Last modified on January 9th, 2020 by Vincy.
A contact form on a website is a medium to the users to contact the site admin or maintainer. It acts as a medium of communication. For many a websites, it is a critical factor in getting a sale.
The Captcha in a form is a mechanism to prevent bots or malicious users from submitting the form. It protects the site from security abuses.
There are components available in the market to render captcha in a form. Google reCAPTCHA is a popular and unbeatable service to make your form captcha-enabled.
- Different websites use different types of captcha.
- Displaying random alpha-numeric characters.
- Requesting to solve puzzles, Google reCAPTCHA-like image captcha.
I created an example code for a contact form in PHP with the reCAPTCHA-like image captcha mechanism.

What is inside?
- Existing contact form component
- About this example
- File structure
- HTML code to show contact form with image captcha
- PHP code to validate image captcha and send contact mail
- Contact form captcha image database script
- Contact form output with custom image captcha
Ready-made contact form components are existing huge in number around the web. If you want to get one among them, then we need to be sure about the security and robustness of the code.
I have created a secure spam-free contact form script, Iris. I coded this component to easily integrate and configure with your application. If you are looking for a contact form that controls spam without using a captcha, then you will like it.
This also component includes Google reCAPTCHA. You can enable or disable this feature on a need basis. In similar ways, it comes with loads of features that is configurable in minutes.
About this example
This example code has the Name, Email, Subject and Message fields. These are some basic fields that we have seen with other PHP contact form example earlier.
Added to these fields, I have added an image captcha section in this code. This section will show five random images and ask to choose one. The random images are from the database.
I used jQuery script to validate the form field data before posting it to the PHP.
In PHP, it validates the captcha image clicked by the user. Based on the server-side captcha validation, the PHP will respond to the user.
File structure
The PHP contact form with an image captcha example includes less number of files.
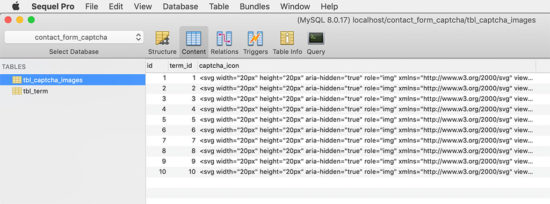
The file structure is in the below screenshot. You can see that it has a systematic code with a conventional structure.
This code snippet shows the HTML part of the index.php, the landing page.
This contact form contains some basic fields with custom captcha in PHP.
The captcha section shows the SVG image markup from the database. It displays five random images and requests the user to select one.
The HTML form has the specification of a jQuery validation handler. The form-submit event will invoke this handler to process the form validation.
This HTML includes the response containers to display notifications to the user. These notifications acknowledge the user about the captcha validation or other responses.
index.php (contact form HTML)
<html> <head> <title>Contact Us Form</title> <link rel="stylesheet" type="text/css" href="assets/css/contact-form-style.css" /> <link rel="stylesheet" type="text/css" href="assets/css/phppot-style.css" /> <script src="vendor/jquery/jquery-3.2.1.min.js"></script> </head> <body> <div class="phppot-container"> <h1>PHP contact form with captcha images</h1> <form name="frmContact" id="captcha-cnt-frm" class="phppot-form" frmContact"" method="post" action="" enctype="multipart/form-data" onsubmit="return validateContactForm()"> <div class="phppot-row"> <div class="label"> Name <span id="userName-info" class="validation-message"></span> </div> <input type="text" class="phppot-input" name="userName" id="userName" value="<?php if(!empty($_POST['userName'])&& $type == 'error'){ echo $_POST['userName'];}?>" /> </div> <div class="phppot-row"> <div class="label"> Email <span id="userEmail-info" class="validation-message"></span> </div> <input type="text" class="phppot-input" name="userEmail" id="userEmail" value="<?php if(!empty($_POST['userEmail'])&& $type == 'error'){ echo $_POST['userEmail'];}?>" /> </div> <div class="phppot-row"> <div class="label"> Subject <span id="subject-info" class="validation-message"></span> </div> <input type="text" class="phppot-input" name="subject" id="subject" value="<?php if(!empty($_POST['subject'])&& $type == 'error'){ echo $_POST['subject'];}?