Python’s built-in divmod(a, b) function takes two integer or float numbers a and b as input arguments and returns a tuple (a // b, a % b). The first tuple value is the result of the integer divisiona//b. The second tuple is the result of the remainder, also called modulo operationa % b. In case of float inputs, divmod() still returns the division without remainder by rounding down to the next round number.
Usage
Learn by example! Here are some examples of how to use the divmod()built-in function with integer arguments:
Syntax: divmod(a, b) -> returns a tuple of two numbers. The first is the result of the division without remainder a/b. The second is the remainder (modulo) a%b.
Arguments
integer
The dividend of the division operation.
integer
The divisor of the division operation.
Return Value
tuple
Returns a tuple of two numbers. The first is the result of the division without remainder. The second is the remainder (modulo).
Exercise: Guess the output before running the code.
But before we move on, I’m excited to present you my brand-new Python book Python One-Liners (Amazon Link).
If you like one-liners, you’ll LOVE the book. It’ll teach you everything there is to know about a single line of Python code. But it’s also an introduction to computer science, data science, machine learning, and algorithms. The universe in a single line of Python!
The book is released in 2020 with the world-class programming book publisher NoStarch Press (San Francisco).
You can generally use the divmod(a, b) function with two integers, one integer and one float, or two floats.
Two integers. Say you call divmod(a, b) with two integers a and b. In this case, the exact mathematical definition of the return value is (a // b, a % b).
a = 5
b = 2
print((a // b, a % b))
print(divmod(a, b))
# OUTPUT:
# (2, 1)
# (2, 1)
One integer and one float. Say you call divmod(a, b) with an integer a and a float b. In this case, the exact mathematical definition of the return value is the return value of converting the integer to a float and calling divmod(a, float(b)).
a = 5.0
b = 2
print((a // b, a % b))
print(divmod(a, b))
# OUTPUT:
# (2.0, 1.0)
# (2.0, 1.0)
Two floats. Say you call divmod(a, b) with two floats a and b. In this case, the exact mathematical definition of the return value is (float(math.floor(a / b)), a % b).
import math a = 5.0
b = 2.0
print((float(math.floor(a / b)), a % b))
print(divmod(a, b))
# OUTPUT:
# (2.0, 1.0)
# (2.0, 1.0)
Note that because of the imprecision of floating point arithmetic, the result may have a small floating point error in one of the lower decimal positions. You can read more about the floating point trap on the Finxter blog.
Can you use the divmod() method on negative numbers for the dividend or the divisor?
You can use divmod(a, b) for negative input arguments a, b, or both. In any case, if both arguments are integers, Python performs integer division a // b to obtain the first element and modulo division a % b to obtain the second element of the returned tuple. Both operations allow negative inputs a or b. The returned tuple (x, y) is calculated so that x * b + y = a.
Python divmod() Performance — Is It Faster Than Integer Division // and Modulo % Operators?
There are two semantically identical ways to create a tuple where the first element is the result of the integer division and the second is the result of the modulo operation:
Use the divmod(a, b) function.
Use the (a // b, a % b) explicit operation with Python built-in operators.
Next, we measure the performance of calculating the elapsed runtime in milliseconds when performing 10 million computations for relatively small integers. Let’s start with divmod():
import time
import random # Small Operands
operands = zip([random.randint(1, 100) for i in range(10**7)], [random.randint(1, 100) for i in range(10**7)]) start = time.time() for i, j in operands: divmod(i, j) stop = time.time()
print('divmod() elapsed time: ', (stop-start), 'milliseconds')
# divmod() elapsed time: 1.7654337882995605 milliseconds
Compare this to integer division and modulo:
import time
import random # Small Operands
operands = zip([random.randint(1, 100) for i in range(10**7)], [random.randint(1, 100) for i in range(10**7)]) start = time.time() for i, j in operands: (i // j, i % j) stop = time.time()
print('(i // j, i % j) elapsed time: ', (stop-start), 'milliseconds')
# (i // j, i % j) elapsed time: 1.9048900604248047 milliseconds
The result of this performance benchmark is that divmod() requires 1.76 milliseconds and the explicit way of using integer division and modulo requires 1.90 milliseconds for 10,000,000 operations. Thus, divmod() is 8% faster. The reason is that the explicit way performs many duplicate operations to calculate the result of the integer division and the modulo operation which internally uses integer division again. This effect becomes even more pronounced if you use larger integers.
Python divmod() Implementation
For integer input arguments, here’s a semantically equivalent divmod() implementation:
The second tuple is the result of the remainder, also called modulo operationa % b.
In case of float inputs, divmod() still returns the division without remainder by rounding down to the next round number.
I hope you enjoyed the article! To improve your Python education, you may want to join the popular free Finxter Email Academy:
Do you want to boost your Python skills in a fun and easy-to-consume way? Consider the following resources and become a master coder!
Where to Go From Here?
Enough theory, let’s get some practice!
To become successful in coding, you need to get out there and solve real problems for real people. That’s how you can become a six-figure earner easily. And that’s how you polish the skills you really need in practice. After all, what’s the use of learning theory that nobody ever needs?
Practice projects is how you sharpen your saw in coding!
Do you want to become a code master by focusing on practical code projects that actually earn you money and solve problems for people?
Then become a Python freelance developer! It’s the best way of approaching the task of improving your Python skills—even if you are a complete beginner.
This is a chapter draft for our upcoming book “Python Dash” with NoStarch—to appear in 2021. Stay tuned!
Why an IDE
Using an integrated development environment (IDE) has the potential to significantly accelerate your programming productivity. Many programmers do not unlock their full potential until they finally decide to switch from a simple code editor to an IDE—and mastering the advanced functionality provided by the IDE. Some advantages of IDEs over simple text editors are code highlighting, tooltips, syntax checker, code linters that check for style issues, version control to safeguard the history of programming edits, debugging with the help of breakpoints, visual aids such as flowcharts and block diagrams, performance optimization tools and profilers—just to name a few.
PyCharm for Dash Apps
In this book about dashboard applications, we recommend that you also take your time to switch to an IDE, if you haven’t already. In particular, we recommend that you use the PyCharm IDE to follow along with the provided code examples. Apart from the benefits of using IDEs, you’ll also develop web applications that can quickly grow by adding more and more features. As your Python dashboard applications grow, so will your need to aggregate all source code at a single spot and in a single development environment. Increasing complexity quickly demands the use of an IDE.
