type() function shows that our dataset is an object of the MNIST dataset class.
Conveniently, PyTorch datasets have been designed to be indexed like lists. Let’s take advantage of this and use the len() function to learn something about our datasets:
len(mnist_data) # 60000
len(mnist_test_data) # 10000
So our training dataset contains 60000 items, and our test dataset contains 10000 items, consistent with the number of images specified to be in each respective dataset.
Let’s use the type() and len() functions to examine the first item in the training dataset:
type(mnist_data[0]) # tuple
len(mnist_data[0]) # 2
So the items in the datasets are tuples containing 2 items.
Let’s use the type() function to learn about the first item in the tuple:
type(mnist_data[0][0]) # torch.Tensor
So the first item in the tuple is a tensor, likely some image data.
Let’s examine the shape attribute of the tensor to understand its shape:
mnist_data[0][0].shape # torch.Size([1, 28, 28])
This is consistent with the 28*28 pixel structure of the image data, plus one additional dimension containing the entire image data.
Let’s examine the second item in the tuple:
type(mnist_data[0][1]) # int
mnist_data[0][1] # 5
So the second item is the integer '5', apparently the label for an image of the digit '5'.
Let’s use Matplotlib to view the image:
import matplotlib.pyplot as plt plt.imshow(mnist_data[0][0], cmap='gray')
Output:
TypeError Traceback (most recent call last)
<ipython-input-14-3e7278364eac> in <module>
----> 1 plt.imshow(mnist_data[0][0], cmap='gray') /usr/local/lib/python3.7/dist-packages/matplotlib/pyplot.py in imshow(X, cmap, norm, aspect, interpolation, alpha, vmin, vmax, origin, extent, shape, filternorm, filterrad, imlim, resample, url, data, **kwargs) 2649 filternorm=filternorm, filterrad=filterrad, imlim=imlim, 2650 resample=resample, url=url, **({"data": data} if data is not
-> 2651 None else {}), **kwargs) 2652 sci(__ret) 2653 return __ret /usr/local/lib/python3.7/dist-packages/matplotlib/__init__.py in inner(ax, data, *args, **kwargs) 1563 def inner(ax, *args, data=None, **kwargs): 1564 if data is None:
-> 1565 return func(ax, *map(sanitize_sequence, args), **kwargs) 1566 1567 bound = new_sig.bind(ax, *args, **kwargs) /usr/local/lib/python3.7/dist-packages/matplotlib/cbook/deprecation.py in wrapper(*args, **kwargs) 356 f"%(removal)s. If any parameter follows {name!r}, they " 357 f"should be pass as keyword, not positionally.")
--> 358 return func(*args, **kwargs) 359 360 return wrapper /usr/local/lib/python3.7/dist-packages/matplotlib/cbook/deprecation.py in wrapper(*args, **kwargs) 356 f"%(removal)s. If any parameter follows {name!r}, they " 357 f"should be pass as keyword, not positionally.")
--> 358 return func(*args, **kwargs) 359 360 return wrapper /usr/local/lib/python3.7/dist-packages/matplotlib/axes/_axes.py in imshow(self, X, cmap, norm, aspect, interpolation, alpha, vmin, vmax, origin, extent, shape, filternorm, filterrad, imlim, resample, url, **kwargs) 5624 resample=resample, **kwargs) 5625 -> 5626 im.set_data(X) 5627 im.set_alpha(alpha) 5628 if im.get_clip_path() is None: /usr/local/lib/python3.7/dist-packages/matplotlib/image.py in set_data(self, A) 697 or self._A.ndim == 3 and self._A.shape[-1] in [3, 4]): 698 raise TypeError("Invalid shape {} for image data"
--> 699 .format(self._A.shape)) 700 701 if self._A.ndim == 3: TypeError: Invalid shape (1, 28, 28) for image data
Oops, that extra one-item dimension (containing the whole image) is causing us problems. We can use the squeeze() method on the tensor to get rid of any one-element dimensions, and instead return a two-dimensional 28*28 tensor, instead of the three-dimensional tensor we had before.