>" /> </div> <div class="phppot-row"> <div class="label"> Message <span id="userMessage-info" class="validation-message"></span> </div> <textarea name="content" id="content" class="phppot-input" cols="60" rows="6"><?php if(!empty($_POST['content'])&& $type == 'error'){ echo $_POST['content'];}?></textarea> </div> <?php if (! empty($result)) { ?> <div class="phppot-row"> <div class="captcha-container <?php if(!empty($border)){ echo $border;} ?>"> <p> Select the <span class="text-color"><?php echo $result[0]['name'];?> </span><span id="captcha-info" class="validation-message"></span> </p> <input type="hidden" name="captcha_code" value="<?php echo $result[0]['name'];?>"> <?php shuffle($captchaOutput); if (! empty($captchaOutput)) { foreach ($captchaOutput as $value) { ?> <div class="svg-padding"> <div class="svg"><?php echo $value['captcha_icon'];?> <input type="hidden" class="icons" value="<?php echo $value['name'];?>"> </div> </div> <?php }}?> </div> </div> <?php }?> <div class="phppot-row"> <input type="submit" name="send" class="send-button" value="Send" /> </div> <input type="hidden" name="captcha_chosen" id="captcha-chosen" value=""> </form> <?php if(!empty($message)) { ?> <div id="phppot-message" class="<?php echo $type; ?>"><?php if(isset($message)){ ?> <?php echo $message; }}?> </div> </div> <script src="assets/js/captcha.js"></script> </body> </html>
jQuery script to validate contact form and highlight captcha selection
This section shows the jQuery script for validation and captcha selection.
The validateContactForm() function is handling the form validation. All the contact form fields are mandatory. This function is making sure about the non-empty state of the form fields.
On selecting one of the lists of captcha images, the script puts the selected value in a form field. Also, it highlights the selected by adding CSS via script.
If the user selects no captcha, then the validation will return false.
assets/js/captcha.js
function validateContactForm() { var valid = true; $("#userName").removeClass("error-field"); $("#userEmail").removeClass("error-field"); $("#subject").removeClass("error-field"); $("#content").removeClass("error-field"); $("#userName-info").html("").hide(); $("#userEmail-info").html("").hide(); $("#subject-info").html("").hide(); $("#content-info").html("").hide(); $(".validation-message").html(""); $(".phppot-input").css('border', '#e0dfdf 1px solid'); $(".captcha-container").css('border', '#e0dfdf 1px solid'); var userName = $("#userName").val(); var userEmail = $("#userEmail").val(); var subject = $("#subject").val(); var content = $("#content").val(); var captcha = $("#captcha-chosen").val(); if (userName.trim() == "") { $("#userName-info").html("required.").css("color", "#ee0000").show(); $("#userName").css('border', '#e66262 1px solid'); $("#userName").addClass("error-field"); valid = false; } if (userEmail.trim() == "") { $("#userEmail-info").html("required.").css("color", "#ee0000").show(); $("#userEmail").css('border', '#e66262 1px solid'); $("#userEmail").addClass("error-field"); valid = false; } if (!userEmail.match(/^([\w-\.]+@([\w-]+\.)+[\w-]{2,4})?$/)) { $("#userEmail-info").html("invalid email address.").css("color", "#ee0000").show(); $("#userEmail").css('border', '#e66262 1px solid'); $("#userEmail").addClass("error-field"); valid = false; } if (subject == "") { $("#subject-info").html("required.").css("color", "#ee0000").show(); $("#subject").css('border', '#e66262 1px solid'); $("#subject").addClass("error-field"); valid = false; } if (content == "") { $("#userMessage-info").html("required.").css("color", "#ee0000").show(); $("#content").css('border', '#e66262 1px solid'); $("#content").addClass("error-field"); valid = false; } if (captcha == "") { $("#captcha-info").html("required."); $(".captcha-container").css('border', '#e66262 1px solid'); valid = false; } if (valid == false) { $('.error-field').first().focus(); valid = false; } return valid; } $(".svg-padding").on('click', function() { $(".svg").removeClass('captcha-selected'); $(this).find(".svg").addClass('captcha-selected'); var icons = $(this).find(".icons").val(); $("#captcha-chosen").val(icons); });
CSS created for contact form example
These are the exclusive styles created to present the contact form. Mostly, it contains styles for the captcha section.