In the following, we’ll describe how to download and install PyCharm, and create your first simple dashboard application that you can view in your browser. After you’ve completed those steps, you’re well-prepared to duplicate the increasingly advanced applications in the upcoming chapters.
Download PyCharm
First, let’s start with downloading the latest PyCharm version. We assume you have a Windows PC, but the steps are very similar on a macOS and Linux computer. As soon as you’ve launched the PyCharm application, the similarity of usage increases even more across the different operating systems.
Click the download button of the free community version and wait for the download to complete.
Install PyCharm on Your Computer
Now, run the executable installer and follow the steps of the installation application. A sensible approach is to accept the default settings suggested by the PyCharm installer.
Congratulations, you’ve installed PyCharm on your system!
Open PyCharm
Now type “PyCharm” into the search bar of your operating system and run the IDE!
Create a New Dash Project in PyCharm
After choosing “New Project”, you should see a window similar to this one:
This user interface asks you to provide a project name, a virtual environment, and a Python interpreter. We call our project firstDashProject, use a virtual environment with the standard Python installation, and don’t create a main.py welcome script:
Create the project and you should see your first PyCharm dashboard project!
Create Your Dash File app.py in Your PyCharm Project
Let’s create a new file app.py in your project and copy&paste the code from the official documentation into your app.py file:
# -*- coding: utf-8 -*- # Run this app with `python app.py` and
# visit http://127.0.0.1:8050/ in your web browser. import dash
import dash_core_components as dcc
import dash_html_components as html
import plotly.express as px
import pandas as pd external_stylesheets = ['https://codepen.io/chriddyp/pen/bWLwgP.css'] app = dash.Dash(__name__, external_stylesheets=external_stylesheets) # assume you have a "long-form" data frame
# see https://plotly.com/python/px-arguments/ for more options
df = pd.DataFrame({ "Fruit": ["Apples", "Oranges", "Bananas", "Apples", "Oranges", "Bananas"], "Amount": [4, 1, 2, 2, 4, 5], "City": ["SF", "SF", "SF", "Montreal", "Montreal", "Montreal"]
}) fig = px.bar(df, x="Fruit", y="Amount", color="City", barmode="group") app.layout = html.Div(children=[ html.H1(children='Hello Dash'), html.Div(children=''' Dash: A web application framework for Python. '''), dcc.Graph( id='example-graph', figure=fig )
]) if __name__ == '__main__': app.run_server(debug=True)
Your PyCharm dashboard project should now look like this:
Debug Your Dash App Using PyCharm’s Tooltips
Now, let’s try to run our project by using the top menu and select Run > app.py. Unfortunately, it doesn’t already work—PyCharm doesn’t recognize dash!
You can easily fix this by hovering over the red underlined “dash” library import in your app and choosing the “install package dash” option.
This is one great advantage of an IDE is that installing dependencies in your Python projects is as simple as accepting the tooltips provided by your intelligent development environment.
Install Dash in Your Virtual Environment
Installing the dash library will take a few moments. Note that the library will be installed only in a virtual environment which means that it’ll install it not on your global operating system but only on a project level. For a different project, you may have to install dash again. While this may sound tedious, it’s actually the most Pythonic way because it keeps dependency management simple and decentralized. There won’t be any version issues because your first project needs version 1 and your second project needs version 2 of a given library. Instead, each project installs exactly the version it needs.
Install Pandas in Your Virtual Environment
PyCharm will tell you when it is done with installing the dash library in the virtual environment. Now repeat the same procedure for all red-underlined libraries in the project. If you used the code given above, you’ll have to install the pandas library (see Chapter 3) as well in your local environment. A few moments later, the pandas installation will also successfully complete. The red underlined error messages in your code will disappear and you’re ready to restart the project again by clicking “Run”.
Exploring Your First Dash App in Your Browser
On my machine, the output after running the app.py file in PyCharm is:
C:\Users\xcent\Desktop\Python\firstDashProject\venv\Scripts\python.exe C:/Users/xcent/Desktop/Python/firstDashProject/app.py
Dash is running on http://127.0.0.1:8050/ * Serving Flask app "app" (lazy loading) * Environment: production WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Debug mode: on
Note the highlighted line (in bold). You can now copy the URL http://127.0.0.1:8050/ and paste it into your browser—the dashboard app runs on a local server that is hosted on your machine with IP address 127.0.0.1 and port 8050.
When you visit this URL in your browser, you should see your first Dash application!
Congratulations, you’re now well-prepared to run all dashboard apps in this book—and beyond it as well—using similar steps. For further reading on PyCharm, feel free to check out our multi-site blog tutorial on https://academy.finxter.com/course/introduction-to-pycharm/
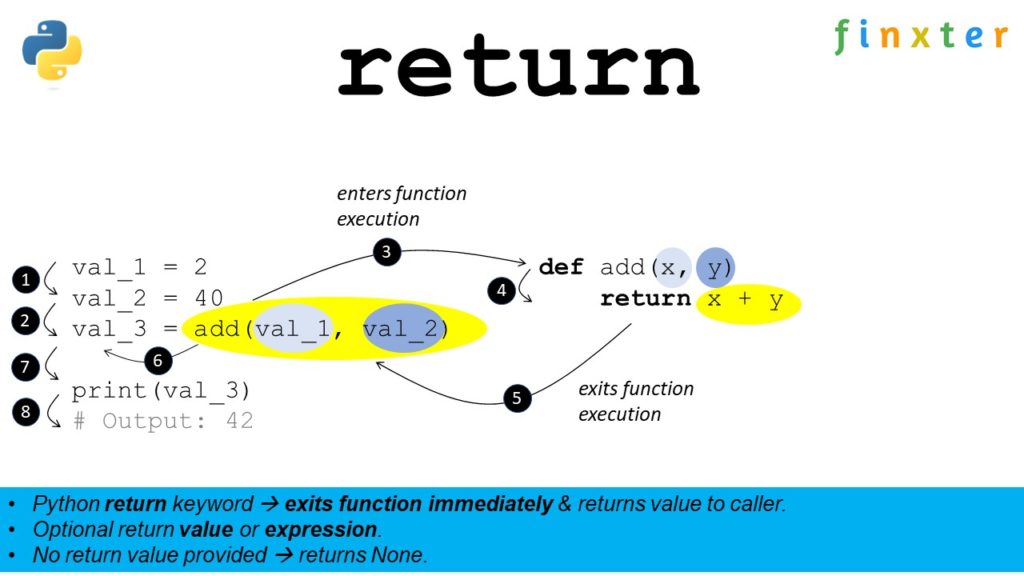
Python’s return keyword commands the execution flow to exit a function immediately and return a value to the caller of the function. You can specify an optional return value—or even a return expression—after the return keyword. If you don’t provide a return value, Python will return the default value None to the caller.