Let’s try again:
plt.imshow(mnist_data[0][0].squeeze(), cmap='gray') # <matplotlib.image.AxesImage at 0x7f5b5e336150>
Well, it’s a little sloppy, but that’s plausibly a number '5'. (This is reasonable to expect from a hand-written digit!).
So it looks like each item in the dataset is a tuple containing an image (in tensor format) and its corresponding label.
Let’s use Matplotlib to look at the first 10 images, and title each image with its corresponding label:
fig, axs = plt.subplots(2, 5, figsize=(8, 5)) for a_row in range(2): for a_col in range(5): img_no = a_row*5 + a_col img = mnist_data[img_no][0].squeeze() img_tgt = mnist_data[img_no][1] axs[a_row][a_col].imshow(img, cmap='gray') axs[a_row][a_col].set_xticks([]) axs[a_row][a_col].set_yticks([]) axs[a_row][a_col].set_title(img_tgt, fontsize=20) plt.show()
So now we have a clear understanding of how our dataset is structured and what the data looks like. Much of this is explained in the dataset description page, but this kind of analysis is often very useful for getting a precise understanding of the dataset that might not be clear from the description.
Step 4: Create Dataloaders

Datasets make the data available for processing.
However, typically, we will want to process using randomized mini-batches from the dataset.
Data loaders make this easy. Dataloaders are iterables, and you’ll see later that every time you iterate a dataloader it returns a randomized minibatch from the dataset that can be processed through the neural network.
Let’s create some dataloader objects from our datasets:
batch_size = 100 mnist_train_dl = DataLoader(mnist_data, batch_size=batch_size, shuffle=True) mnist_test_dl = DataLoader(mnist_test_data, batch_size=batch_size, shuffle=True)
So we have created two data loaders, one for the training dataset, and one for the test dataset.
The batch_size parameter specifies the number of image/label pairs in the minibatch that the dataloader will return for each iteration. The shuffle parameter determines whether or not the mini-batches are randomized.
Step 5: Design and Create the Neural Network

Check for GPU
We are about to design and create the neural network, but first, let’s check if a GPU is available.
One of the advantages PyTorch has as a neural network framework is that it supports the use of a GPU. The use of a GPU will implement parallel processing to greatly speed up computation.
Depending on the problem, at least an order of magnitude faster processing can be achieved.
Use of a GPU with PyTorch is very easy. First, use the function torch.cuda.is_available() to test if a GPU is available and properly configured for use by PyTorch (PyTorch uses the CUDA framework for using the GPU).
If a GPU is available, we will send the model and the data tensors to the GPU for processing.
The following tests for availability of a GPU, then sets a variable device to either 'cpu' or 'cuda' depending on what is available.
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
# Using cuda device
Create the Neural Network
Now let’s design and create the neural network. We do this by creating a class, which we have chosen to call NeuralNet, which is a subclass of the nn.Module library.
Here is the code to specify and then create our neural network:
class NeuralNet(nn.Module): def __init__(self): super().__init__() # Required to properly initialize class, ensures inheritance of the parent __init__() method self.flat_f = nn.Flatten() # Creates function to smartly flatten tensor self.neur_net = nn.Sequential( nn.Linear(28*28, 512), nn.ReLU(), nn.Linear(512, 256), nn.ReLU(), nn.Linear(256,10) ) def forward(self, x): x = self.flat_f(x) logits = self.neur_net(x) return logits model = NeuralNet().to(device)
There are a number of important details to review in this code.
First, our neural network definition class must have two methods included: an __init__() method, and a forward() method.
Classes in Python routinely include an __init__() method to initialize variables and other things in the object that is created. The class must also include a forward() method, which tells PyTorch how to process the data during the forward pass of the data.
Let’s go over each of these in more detail.
Creating the Model: __init__() Method
First, within the __init__() method note the super().__init__() command. When we create a subclass it inherits the parent class variables and methods.