I used a generic CSS template for designing other common form components. You can find this CSS in the downloadable.
assets/css/contact-form-style.css
.svg-padding { display: inline-block; } .svg { cursor: pointer; padding: 5px 5px 5px 5px; border-radius: 3px; margin: 0px 5px 0px 5px; border: 1px solid #FFF; } .text-color { font-weight: bold; } .captcha-container { background: #fff; padding: 15px; border: 1px solid #9a9a9a; width: 270px; border-radius: 3px; padding-top: 0px; } .error-field { border: 1px solid #d96557; } .send-button { cursor: pointer; background: #3cb73c; border: #36a536 1px solid; color: #FFF; font-size: 1em; width: 100px; } .captcha-selected { color: #1cb87b; background-color: #e3e3e3; border: #d7d7d7 1px solid; } .border-error-color { border: 1px solid #e66262; }
On loading the contact form, the PHP code reads the random captcha images from the database. In PHP, it picks one image from the random results as the captcha code.
The HTML form contains a hidden field to have this code.
When the user selects an image and posts it to the PHP, it will validate the selected captcha.
The user-selected captcha is matched with the pre-loaded code, then the PHP code will return true. Then, it will process the contact email sending script.
index.php (Captcha Validation and Mail sending)
<?php namespace Phppot; require_once ("Model/Contact.php"); $contact = new Contact(); if (! empty($_POST['send'])) { if ($_POST['captcha_code'] == $_POST['captcha_chosen']) { $contact->sendContactMail($_POST); $message = "Hi, we have received your message. Thank you."; $type = "success"; } else { $message = "Invalid captcha. Please select the correct image."; $type = "error"; $border = "border-error-color"; } } $result = $contact->getRecord(); $termId = $result[0]['id']; $captchaResult = $contact->getCaptchaIcons($termId); $randomCaptchaResult = $contact->getRandomCaptchaId($termId); $captchaOutput = array_merge($captchaResult, $randomCaptchaResult); ?>
In this PHP model class, it has the functions to read random captcha images from the database.
The getRecord() method reads a single random record to load captcha code on the page load.
The sendContactMail() function send the contact mail. I used PHP mail() function for this example. If you want to use SMTP for sending the email, you can see the example in the linked article.