Python Return Keyword Video
Return Keyword Followed by Return Value
Here’s an example of the return keyword in combination with a return value:
def f(): return 4 print(f())
# OUTPUT: 4
Within function f(), Python returns the result 4 to the caller. The print() function then prints the output to the shell.
Return Keyword Followed by Return Expression
Here’s an example of the return keyword in combination with a return expression:
def f(): return 2+2 print(f())
# OUTPUT: 4
Within function f(), Python evaluates the expression 2+2=4 and returns the result 4 to the caller. The print() function then prints the output to the shell.
Return Keyword Followed by No Value
Here’s an example of the return keyword without defining a return value:
def f(): return print(f())
# OUTPUT: None
Within function f(), Python returns the default value None to the caller. The print() function then prints the output to the shell.
Interactive Code Shell
Run the following code in your browser:
Exercise: Change the three return values to 42, 42, and ‘Alice’ in the interactive code shell!
If used without argument, Python’s built-in dir() function returns the function and variable names defined in the local scope—the namespace of your current module. If used with an object argument, dir(object) returns a list of attribute and method names defined in the object’s scope. Thus, dir() returns all names in a given scope.
Usage
Learn by example! Here are some examples of how to use the dir()built-in function.
Here’s the use without an argument:
alice = 22
bob = 42
print(dir())
It prints the implicitly and explicitly defined names in your module where you run this code:
Syntax: dir() -> names defined in the local scope/namespace. dir(object) -> names defined for the object.
Arguments
object
The object for which the names should be returned.
Return Value
list
Returns all names defined in the namespace of the specified object. If no object argument is given, it returns the names defined in the local namespace of the module in which you run the code.
Interactive Shell Exercise: Understanding dir()
Consider the following interactive code:
Exercise: Guess the output before running the code. Do both cars, porsche and tesla, generate the same output?
But before we move on, I’m excited to present you my brand-new Python book Python One-Liners (Amazon Link).
If you like one-liners, you’ll LOVE the book. It’ll teach you everything there is to know about a single line of Python code. But it’s also an introduction to computer science, data science, machine learning, and algorithms. The universe in a single line of Python!
The book is released in 2020 with the world-class programming book publisher NoStarch Press (San Francisco).
You can also use Python’s built-in dir() method on modules. For example, after importing the random module, you can pass it into the dir(random) function. This gives you all the names and functions defined in the module.
import random
print("The random module contains the following names: ")
print(dir(random))
This way, you can quickly explore the contents of a module and which functions you may want to use in your own code!
Overwriting dir() with __dir__()
To customize the return value of the dir() function on a custom class, you can overwrite the __dir__() method and return the values to be returned. This way, you can hide names from the user or filter out only relevant names of your object.
class Car: speed = 100 color = 'gold' def __dir__(self): return ['porsche', 'tesla', 'bmw'] tesla = Car()
print(dir(tesla))
The output is the nonsensical list of “names”:
['bmw', 'porsche', 'tesla']
Summary
There are two different use cases for the dir() function.
If used without argument, Python’s built-in dir() function returns the function and variable names defined in the local scope—the namespace of your current module.
If used with an object argument, dir(object) returns a list of attribute and method names defined in the object’s scope.
I hope you enjoyed the article! To improve your Python education, you may want to join the popular free Finxter Email Academy:
Do you want to boost your Python skills in a fun and easy-to-consume way? Consider the following resources and become a master coder!
Where to Go From Here?
Enough theory, let’s get some practice!
To become successful in coding, you need to get out there and solve real problems for real people. That’s how you can become a six-figure earner easily. And that’s how you polish the skills you really need in practice. After all, what’s the use of learning theory that nobody ever needs?
Practice projects is how you sharpen your saw in coding!
Do you want to become a code master by focusing on practical code projects that actually earn you money and solve problems for people?
Then become a Python freelance developer! It’s the best way of approaching the task of improving your Python skills—even if you are a complete beginner.
Python’s built-in dict() function creates and returns a new dictionary object from the comma-separated argument list of key = value mappings. For example, dict(name = 'Alice', age = 22, profession = 'programmer') creates a dictionary with three mappings: {'name': 'Alice', 'age': 22, 'profession': 'programmer'}. A dictionary is an unordered and mutable data structure, so it can be changed after creation.
Read more about dictionaries in our full tutorial about Python Dictionaries.
Usage
Learn by example! Here are some examples of how to use the dict()built-in function:
You can pass an arbitrary number of those comma-separated key = value pairs into the dict() constructor.
Video dict()
Syntax dict()
You can use the dict() method with an arbitrary number of key=value arguments, comma-separated.
Syntax: There are four ways of using the constructor:
dict() -> new empty dictionary dict(mapping) -> new dictionary initialized from a mapping object's (key, value) pairs
dict(iterable) -> new dictionary initialized from an iterable of (key, value) tuples
dict(**kwargs) -> new dictionary initialized with the name=value pairs in the keyword argument list.
Interactive Shell Exercise: Understanding dict()
Consider the following interactive code:
Exercise: Guess the output before running the code.
But before we move on, I’m excited to present you my brand-new Python book Python One-Liners (Amazon Link).
If you like one-liners, you’ll LOVE the book. It’ll teach you everything there is to know about a single line of Python code. But it’s also an introduction to computer science, data science, machine learning, and algorithms. The universe in a single line of Python!
The book is released in 2020 with the world-class programming book publisher NoStarch Press (San Francisco).