However, when we write an __init__() method in the subclass, that overrides inheritance of the __init__() method from the parent class.
However there are features in the parent class’ __init__() that our class needs to inherit. The super()__.init__() command achieves this. In effect, it says “include the parent class __init__() within our child class”.
To make a long story short, this is necessary to properly initialize our child class, by including some things needed from the parent nn.Module class.
Next, note creating a function from the nn.Flatten() function. Even though our data is a 28×28 pixel two-dimensional image, the processing still works if we convert it into a one-dimensional vector, stacking row by row next to one another to form a 28×28 = 784 element vector (in fact making this change is a common choice).
The flatten() function achieves this. However, the standard flatten() (note the lower case 'f') function will flatten everything, turning a 100 image minibatch tensor of shape (100, 1, 28, 28) into a single vector of shape (78400).
Instead, if we create a function from the nn.Flatten() function (note the upper case 'F'), this is smart enough to know to eliminate the single-element dimension and merge the last two dimensions, resulting in a tensor of shape (100, 784), representing a list of 100 vectors of 784 elements.
Note: double-check to make sure your function is flattening properly. If not, the Flatten() function can include some parameters that specify which dimensions to flatten. See documentation for details.
The last thing we do in the __init__() method is specify the neural network structure using the nn.Sequential() function.
Here we list the neural network layers in sequence from beginning to end.
First, we list an input layer of 28×28=784 neurons, connecting through linear (weights * input + bias) connections to 512 neurons. These 512 neurons then pass data through a non-linear ReLU activation function layer.
Those signals then go through another linear layer connecting 512 neurons to 256 neurons. These signals then go through another ReLU activation function layer. Finally, the signals go through a final linear layer connecting the 256 neurons to 10 final output neurons.
'ReLU' stands for 'Rectified Linear Unit'. It is one of many non-linear activation functions which can be chosen.
It is defined as:
f(x) = x, if x>=0
else f(x) = 0Here is a graph of the ReLU function:

Creating the Model: forward() Method
The second required method for our class is the forward() method.
As mentioned the forward() method tells PyTorch how to process the data during the forward pass. Here we first flatten our tensor using the flatten function we defined previously under __init__().
Then we pass the tensor through the self.neur_net() function we defined previously using the nn.Sequential() function. Finally, the results are returned.
Important point: the programmer will NOT be using forward() method in any classes or functions, it is just for PyTorch’s use. PyTorch expects such a method, so it must be written, but the programmer will not directly use it in any subsequent code.
Finally, we create the neural network (here named 'model') by creating an instance of our NeuralNet() class. In addition, we move the model to the GPU (if available) by including the .to(device) method.
Finally, we can choose to print the model to examine the neural network object we have built:
print(model)
Output:
NeuralNet( (flat_f): Flatten(start_dim=1, end_dim=-1) (neur_net): Sequential( (0): Linear(in_features=784, out_features=512, bias=True) (1): ReLU() (2): Linear(in_features=512, out_features=256, bias=True) (3): ReLU() (4): Linear(in_features=256, out_features=10, bias=True) )
)Step 6: Choose Loss Function and Optimizer

Next, we’ll need to specify our loss function and our optimizer algorithm.
Choosing Cross Entropy Loss
Recall the loss function measures how far the model’s guess is from the correct answer for a given input. Adjusting weights and biases to minimize loss is how neural networks learn (see the Finxter article “How Neural Networks Learn” for details.).
There are multiple choices of loss functions available, and learning about these various functions is something you will want to do, because which loss choice is most suitable depends on the particular kind of problem you are solving.
In this case, we are sorting images into multiple categories.
One of the most suitable loss choices for this case is cross-entropy loss. Cross entropy is an idea taken from information theory, and it is a measure of how many extra bits must be sent when sending a message using a sub-optimized code.