Model/Contact.php
<?php namespace Phppot; use Phppot\DataSource; class Contact { private $ds; function __construct() { require_once __DIR__ . './../lib/DataSource.php'; $this->ds = new DataSource(); } function getRecord() { $query = "SELECT * FROM tbl_term ORDER BY RAND() LIMIT 1"; $result = $this->ds->select($query); return $result; } function getCaptchaIcons($id) { $query = "SELECT tbl_captcha_images.*, tbl_term.name FROM tbl_captcha_images JOIN tbl_term ON tbl_captcha_images.term_id = tbl_term.id WHERE term_id != " . $id . " ORDER BY RAND() LIMIT 4"; $captchaResult = $this->ds->select($query); return $captchaResult; } function getRandomCaptchaId($id) { $query = "SELECT tbl_captcha_images.*, tbl_term.name FROM tbl_captcha_images JOIN tbl_term ON tbl_captcha_images.term_id = tbl_term.id WHERE term_id = " . $id . " ORDER BY RAND() LIMIT 1"; $captcha = $this->ds->select($query); return $captcha; } function sendContactMail($postValues) { $name = $postValues["userName"]; $email = $postValues["userEmail"]; $subject = $postValues["subject"]; $content = $postValues["content"]; $toEmail = "SITE_ADMIN_EMAIL"; // Put in place the recipient email $mailHeaders = "From: " . $name . "<" . $email . ">\r\n"; mail($toEmail, $subject, $content, $mailHeaders); } }
lib/Datasource.php
<?php namespace Phppot; /** * Generic datasource class for handling DB operations. * Uses MySqli and PreparedStatements. * * @version 2.3 */ class DataSource { // PHP 7.1.0 visibility modifiers are allowed for class constants. // when using above 7.1.0, declare the below constants as private const HOST = 'localhost'; const USERNAME = 'root'; const PASSWORD = ''; const DATABASENAME = 'contact_form_captcha'; private $conn; /** * PHP implicitly takes care of cleanup for default connection types. * So no need to worry about closing the connection. * * Singletons not required in PHP as there is no * concept of shared memory. * Every object lives only for a request. * * Keeping things simple and that works! */ function __construct() { $this->conn = $this->getConnection(); } /** * If connection object is needed use this method and get access to it. * Otherwise, use the below methods for insert / update / etc. * * @return \mysqli */ public function getConnection() { $conn = new \mysqli(self::HOST, self::USERNAME, self::PASSWORD, self::DATABASENAME); if (mysqli_connect_errno()) { trigger_error("Problem with connecting to database."); } $conn->set_charset("utf8"); return $conn; } /** * To get database results * * @param string $query * @param string $paramType * @param array $paramArray * @return array */ public function select($query, $paramType = "", $paramArray = array()) { $stmt = $this->conn->prepare($query); if (! empty($paramType) && ! empty($paramArray)) { $this->bindQueryParams($stmt, $paramType, $paramArray); } $stmt->execute(); $result = $stmt->get_result(); if ($result->num_rows > 0) { while ($row = $result->fetch_assoc()) { $resultset[] = $row; } } if (! empty($resultset)) { return $resultset; } } }