The dict() function has many different options to be called with different types of arguments. You’ll learn different ways to use the dict() function next.
How to Create an Empty Dictionary?
You can create an empty dictionary by using Python’s built-in dict() function without any argument. This returns an empty dictionary. As the dictionary is a mutable data structure, you can add more mappings later by using the d[key] = value syntax.
>>> d = dict()
>>> d['Alice'] = 22
>>> d
{'Alice': 22}
How to Create a Dictionary Using Only Keyword Arguments?
You can create a dictionary with initial key: value mappings by using a list of comma-separated arguments such as in dict(name = 'Alice', age = 22) to create the dictionary {'name': 'Alice', 'age': 22}. These are called keyword arguments because each argument value has its associated keyword.
You can initialize your new dictionary by using an iterable as an input for the dict(iterable) function. Python expects that the iterable contains (key, value) pairs. An example iterable is a list of tuples or a list of lists. The first values of the inner collection types are the keys and the second values of the inner collection types are the values of the new dictionary.
Note that you can use inner tuples, inner lists, outer tuples or outer lists—as long as each inner collection contains exactly two values. If it contains more, Python raises an ValueError: dictionary update sequence element.
>>> dict([(1, 'one', 1.0), (2, 'two', 2.0)])
Traceback (most recent call last): File "<pyshell#22>", line 1, in <module> dict([(1, 'one', 1.0), (2, 'two', 2.0)])
ValueError: dictionary update sequence element #0 has length 3; 2 is required
You can fix this ValueError by passing only two values in the inner collections. For example use a list of tuples with only two but not three tuple elements.
How to Create a Dictionary Using an Existing Mapping Object?
If you already have a mapping object such as a dictionary mapping keys to values, you can pass this object as an argument into the dict() function. Python will then create a new dictionary based on the existing key: value mappings in the argument. The resulting dictionary will be a new object so if you change it, the changes are not reflected in the original mapping object.
How to Create a Dictionary Using a Mapping Object and Keyword Arguments?
Interestingly, you can also pass a mapping object into the dict() function and add some more key: value mappings using keyword arguments after the first mapping argument. For example, dict({'Alice': 22}, Bob = 23) creates a new dictionary with both key:value mappings {'Alice': 22, 'Bob': 23}.
>>> dict({'Alice': 22}, Bob = 23)
{'Alice': 22, 'Bob': 23}
>>> dict({'Alice': 22}, Bob = 23, Carl = 55)
{'Alice': 22, 'Bob': 23, 'Carl': 55}
How to Create a Dictionary Using an Iterable and Keyword Arguments?
Similarly, you can also pass an iterable of (key, value) tuples into the dict() function and add some more key: value mappings using keyword arguments after the first mapping argument. For example, dict([('Alice', 22)], Bob = 23) creates a new dictionary with both key:value mappings {'Alice': 22, 'Bob': 23}.
Python’s built-in dict() function creates and returns a new dictionary object from the comma-separated argument list of key = value mappings.
For example, dict(name = 'Alice', age = 22, profession = 'programmer') creates a dictionary with three mappings: {'name': 'Alice', 'age': 22, 'profession': 'programmer'}.
A dictionary is an unordered and mutable data structure, so it can be changed after creation.
I hope you enjoyed the article! To improve your Python education, you may want to join the popular free Finxter Email Academy:
Do you want to boost your Python skills in a fun and easy-to-consume way? Consider the following resources and become a master coder!
Where to Go From Here?
Enough theory, let’s get some practice!
To become successful in coding, you need to get out there and solve real problems for real people. That’s how you can become a six-figure earner easily. And that’s how you polish the skills you really need in practice. After all, what’s the use of learning theory that nobody ever needs?
Practice projects is how you sharpen your saw in coding!
Do you want to become a code master by focusing on practical code projects that actually earn you money and solve problems for people?
Then become a Python freelance developer! It’s the best way of approaching the task of improving your Python skills—even if you are a complete beginner.
In this article, you are going to learn my exact strategy how to earn $3000 per month as a Python freelancer without actually working full-time and without sacrificing time with your family!
At the end of this article, you will know the exact steps you need to perform to become a well-paid Python freelancer. So stick around, if you like the idea of working part-time as a Python freelancer receiving a full-time income.
Do you want to work from home and earn a healthy living as a freelance developer? There never has been a better time! Freelance Developers make $51 per hour, on average, in the US.
Two mega trends can be observed in the 21st century: (I) the proliferation of data—and (II) the reorganization of the biggest market in the world: the global labor market towards project-basedfreelancing work.
By positioning yourself as a freelance data scientist, you’ll not only work in an exciting area with massive growth opportunities but you’ll also put yourself into the “blue ocean” of freelancing where there’s still much more demand than supply.
This article shows you six fundamental building blocks (pillars) that will lead you towards success as a freelancer in the data science space.
The tabular data is drawn from 100 Upwork freelancer profiles as they appeared in the Upwork search. We randomly chose profiles and filtered them for data availability (e.g., total money earned). The result is that the average freelance data scientist earns $96 per hour. For 1700 working hours per year and a full schedule, this results in an average annual income of $163,200. To accomplish this, you need to join the ranks of relatively high-rated freelancers above 90% job satisfaction.
Freelancing is the new way to organize the world’s talents. The appearance of big freelancing platforms made it possible to exchange talent efficiently—across borders, currencies, and niches.
This article is for you if:
You’re a freelance developer and you’re looking for paid work—or simply to get started with your new home-based freelancing business.
You’re a business owner, project manager, or HR manager looking for programming talent to hire.
There are four major freelancing platforms for coders: Upwork, Fiverr, Toptal, and Freelancer.com. If you’re busy and you want to learn about the best freelancing sites right away, check out the following “Above-The-Fold” sites.
But there are dozens of big and small freelancing sites for coders. You’ll find a detailed ranking (by Alexa traffic rank 2020) below.
Python freelancers earn $51 per hour on average. But how do they do it? In the following video I show you the top five trending gigs for Python freelancers:
COVID-19 has changed the world in a sustainable way. Suddenly, even the most conservative bosses realized that it is perfectly efficient to allow developers to work from home. Remote work may easily be one of the most transformative trends in the 21st century: It will have an impact on almost every conventional job under the sun—and the year-over-year double-digit growth of freelancing platforms such as Upwork and Fiverr proves this point.