This is beyond the scope of this exercise, but we can understand its usefulness to our situation if we examine the calculation involved:
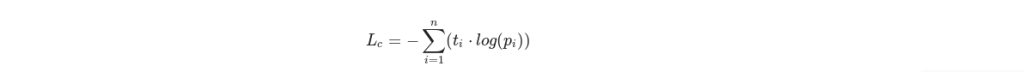
That is, for each category multiply the true probability t by the log of the model’s estimated probability p, and add them all up.
Of course, t is zero for each incorrect category, and 1 for the correct category.
Consequently, for any given image, just the correct category is selected to contribute to the loss calculation, and that loss is the negative of the log of the probability estimate.
Recall this is what the log() function looks like:

Since the network provides a probability estimate we are only interested in the interval (0,1]. Here is what the negative of the log() looks like over that interval:

So the loss is very large when the network gives a low probability estimate (near zero) for the correct category, and the loss is lowest (near zero) when the network gives a high probability estimate (near 1.0) for the correct category.
Here is the code specifying cross entropy loss as the loss function:
loss_fn = nn.CrossEntropyLoss()
Choosing Optimizer Algorithm
We also need to choose the optimizer algorithm. This is the method used to minimize the loss through training. Multiple different optimizers may be chosen, and you will want to learn about the various optimizers available.
All are variations on gradient descent.
For example, some include extinction of the learning rate; others include momentum that helps drive loss away from local minima.
In our case, we will choose plain-old vanilla stochastic gradient descent. Here is the code specifying the optimizer and its learning rate:
learning_rate = 1e-3 optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
Step 7: Specify Training and Testing Functions

Now we define functions for training and testing the neural network.
Training Function
Here is the code specifying the training function:
def train_nn(dataloader, model, loss_fn, optimizer): size = len(dataloader.dataset) for batch, (X, y) in enumerate(dataloader): X, y = X.to(device), y.to(device) # For each image in batch X, compute prediction pred = model(X) # Compute average loss for the set of images in batch loss = loss_fn(pred, y) # Backpropagation optimizer.zero_grad() # Zero gradients loss.backward() # Computes gradients optimizer.step() # Update weights, biases according to gradients, factored by learning rate if batch % 100 == 0: # Report progress every 100 batches loss, current = loss.item(), batch * len(X) print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
We pass into the function the dataloader, model, loss function, and optimizer objects.
The function then loops over minibatches from the dataloader.
For each loop, a minibatch of the input images X and the labels y is retrieved and then moved to the GPU (if available).
Then the neural network model calculates predictions from the input images X. These predictions and the correct labels y are used to calculate the loss (note this loss is a single number that is the average loss for the minibatch).
Once the loss is calculated, the function can adjust weights and biases (backpropagate) in three code steps.
First, gradient attributes are zeroed out using optimizer.zero_grad() (PyTorch defaults to accumulating gradient calculations, so they need to be zeroed out on each iteration of the loop, or else they’ll keep accumulating data).
Then the gradients are calculated using loss.backward(). Finally, weights and biases are updated according to the gradients using optimizer.step().
Finally, a small section is included to report progress every 100 batches. This prints out the current loss, and how many images of the total images have been completed.
Testing Function
Here is the code specifying the testing function:
def test_loop(dataloader, model, loss_fn): # After each epoch, test training results (report categorizing accuracy, loss) size = len(dataloader.dataset) # Number of image/label pairs in dataset num_batches = len(dataloader) test_loss, correct = 0, 0 # Initialize variables tracking loss and accuracy during test loop with torch.no_grad(): # Disable gradient tracking - reduces resource use and speeds up processing for X, y in dataloader: X, y = X.to(device), y.to(device) pred = model(X) # Get predictions from the neural network based on input minibatch X test_loss += loss_fn(pred, y).item() # Accumulate loss values during loop through dataset correct += (pred.argmax(1) == y).type(torch.float).sum().item() # Accumulate correct predictions during loop through dataset test_loss /= num_batches # Calculate average loss correct /= size # Calculate accuracy rate print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n") # Report test results
This function tests the accuracy of the network using the test data.