This SQL script includes the structure and data of the tables used to display custom captcha. The tbl_captcha_images table contains the SVG markup of the captcha images.
I have used another table tbl_term to hold the captcha term and title. The captcha term is for stating the user what to select. The captcha title is a slug to add it with a title attribute.
sql/contact_form_captcha.sql
-- -- Database: `contact_form_captcha` -- -- -------------------------------------------------------- -- -- Table structure for table `tbl_captcha_images` -- CREATE TABLE `tbl_captcha_images` ( `id` int(11) NOT NULL, `term_id` int(11) NOT NULL, `captcha_icon` text NOT NULL ) ENGINE=InnoDB DEFAULT CHARSET=latin1; -- -- Dumping data for table `tbl_captcha_images` -- INSERT INTO `tbl_captcha_images` (`id`, `term_id`, `captcha_icon`) VALUES (1, 1, '<svg width=\"25px\" height=\"25px\" aria-hidden=\"true\" role=\"img\" xmlns=\"http://www.w3.org/2000/svg\" viewBox=\"0 0 640 512\"><path fill=\"currentColor\" d=\"M192 384h192c53 0 96-43 96-96h32c70.6 0 128-57.4 128-128S582.6 32 512 32H120c-13.3 0-24 10.7-24 24v232c0 53 43 96 96 96zM512 96c35.3 0 64 28.7 64 64s-28.7 64-64 64h-32V96h32zm47.7 384H48.3c-47.6 0-61-64-36-64h583.3c25 0 11.8 64-35.9 64z\"></path></svg>'), (2, 2, '<svg width=\"25px\" height=\"25px\" aria-hidden=\"true\" role=\"img\" xmlns=\"http://www.w3.org/2000/svg\" viewBox=\"0 0 576 512\"><path fill=\"currentColor\" d=\"M259.3 17.8L194 150.2 47.9 171.5c-26.2 3.8-36.7 36.1-17.7 54.6l105.7 103-25 145.5c-4.5 26.3 23.2 46 46.4 33.7L288 439.6l130.7 68.7c23.2 12.2 50.9-7.4 46.4-33.7l-25-145.5 105.7-103c19-18.5 8.5-50.8-17.7-54.6L382 150.2 316.7 17.8c-11.7-23.6-45.6-23.9-57.4 0z\"></path></svg>'), (3, 3, '<svg width=\"25px\" height=\"25px\" aria-hidden=\"true\" role=\"img\" xmlns=\"http://www.w3.org/2000/svg\" viewBox=\"0 0 384 512\"><path fill=\"currentColor\" d=\"M377.33 375.429L293.906 288H328c21.017 0 31.872-25.207 17.448-40.479L262.79 160H296c20.878 0 31.851-24.969 17.587-40.331l-104-112.003c-9.485-10.214-25.676-10.229-35.174 0l-104 112.003C56.206 134.969 67.037 160 88 160h33.21l-82.659 87.521C24.121 262.801 34.993 288 56 288h34.094L6.665 375.429C-7.869 390.655 2.925 416 24.025 416H144c0 32.781-11.188 49.26-33.995 67.506C98.225 492.93 104.914 512 120 512h144c15.086 0 21.776-19.069 9.995-28.494-19.768-15.814-33.992-31.665-33.995-67.496V416h119.97c21.05 0 31.929-25.309 17.36-40.571z\"></path></svg>'), (4, 4, '<svg width=\"25px\" height=\"25px\" aria-hidden=\"true\" role=\"img\" xmlns=\"http://www.w3.org/2000/svg\" viewBox=\"0 0 640 512\"><path fill=\"currentColor\" d=\"M624 352h-16V243.9c0-12.7-5.1-24.9-14.1-33.9L494 110.1c-9-9-21.2-14.1-33.9-14.1H416V48c0-26.5-21.5-48-48-48H48C21.5 0 0 21.5 0 48v320c0 26.5 21.5 48 48 48h16c0 53 43 96 96 96s96-43 96-96h128c0 53 43 96 96 96s96-43 96-96h48c8.8 0 16-7.2 16-16v-32c0-8.8-7.2-16-16-16zM160 464c-26.5 0-48-21.5-48-48s21.5-48 