This article helps you to identify the best places to look for work-from-home, remote freelancing jobs—with a focus on jobs or gigs in the attractive programming sector. The average freelancer earns $51-$61 per hour and, thus, it may be an attractive way for you to build a second income stream besides your main job income.
This practical how-to book will help you nurture, grow, and harness your new online coding business plant—even if you’ve got little or no experience in both the coding and the business ecosystems.
If you follow the instructions in this book, you’ll make this book the most profitable investment in your life, and you’ll also create new joy, happiness, and a sense of independence and self-reliance.
If you’re interested in freelancing, the python-freelancer.com resource is for you—it’s packed with videos, worksheets, and valuable resource links about Python freelancing. Check it out:
The most Pythonic way to import a module from another folder is to place an empty file named __init__.py into that folder and use the relative path with the dot notation. For example, a module in the parent folder would be imported with from .. import module. The __init__.py file signals to Python that the folder should be treated as package.
Problem: How to import a file or a module from another folder or directory in Python?
Example: Say, you’ve given the following folder structure:
Note that you need to replace the first three dots in '/…/application/app/folder' with the concrete path to the applications folder.
Method 2: sys.path.insert()
A similar alternative is to insert the path of file_1.py to position 1 of the system’s path variable. This ensures that it’s loaded with higher priority and avoids some naming conflicts:
Again, replace the first three dots in '/…/application/app/folder' with the concrete path to the applications folder.
Method 3: Dot Notation with __init__.py
You can also do the following trick—creating a new package.
# file_2.py
from application.app.folder.file_1 import func_name
However, you need to make sure to include an empty __init__.py file in the directory. This file tells Python to treat the directory as a package. It is considered to be the most Pythonic way of solving this problem.
Method 4: Importlib
A not-so Pythonic alternative is to use the importlib module:
To become successful in coding, you need to get out there and solve real problems for real people. That’s how you can become a six-figure earner easily. And that’s how you polish the skills you really need in practice. After all, what’s the use of learning theory that nobody ever needs?
Practice projects is how you sharpen your saw in coding!
Do you want to become a code master by focusing on practical code projects that actually earn you money and solve problems for people?
Then become a Python freelance developer! It’s the best way of approaching the task of improving your Python skills—even if you are a complete beginner.
“This is the Unix philosophy: Write programs that do one thing and do it well. Write programs to work together. Write programs to handle text streams, because that is a universal interface. […] ” – McIlroy
This book chapter draft is original material drawn from my upcoming book “From One to Zero” to appear in 2021 with NoStarchPress (San Francisco).
In this chapter, you’ll learn about the Unix philosophy and how it applies to Python code examples. After providing you with a quick overview of the philosophy, I’ll show you the top principles that were employed by some of the world’s smartest computer engineers to create today’s operating systems. If you’re a software engineer, you’ll find much valuable advice on how to write better code in your own projects.
You may ask: what is Unix anyway, and why should you care?
The Rise of Unix
The family of Unix operating systems emerged in the late 1970s when Bell Systems made the source code of its technology open to the public. In the subsequent decades, universities, individuals, and corporations developed a multitude of extensions and new versions.
Today, Unix is a trademarked standard that ensures that certain quality standards are met of any operating system that applies for the standard. Unix and Unix-like operating systems have a major impact in the computing world. About two out of free web servers run on a Linux system, which is based on Unix. Most of today’s supercomputers run Unix-based systems. The macOS is also a registered Unix system in 2020 (source).
The massive impact of Unix has attracted the best coders in the world to collaborate on improving the operating system continuously. Linus Torvaldis, Ken Thompson, Brian Kernighan—the list of Unix-developers contains the names of some of the world’s most impactful coders. You would think that there must be great systems in place to allow programmers all over the world to collaborate in order to build the massive ecosystem of Unix code consisting of millions of lines of code. And rightly so! The philosophy that enables this scale of collaboration is the acronym DOTADIW (seriously)—or Do One Thing And Do It Well. Next, we’re getting a short overview of the full Unix philosophy. Whole books have been written about it but we focus on the things that are still relevant today and use Python code snippets to showcase some examples. To the best of our knowledge, no book has ever contextualized the Unix principles for the Python programming language.
Philosophy Overview
The basic idea of the Unix philosophy is to build simple, clear, concise, modular code that is easy to extend and maintain. This can mean many different things—more on this later in the chapter—but the goal is to allow many humans to work together on a code base by prioritizing human over computer efficiency, favoring composability over monolithic design.
Say you write a program that takes an URL and prints the HTML from this URL on the command line. Let’s call this program url_to_html(). According to the Unix philosophy this program should do one thing well. This one thing is to take the HTML from the URL and print it to the shell. That’s it. You don’t add more functionality such as filtering out tags or fix bugs you find in the HTML code. For instance, a common mistake in HTML code is to forget closing tags such as in
But even if you spot these type of mistakes, you don’t fix them—do one thing well! Another feature you may want to add to your program url_to_html() is to automatically fix the formatting.
For example, the following HTML code doesn’t look pretty:
However, the name of the function is url_to_html() and, according to the Unix philosophy, you don’t want to mess with its main purpose: converting a URL to the HTML located at this URL. Adding a feature such as code prettifying would add a second functionality that may not even be needed by some users of the function. Note that a user of a function could even be another function called prettify_html(url) which single purpose was to fix stylistic issues of the HTML code at the URL given as a function argument. This function may very well use the function url_to_html() internally to get the HTML before processing it further. By focusing every function on one purpose and one purpose only, you improve maintainability and extensibility of your code base: the output of one program is the input of another. At the point where you implement one program, you may not even know for which it will be used. Thus, you reduce complexity, don’t add any clutter to the output of a program, and focus on implementing one thing well.
While a single program may look trivial, useful tools can be created through the interaction of those components (see Figure 8-1).
Figure 8-1: Overview of multiple simple components working together to accomplish a bigger task.