First, we pass in the testing data loader, the model, and the loss function (for testing loss). Then the function initializes several variables, especially test_loss and correct for accumulating test results during the test loop.
The function does the next few steps within a with torch.no_grad(): subsection.
Here is why: PyTorch stores calculations from the forward pass for later use during the backpropagation gradient calculations.
The torch.no_grad() method turns that off while in this with subsection, since there will be only a forward pass during the testing. This saves resources and speeds up processing. You will want to do the same thing once you have a trained network that is used for classifying in production.
After leaving the with subsection the calculation-storing feature automatically resumes.
Note: be aware that storing calculations is turned on (requires_grad=True) because we are using Modules from the nn library (Linear, ReLU). Otherwise, PyTorch tensors default to requires_grad=False.
Then the function uses a for loop to iterate through the minibatches of the test dataloader. For each iteration, the neural network model computes predictions from the minibatch of images. The loss is calculated for the minibatch, which is then accumulated in test_loss.
Then the number of correct predictions for the minibatch is found as follows: first note that pred is a set of 10-element vectors, with each element an estimate of the probability of that element index being the correct prediction.
The .argmax(1) method returns the index of the largest estimate (the number 1 in the argmax() argument indicates which dimension to use for the operation). This list (tensor) of indices is compared to the list (tensor) of correct labels in y.
This results in a list (tensor) containing True where there is a match, and False otherwise. The type(torch.float) method converts these into floating point 1’s and 0’s.
The sum() method adds all the elements together. Then finally, the .item() method converts the totaled one-element tensor into a raw number (scalar).
Finally, we have the total number of correct predictions for that batch, which is added to the correct variable that accumulates the total number of correct predictions as the for loop iterates through the dataloader.
Train and Test the Network
Now we have written enough code, we can write a small main program loop to train and test the network. We specify how many epochs we wish to run, then we loop through those epochs, training and testing the network for each one.
Here is the code:
# The main program! epochs = 5
for t in range(epochs): print(f"Epoch {t+1}\n-------------------------------") train_nn(mnist_train_dl, model, loss_fn, optimizer) test_loop(mnist_test_dl, model, loss_fn)
print("Done!")
Output:
Epoch 1 ------------------------------- loss: 2.102096 [ 0/60000] loss: 2.119211 [10000/60000] loss: 2.068424 [20000/60000] loss: 2.056982 [30000/60000] loss: 2.028877 [40000/60000] loss: 1.995214 [50000/60000] Test Error: Accuracy: 65.9%, Avg loss: 2.000194 Epoch 2 ------------------------------- loss: 2.018245 [ 0/60000] loss: 1.996478 [10000/60000] loss: 1.969913 [20000/60000] loss: 1.999372 [30000/60000] loss: 1.944238 [40000/60000] loss: 1.863184 [50000/60000] Test Error: Accuracy: 67.8%, Avg loss: 1.866808 Epoch 3 ------------------------------- loss: 1.921477 [ 0/60000] loss: 1.891367 [10000/60000] loss: 1.840778 [20000/60000] loss: 1.751534 [30000/60000] loss: 1.718531 [40000/60000] loss: 1.800236 [50000/60000] Test Error: Accuracy: 69.5%, Avg loss: 1.695623 Epoch 4 ------------------------------- loss: 1.692079 [ 0/60000] loss: 1.752511 [10000/60000] loss: 1.600570 [20000/60000] loss: 1.582768 [30000/60000] loss: 1.532521 [40000/60000] loss: 1.569566 [50000/60000] Test Error: Accuracy: 71.9%, Avg loss: 1.498120 Epoch 5 ------------------------------- loss: 1.507337 [ 0/60000] loss: 1.515740 [10000/60000] loss: 1.437465 [20000/60000] loss: 1.424620 [30000/60000] loss: 1.409456 [40000/60000] loss: 1.385026 [50000/60000] Test Error: Accuracy: 74.6%, Avg loss: 1.300192 Done!