48-48 48 21.5 48 48-21.5 48-48 48zm320 0c-26.5 0-48-21.5-48-48s21.5-48 48-48 48 21.5 48 48-21.5 48-48 48zm80-208H416V144h44.1l99.9 99.9V256z\"></path></svg>'), (5, 5, '<svg width=\"25px\" height=\"25px\" aria-hidden=\"true\" role=\"img\" xmlns=\"http://www.w3.org/2000/svg\" viewBox=\"0 0 512 512\"><path fill=\"currentColor\" d=\"M512 176.001C512 273.203 433.202 352 336 352c-11.22 0-22.19-1.062-32.827-3.069l-24.012 27.014A23.999 23.999 0 0 1 261.223 384H224v40c0 13.255-10.745 24-24 24h-40v40c0 13.255-10.745 24-24 24H24c-13.255 0-24-10.745-24-24v-78.059c0-6.365 2.529-12.47 7.029-16.971l161.802-161.802C163.108 213.814 160 195.271 160 176 160 78.798 238.797.001 335.999 0 433.488-.001 512 78.511 512 176.001zM336 128c0 26.51 21.49 48 48 48s48-21.49 48-48-21.49-48-48-48-48 21.49-48 48z\"></path></svg>'), (6, 6, '<svg width=\"25px\" height=\"25px\" aria-hidden=\"true\" role=\"img\" xmlns=\"http://www.w3.org/2000/svg\" viewBox=\"0 0 512 512\"><path fill=\"currentColor\" d=\"M499.991 168h-54.815l-7.854-20.944c-9.192-24.513-25.425-45.351-46.942-60.263S343.651 64 317.472 64H194.528c-26.18 0-51.391 7.882-72.908 22.793-21.518 14.912-37.75 35.75-46.942 60.263L66.824 168H12.009c-8.191 0-13.974 8.024-11.384 15.795l8 24A12 12 0 0 0 20.009 216h28.815l-.052.14C29.222 227.093 16 247.997 16 272v48c0 16.225 6.049 31.029 16 42.309V424c0 13.255 10.745 24 24 24h48c13.255 0 24-10.745 24-24v-40h256v40c0 13.255 10.745 24 24 24h48c13.255 0 24-10.745 24-24v-61.691c9.951-11.281 16-26.085 16-42.309v-48c0-24.003-13.222-44.907-32.772-55.86l-.052-.14h28.815a12 12 0 0 0 11.384-8.205l8-24c2.59-7.771-3.193-15.795-11.384-15.795zm-365.388 1.528C143.918 144.689 168 128 194.528 128h122.944c26.528 0 50.61 16.689 59.925 41.528L391.824 208H120.176l14.427-38.472zM88 328c-17.673 0-32-14.327-32-32 0-17.673 14.327-32 32-32s48 30.327 48 48-30.327 16-48 16zm336 0c-17.673 0-48 1.673-48-16 0-17.673 30.327-48 48-48s32 14.327 32 32c0 17.673-14.327 32-32 32z\"></path></svg>'), (7, 7, '<svg width=\"25px\" height=\"25px\" aria-hidden=\"true\" role=\"img\" xmlns=\"http://www.w3.org/2000/svg\" viewBox=\"0 0 576 512\"><path fill=\"currentColor\" d=\"M414.9 24C361.8 24 312 65.7 288 89.3 264 65.7 214.2 24 161.1 24 70.3 24 16 76.9 16 165.5c0 72.6 66.8 133.3 69.2 135.4l187 180.8c8.8 8.5 22.8 8.5 31.6 0l186.7-180.2c2.7-2.7 69.5-63.5 69.5-136C560 76.9 505.7 24 414.9 24z\"></path></svg>'), (8, 8, '<svg width=\"25px\" height=\"25px\" aria-hidden=\"true\" role=\"img\" xmlns=\"http://www.w3.org/2000/svg\" viewBox=\"0 0 576 512\"><path fill=\"currentColor\" d=\"M488 312.7V456c0 13.3-10.7 24-24 24H348c-6.6 0-12-5.4-12-12V356c0-6.6-5.4-12-12-12h-72c-6.6 0-12 5.4-12 12v112c0 6.6-5.4 12-12 12H112c-13.3 0-24-10.7-24-24V312.7c0-3.6 1.6-7 4.4-9.3l188-154.8c4.4-3.6 10.8-3.6 15.3 0l188 154.8c2.7 2.3 4.3 5.7 4.3 9.3zm83.6-60.9L488 182.9V44.4c0-6.6-5.4-12-12-12h-56c-6.6 0-12 5.4-12 12V117l-89.5-73.7c-17.7-14.6-43.3-14.6-61 0L4.4 251.8c-5.1 4.2-5.8 11.8-1.6 16.9l25.5 31c4.2 