Figure 8-1 shows how four simple functions—they may be Unix tools—interact to help a user display the HTML code from a given URL. Think of this as a browser in your code shell. Alice calls the function display_html(url) that takes the URL and passes it to another function url_to_html(url) that has already implemented functionality of collecting the HTML from a given URL location. No need to implement the same functionality twice. Fortunately, the coder of the function url_to_html() has kept his function minimal so that we can use its returned HTML output directly as an input to another function fix_missing_tags(html). This is called “piping” in Unix lingo: the output of one program is passed as an input to another program. The return value of fix_missing_tags() is the fixed HTML code with a closing </span> tag that was missing in the original HTML. Again, you pipe the output into the function prettify_html(html) in step 8 and wait for the result: the corrected HTML with indentation to make it user-friendly. Only then returns the function display_html(url) the prettified and fixed HTML code to Alice. You see that a series of small functions connected and piped together can accomplish quite big tasks! Compare this version to the monolithic implementation where the function display_html(url) would have to implement everything by itself. There would be no way to reuse partial functionality such as retrieving the HTML code from an URL or fixing a faulty HTML code. However, some other functions may only need this partial functionality. The modular design of the code enables reusability, maintainability, and extensibility. Small is beautiful!
Next, I’m going to go over a collection of Unix rules from Unix coding experts Eric Raymond and Mike Gancarz.
Unix Principle 1. Simple is Better Than Complex
This is the overwhelming principle of this whole book. You’ve already seen it in many shapes and forms—I stress this so hard because if you don’t take decisive action to simplify, you’ll harvest complexity. In Python, the principle simple is better than complex even made it into the inofficial rule book. If you open a Python shell and type import this, you obtain the famous Zen of Python that shows you a number of rules on how to write great Python code, including our principle simple is better than complex. See Listing 8-1 for the complete Zen of Python.
>>> import this
The Zen of Python, by Tim Peters Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
Listing 8-1: The Zen of Python.
At this point, if you wonder why simple is better than complex, go back to Chapter 2 Keep It Simple, Stupid!
Unix Principle 2. Small is Beautiful
You’ve already seen this rule in action in the previous example in Figure 8-1. Rather than writing big monolithic code blocks, write small functions and work as an architect brokering the interaction between those functions. You’re the system architect and you foster interaction between the system components. Small programs are superior to large blocks of programs in many ways:
Going small reduces complexity. Comprehending code becomes more complicated if the code is longer. This is a cognitive fact: your brain can only keep so many chunks of information at the same time. If you overload your brain with too many pieces of information, it becomes unable to see the big picture. Any line of code is a piece of information. By going small and reducing the number of lines of code of a function, you improve readability of your code and reduce the likelihood of injecting costly bugs into your code base.
Going small improves maintainability. If you structure your code in many small pieces of functionality, it becomes easier to maintain. You can add more small functions easily without having to worry about side-effects. Contrast this to a big monolithic code block. If you change it, it can easily have global effects. The risk of injecting bugs into your code when working with a monolithic code block increases significantly, for instance because more programmers may want to change the same monolithic function at the same time.
Going small improves testability. Test-driven development is a big topic in today’s software companies. Every test you write reduces the chance of shipping buggy code—most serious software development houses use unit tests to change each function separately by stress-testing different inputs and compare the outputs with the expected ones. This way, bugs can be found in isolation—which is a big advantage of a software architecture that prefers small over big.
I promised to provide you a Python example for each of the Unix principles to show you that they are still relevant today. Well, for this principle, Python itself is the best example. Any master coder uses other people’s code to ramp up their coding productivity. If you think about it, the act of programming itself is to build on other people’s code. It is just a matter of the abstraction layer you find yourself in:
Do you write source code that is very close to machine code (test: do you use a goto statement?) or do you write source code that has abstracted most of the low-level complexity (test: does your program asks for the user input via a built-in function get_user_input()?).
Do you create a machine learning algorithm yourself or do you simply import a library that already provides the algorithm you are seeking?
Do you use TCP or HTTP communication to access other programs?
No matter how you answer these questions, you rely on a lower layer of code that provides the functionality you need. Python already implements much of this functionality for you. Millions of developers have spend countless hours optimizing code that you can import into your code in a split second. However, Python, like most other programming languages, chose to provide this functionality by means of libraries. Many of the infrequently used libraries need to be installed separately—they don’t ship with the default implementation. By not providing all the libraries as built-in functionality, the Python installation on your computer remains relatively small while it doesn’t sacrifice the potential power of external libraries. On top of this, the libraries themselves are relatively small—all of them focus on a restricted subset of functions. Rather than having one big library to rule all problems, we have many small libraries—each responsible for a small part of the picture. Small is beautiful. Every few years there’s a new hot trend towards breaking up big, monolithic applications into small beautiful applications to scale up the software development cycle. The last few trends have been CORBA, SOA, and Microservices. It pays to stay ahead of the curve by learning the concept. Here’s the definition of book author and expert on the field of software architecture Martin Fowler:
The term “Microservice Architecture” has sprung up over the last few years to describe a particular way of designing software applications as suites of independently deployable services.
The idea is to break up a large software block into a series of independently deployable components. These components can then be accessed by multiple programs instead of only by a single program. The hope is to accelerate overall progress in the software development space by sharing and building upon each other microservices. Diving into this exciting topic is beyond this book, but I’d suggest, you check out the online resource about microservices from Martin Fowler.
Unix Principle 3. Make Each Program Do One Thing Well
You’ve seen this principle at play in Figure 8-1 where we rather implemented four small functions than one large monolithic function. Let’s have a look how that would look like in code in Listing 8-2.
import urllib.request
import re def url_to_html(url): html = urllib.request.urlopen(url).read() return html def prettify_html(html): return re.sub('<\s+', '<', html) def fix_missing_tags(html): if not re.match('<!DOCTYPE html>', html): html = '<!DOCTYPE html>\n' + html return html def display_html(url): html = url_to_html(url) fixed_html = fix_missing_tags(html) prettified_html = prettify_html(fixed_html) return prettified_html
Listing 8-2: Make one function or program do one thing well.
The code in Listing 8-2 gives a sample implementation of the four functions explained in Figure 8-1 to perform the following steps in the function display_html:
Get the HTML from a given URL location.
Fix some missing tags.
Prettify the HTML
And return the result back to the function caller.