After just 5 epochs, the accuracy isn’t very good yet, but we can see that things are moving in the right direction.
Obviously, if we wanted to get good performance we would need to train for more epochs. Figuring out how much to train (being careful not to overfit!) is something a neural network engineer has to work out.
Reviewing the Big Picture
It may seem like we have gone over a lot, and we have, but if you step back and look at the big picture there isn’t a lot here.
It may seem like a lot because we have reviewed everything in detail to make sure we convey full understanding.
However, to gain some perspective, let’s show all the essential code, without all the extra description and explanation (note, we’re also skipping the code here used to review the dataset):
Import Necessary Libraries
import torch from torch import nn from torchvision import datasets from torch.utils.data import DataLoader from torchvision.transforms import ToTensor
Acquire the Data
# Download MNIST data, put it in pytorch dataset mnist_data = datasets.MNIST( root='mnist_nn', train=True, download=True, transform=ToTensor() )
mnist_test_data = datasets.MNIST( root='mnist_nn', train=False, download=True, transform=ToTensor() )
Create Dataloaders
batch_size = 100 mnist_train_dl = DataLoader(mnist_data, batch_size=batch_size, shuffle=True) mnist_test_dl = DataLoader(mnist_test_data, batch_size=batch_size, shuffle=True)
Check for GPU
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
# Using cuda device
Design and Create the Neural Network
class NeuralNet(nn.Module): def __init__(self): super().__init__() # Required to properly initialize class, ensures inheritance of the parent __init__() method self.flat_f = nn.Flatten() # Creates function to smartly flatten tensor self.neur_net = nn.Sequential( nn.Linear(28*28, 512), nn.ReLU(), nn.Linear(512, 256), nn.ReLU(), nn.Linear(256,10) ) def forward(self, x): x = self.flat_f(x) logits = self.neur_net(x) return logits model = NeuralNet().to(device)
Choose Loss Function and Optimizer
loss_fn = nn.CrossEntropyLoss() learning_rate = 1e-3 optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
Specify Training and Testing Functions
def train_nn(dataloader, model, loss_fn, optimizer): size = len(dataloader.dataset) for batch, (X, y) in enumerate(dataloader): X, y = X.to(device), y.to(device) # For each image in batch X, compute prediction pred = model(X) # Compute average loss for the set of images in batch loss = loss_fn(pred, y) # Backpropagation optimizer.zero_grad() # Zero gradients loss.backward() # Computes gradients optimizer.step() # Update weights, biases according to gradients, factored by learning rate if batch % 100 == 0: # Report progress every 100 batches loss, current = loss.item(), batch * len(X) print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
def test_loop(dataloader, model, loss_fn): # After each epoch, test training results (report categorizing accuracy, loss) size = len(dataloader.dataset) # Number of image/label pairs in dataset num_batches = len(dataloader) test_loss, correct = 0, 0 # Initialize variables tracking loss and accuracy during test loop with torch.no_grad(): # Disable gradient tracking - reduces resource use and speeds up processing for X, y in dataloader: X, y = X.to(device), y.to(device) pred = model(X) # Get predictions from the neural network based on input minibatch X test_loss += loss_fn(pred, y).item() # Accumulate loss values during loop through dataset correct += (pred.argmax(1) == y).type(torch.float).sum().item() # Accumulate correct predictions during loop through dataset test_loss /= num_batches # Calculate average loss correct /= size # Calculate accuracy rate print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n") # Report test results
Train and Test the Network
# The main program! epochs = 5
for t in range(epochs): print(f"Epoch {t+1}\n-------------------------------") train_nn(mnist_train_dl, model, loss_fn, optimizer) test_loop(mnist_test_dl, model, loss_fn)
print("Done!")
Really we have written just a few dozen lines of code, comparable to the size program a hobbyist programmer might write.
Yet we’ve built a world-class neural network that converts hand-written digits to numbers a computer can work with. That’s pretty amazing!