5.1 11.8 5.8 16.9 1.6l235.2-193.7c4.4-3.6 10.8-3.6 15.3 0l235.2 193.7c5.1 4.2 12.7 3.5 16.9-1.6l25.5-31c4.2-5.2 3.4-12.7-1.7-16.9z\"></path></svg>'), (9, 9, '<svg width=\"25px\" height=\"25px\" aria-hidden=\"true\" role=\"img\" xmlns=\"http://www.w3.org/2000/svg\" viewBox=\"0 0 512 512\"><path fill=\"currentColor\" d=\"M349.565 98.783C295.978 98.783 251.721 64 184.348 64c-24.955 0-47.309 4.384-68.045 12.013a55.947 55.947 0 0 0 3.586-23.562C118.117 24.015 94.806 1.206 66.338.048 34.345-1.254 8 24.296 8 56c0 19.026 9.497 35.825 24 45.945V488c0 13.255 10.745 24 24 24h16c13.255 0 24-10.745 24-24v-94.4c28.311-12.064 63.582-22.122 114.435-22.122 53.588 0 97.844 34.783 165.217 34.783 48.169 0 86.667-16.294 122.505-40.858C506.84 359.452 512 349.571 512 339.045v-243.1c0-23.393-24.269-38.87-45.485-29.016-34.338 15.948-76.454 31.854-116.95 31.854z\"></path></svg>'), (10, 10, '<svg width=\"25px\" height=\"25px\" aria-hidden=\"true\" role=\"img\" xmlns=\"http://www.w3.org/2000/svg\" viewBox=\"0 0 576 512\"><path fill=\"currentColor\" d=\"M472 200H360.211L256.013 5.711A12 12 0 0 0 245.793 0h-57.787c-7.85 0-13.586 7.413-11.616 15.011L209.624 200H99.766l-34.904-58.174A12 12 0 0 0 54.572 136H12.004c-7.572 0-13.252 6.928-11.767 14.353l21.129 105.648L.237 361.646c-1.485 7.426 4.195 14.354 11.768 14.353l42.568-.002c4.215 0 8.121-2.212 10.289-5.826L99.766 312h109.858L176.39 496.989c-1.97 7.599 3.766 15.011 11.616 15.011h57.787a12 12 0 0 0 10.22-5.711L360.212 312H472c57.438 0 104-25.072 104-56s-46.562-56-104-56z\"></path></svg>'); -- -------------------------------------------------------- -- -- Table structure for table `tbl_term` -- CREATE TABLE `tbl_term` ( `id` int(11) NOT NULL, `name` varchar(255) NOT NULL, `slug` varchar(255) NOT NULL ) ENGINE=InnoDB DEFAULT CHARSET=latin1; -- -- Dumping data for table `tbl_term` -- INSERT INTO `tbl_term` (`id`, `name`, `slug`) VALUES (1, 'cup', 'cup-1'), (2, 'star', 'star-2'), (3, 'tree', 'tree-3'), (4, 'truck', 'truck-4'), (5, 'key', 'key-5'), (6, 'car', 'car-6'), (7, 'heart', 'heart-7'), (8, 'house', 'house-8'), (9, 'flag', 'flag-9'), (10, 'plane', 'plane-10'); -- -- Indexes for dumped tables -- -- -- Indexes for table `tbl_captcha_images` -- ALTER TABLE `tbl_captcha_images` ADD PRIMARY KEY (`id`); -- -- Indexes for table `tbl_term` -- ALTER TABLE `tbl_term` ADD PRIMARY KEY (`id`); -- -- AUTO_INCREMENT for dumped tables -- -- -- AUTO_INCREMENT for table `tbl_captcha_images` -- ALTER TABLE `tbl_captcha_images` MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=11; -- -- AUTO_INCREMENT for table `tbl_term` -- ALTER TABLE `tbl_term` MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=11; COMMIT;
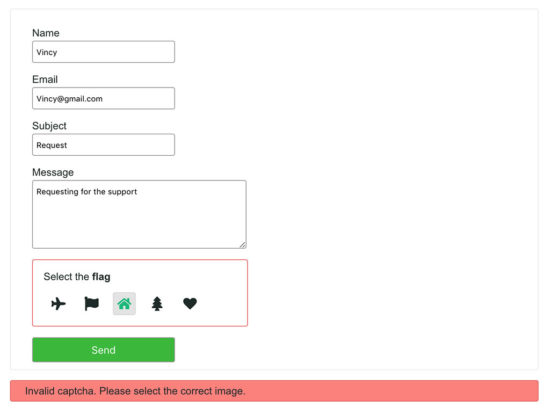
This screenshot shows the output of this PHP contact form example. It displays the custom image captcha in the form.
It focuses on the captcha section because of the form submitted with invalid captcha.
Download
Popular Articles
↑ Back to Top