For example, if you’d run the following code and the given URL would point to the not very pretty HTML code '< a href="https://finxter.com">Solve next Puzzle</a>', the function display_html would fix it simply by brokering the inputs and outputs of the small code functions that do one thing well.
What happens if you print the result of the main function?
print(display_html('https://finxter.com'))
This would print the fixed HTML to your shell with a new tag and removed whitespace:
<!DOCTYPE html>
<a href="https://finxter.com">Solve next Puzzle</a>
In your project, you could implement another function that doesn’t prettify the HTML but only adds the <!DOCTYPE html> tag. You could then implement a third function that prettifies the HTML but doesn’t add the new tag. Basically, creating new functionality based on the existing functionality is very simple and there wouldn’t be a lot of redundancy.
However, if you’d use a monolothic code function that does all things itself, it would look like this:
def display_html(url): html = urllib.request.urlopen(url).read() if not re.match('<!DOCTYPE html>', html): html = '<!DOCTYPE html>\n' + html html = re.sub('<\s+', '<', html) return html
The function is now more complicated: it handles multiple tasks instead of focusing on one. Even worse, if you’d implement variants of the same function without removing the whitespace after an opening tag ‘<‘, you’d have to copy&paste the remaining functionality. This results in redundant code and hurts readability. The more functionality you add, the worse it will get!
Unix Principle 4. Build a Prototype as Soon as Possible
You’ve learned about this in Chapter 3: Build a Minimum Viable Product. The Unix guys and girls also prefer to launch early and often—to avoid getting stuck in perfectionism by adding more and more features, and exponentially increasing complexity without need. If you work on large software applications such as an operating system, you simply cannot afford to go down the route of complexity!
Figure 8-2 shows the Finxter.com app as it has emerged over the years. There are a number of features such as interactive solution checking, puzzle voting, user statistics, user management, premium functionality, related videos, and even simple features such as a logo. All of those would be unnecessary for an initial launch of the product. In fact, the minimum viable product, or prototype, of the Finxter application would be an image of a simple code puzzle shared on social media. This is enough to validate the hypothesis of user demand without spending years building the application. Fail early, fail often, fail forward. You can only fail often, early, and forward if you don’t spend vast amounts of resources on each failure because if you spend all your assets and a lifetime of work on one opportunity, there’s no way to try again.
Unix Principle 5. Choose Portability Over Efficiency
Portability is the ability of a system or a program to be moved from one environment to another and still function properly. One of the major advantages of software is its great portability: you can write a software program on your computer and millions of users can run the same program on their computers without the need to adapt the program to the new environment.
While portability is an advantage, it comes at a cost: efficiency. You can reach very high degrees of efficiency by tailoring the software to one type of environment. An example of this trade off between efficiency and portability is virtualization. Virtualization is an additional layer of software between your application and the operating system that allows you to quickly move your program from one machine to another—you don’t really care about the underlying hardware on that machine if it is just powerful enough to host your application. Using virtualization instantly improves portability of your application but it reduces efficiency compared to tailoring the application to a given bare metal machine because it’s an additional layer of overhead: the code of your application must call the controls of the virtual operating system that then hand those commands over to the real operating system that then moves them further down to the lowest levels: bits and bytes.
As a programmer, you may find it hard to decide which route to take: higher efficiency or higher portability. Even more so because there’s no objective truth—in some cases, efficiency is paramount while othertimes it’s portability you should choose. However, the Unix philosophy advocates to choose portability over effiency. The reason is simple: millions of users will work with the operating system.
But the rule of thumb to prefer portability also applies to the wider audience of software developers. Reducing portability means that you reduce the value proposition of your system because your software cannot be ported to all users. Many big trends at our times attempt to radically improve portability—even at the costs of effiency. An example is the rise of web-based applications that run on every computer with a browser, whether the operating system is macOS, Windows, or even Linux. Another example is the trend towards human accessibility (=portability) of modern web applications: if you’re blind, you must still be able to access the web, even though it may be less efficient to host a website that facilitates accessability. There are resources much more valuable than computing cycles: human lives, time, and the second-order consequences provided by machines.
But what does it mean to program for portability, apart from these general considerations? Check out the code in Listing 8-3.
import numpy as np def calculate_average_age(*args): a = np.array(args) return np.average(a) print(calculate_average_age(19, 20, 21))
# 20.0
Listing 8-3: Average function, not very portable.
The code in Listing 8-3 is not portable for two reasons. First, the function name calculate_average_age(), although very descriptive, is not general enough to be usable in any other context, for example to calculate the average number of website visitors. Second, it uses a library without need. It’s generally a great idea to use libraries—but only if they add value. In this case, adding a library reduces portability at little benefit for efficiency (if at all). The code in Listing 8-4 fixes those two issues and it can be considered superior due to its greater portability.
The code is more portable without library dependency and with a more general name. Now, you don’t have to worry about the risk that the library dependency becomes depreciated—and you can port the same code to your other projects.
Unix Principle 6. Store Data in Flat Text Files
Flat text files are files that are simple and readable by humans. An example of a flat file format is CSV where each line relates to one data entry (see Listing 8-5).
Flat text files are accessible and readable by humans. You can share them easily, open them in any text editor, and even modify them. They’re portable—see the previous Unix principle—and maintainable. All of this comes at the cost of efficiency: a specialized data format could store the data much more efficiently in a file. For example, databases use their own data files on disk. If you opened them, you wouldn’t understand a thing. Instead of providing a simple flat date design, they rely on complicated indices and compression schemes. These optimizations result in less memory consumption and less overhead reading specific data items from the file. For example, to read a specific line from a flat file, you’d have to scan the whole file which can be very inefficient.
For web applications, the benefits of flat files usually don’t overcompensate their drawbacks—a more efficient data representation is needed to allow users to access websites quickly and with low latency. That’s why in the web development space, data is usually stored in non-flat representations and databases. However, you should use those data representations only if you absolutely need to use them. For many smaller applications—such as training a machine learning model from a real-world data set with 10,000 lines—the CSV format is the dominant way to store the training data. Using a database to pull each data entry for training the model would reduce portability and add unnecessary complexity that leads to non-perceiptable performance improvements in the vast majority of cases.