Of course, this is all possible thanks to the efforts of the many engineers who wrote the many more lines of code within PyTorch. Thank you to all of you who have contributed to PyTorch!
This is another example of achieving great things by standing on the shoulders of giants!
Saving and Reloading the Network
We have built, trained, and tested a neural network, and that’s great. But really, the point of training a neural network is to put it to use. To support that, we need to be able to save and reload the network for later use.
Use the following code to save the weights and biases of your neural network (note: the common convention is to save these files with extension .pt or .pth):
torch.save(network_name.state_dict(), 'filename.pth')
Since we named our network model we would save as follows:
torch.save(model.state_dict(), 'model_weights.pth')
To reload, first create an instance of your neural network (make sure you have access to the class/neural network you originally specified). In our example:
user_model = NeuralNet().to(device)
Then load the new instance with your saved weights and biases:
user_model.load_state_dict(torch.load('model_weights.pth'))
# <All keys matched successfully>
Some of the modules perform differently when in training rather than when in use.
Specifically, when in training mode, some of them implement various regularization methods which are used to resist the onset of overfitting.
These methods may include some randomness and can cause the network to give inconsistent results. To avoid this, make sure you are in evaluation mode and not training mode:
user_model.eval()
Output:
NeuralNet( (flat_f): Flatten(start_dim=1, end_dim=-1) (neur_net): Sequential( (0): Linear(in_features=784, out_features=512, bias=True) (1): ReLU() (2): Linear(in_features=512, out_features=256, bias=True) (3): ReLU() (4): Linear(in_features=256, out_features=10, bias=True) ) )
As you can see this command conveniently reports the neural network structure.
Let’s make sure our reloaded network works.
It would be best to test with some new handwritten digits, but for the sake of convenience lets just test it with the first ten test images (especially since the network was not trained very heavily).
Let’s look at these first ten images in the test dataset:
fig, axs = plt.subplots(2, 5, figsize=(8, 5)) for a_row in range(2): for a_col in range(5): img_no = a_row*5 + a_col img = mnist_test_data[img_no][0].squeeze() img_tgt = mnist_test_data[img_no][1] axs[a_row][a_col].imshow(img, cmap='gray') axs[a_row][a_col].set_xticks([]) axs[a_row][a_col].set_yticks([]) axs[a_row][a_col].set_title(img_tgt, fontsize=20) plt.show()
Now let’s see if the network detects these images properly:
def eval_image(model, imgno): testimg = mnist_test_data[imgno][0] # assign first image to variable 'testimg' testimg = testimg.to(device) # move image data to GPU logits = model(testimg) # run image through network return logits.argmax().item() # argmax id's value, returns it for img_no in range(10): img_val = eval_image(model, img_no) print(img_val)
Output:
7
2
1
0
4
1
7
9
6
7
The results are not perfect, but for an incompletely trained network that’s not bad! The few failure are plausible given the incomplete training. Our network works with the saved and reloaded weights and biases!
Conclusion
We hope you have found this article educational, and we hope it inspires you to go and build your own working neural networks using PyTorch!
















 Note: It is suggested to avoid
Note: It is suggested to avoid 

 Prev Tutorial
Prev Tutorial Syllabus
Syllabus Next Tutorial
Next Tutorial Note: There is more than one kit out there, but it is this author’s opinion that the best value for beginners is the one from UCTRONICS. Most of them have similar components, but this one just happens to be my go-to and is the subject of this installment.
Note: There is more than one kit out there, but it is this author’s opinion that the best value for beginners is the one from UCTRONICS. Most of them have similar components, but this one just happens to be my go-to and is the subject of this installment.


















 Question: How would we write code to read in and extract data from an
Question: How would we write code to read in and extract data from an 














 Attention: This module is depreciated, you may want to install
Attention: This module is depreciated, you may want to install