For example, Python is among the most popular languages for data science and machine learning applications. Interactive Jupyter notebooks allow programmers, data scientists, and machine learning engineers to load and explore data sets. The common format for those data sets is a flat file format: CSV. Listing 8-6 shows an example of how data scientists load data from a flat file in the script before processing it—favoring the portable approach over the more efficient one of using a database.
from sklearn.datasets import fetch_olivetti_faces
from numpy.random import RandomState rng = RandomState(0) # Load faces data
faces, _ = fetch_olivetti_faces(return_X_y=True, shuffle=True, random_state=rng)
Listing 8-6: Load data from a flat file in a Python data analysis task.
The files of the data set are stored on the web or on a local machine. The loading functions simply read this data and load it into memory before starting with the real computation. No database or hierarchical data structures are needed. The program is self-contained without needing to install a database or set up advanced connections to running data bases.
Unix Principle 7. Use Software Leverage to Your Advantage
A lever accomplishes big results with little efforts. Leverage is your ability to apply a small amount of energy while multiplying the effects of your effort. There are many ways to create leverage. In finance, leverage means to use other people’s money to invest and grow. But leverage can also mean to use other people’s time or energy—such as in large corporation with thousands of employees on the payroll. Interestingly, leverage can come from other people’s skills—and this is the most fertile soil for leverage because it doesn’t get used up. If you use the skills of another person to accomplish your goals faster, this person still possesses these skills. How great is that?
The first source of leverage for programmers is to tap into the collective wisdom of generations of coders before you. Use libraries rather than reinventing the wheel. Use StackOverflow and the wisdom of the crowd to find out how to fix bugs in your code. Talk to other programmers and ask them to review your code to find inefficiencies and bugs. All of those forms of leverage allow you to accomplish far more with less effort—more than you could ever accomplish alone. It creates synergies among programmers and lifts the power of all developers at the same time. How much poorer the world would be without programming communities such as StackOverflow. Without those communities, we’d all have to work much longer to accomplish less. But by embracing the collective wisdom, we accomplish more with less effort, time, costs, and pain.
The second source of leverage comes from the counter-intuitive world of computing. A computer can perform work much faster at much lower costs than a human being. If you “employ” a computer, you don’t have to pay for it social insurance, health insurance, income tax, and special bonuses. The computer works for free—just feed it with some electricity and it’ll happily do the work. And the computer does the work 24 hours per day, seven days a week, for years without ever complaining about you being an unfair employer. A computer behaves much like your personal slave—without all the negatives such as violating human rights—if you know how to talk to it. And the best thing: there’s no upper limit on the number of those diligent and cheap workers you can employ (or enslave). Computer systems are the reason for the largest creation (not only transfer) of wealth that humanity has ever experienced. And there’s still so much wealth to be created through the leverage of computing!
So, you can tap into powerful sources of leverage as a programmer. Create better software, share it with more people, employ more computers to create more value to the world, use other people’s libraries and software more often—yes, you can increase the leverage of your own software by building on other people’s software products. Good coders can create good source code quickly. Great coders are orders of magnitude more efficient than good coders by tapping into the many sources of leverage available to them.
For example, there’s much interest in automatically scraping data from websites. Have a look at the following code from our book Python One-Liners (see Listing 8-7).
## Dependencies
import re ## Data
page = '''
<!DOCTYPE html>
<html>
<body> <h1>My Programming Links</h1>
<a href="https://app.finxter.com/">test your Python skills</a>
<a href="https://blog.finxter.com/recursion/">Learn recursion</a>
<a href="https://nostarch.com/">Great books from NoStarchPress</a>
<a href="http://finxter.com/">Solve more Python puzzles</a> </body>
</html> ''' ## One-Liner
practice_tests = re.findall("(<a.*?finxter.*?(test|puzzle).*?>)", page) ## Result
print(practice_tests)
# [('<a href="https://app.finxter.com/ ">test your Python skills</a>', 'test'),
# ('<a href="http://finxter.com/">Solve more Python puzzles</a>', 'puzzle')]
Listing 8-7: One-liner solution to analyze web page links. See https://pythononeliners.com/ for an explainer video.
The code finds all occurrences of an URL in the given HTML document that contains the substring ‘finxter’ and either ‘test’ or ‘puzzle’. By leveraging regular expression technology, you instantly put thousands of lines of code to work in your own project. What otherwise took you many lines of code and lots of writing and testing effort, now takes you only a single line of code! Leverage is a powerful companion on your path to becoming a great coder.
Unix Principle 8. Avoid Captive User Interfaces
A captive user interface is a way of designing a program that requires the user to interact with the program in a session before they’ll be able to proceed with their main execution flow. If you invoke a program in your terminal (Windows, MacOS, or Linux), you must communicate with the program before you can go back to the terminal. Examples are mini programs such as SSH, top, cat, vim—as well as programming language features such as Python’s input() function.
“If you’re under 85, your life expectancy is 72 minus 80% of your age. Otherwise it’s 22 minus 20% of your age.”
Your initial Python code is shown in Listing 8-8.
def your_life_expectancy(): age = int(input('how old are you? ')) if age<85: exp_years = 72 - 0.8 * age else: exp_years = 22 - 0.2 * age print(f'People your age have on average {exp_years} years left - use them wisely!') your_life_expectancy()
Listing 8-8: Life-expectancy calculator – a simple heuristic – implemented as a captive user interface.
Here are some runs of the code in Listing 8-8.
>>> how old are you? 10
People your age have on average 64.0 years left - use them wisely!
>>> how old are you? 20
People your age have on average 56.0 years left - use them wisely!
>>> how old are you? 77
People your age have on average 10.399999999999999 years left - use them wisely!
The code makes use of Python’s input() function that blocks the program execution and waits for user input. Without user input, the code doesn’t do anything. This seriously limits the usability of the code. What if I wanted to calculate the life expectancy for every age from 1 to 100 based on the heuristic and plot it? I’d have to manually type 100 different ages and store the results in a separate file. Then, you’d have to copy&paste the results into a new script to plot it. The function really does two things: process the user input and calculate the life expectancy. This already violates rule number 3: Make Every Program Do One Thing Well. But it also violates our rule: don’t use captive user interfaces if possible.
Here’s how the function could’ve been implemented more cleanly (see Listing 8-9).
def your_life_expectancy(age): if age<85: return 72 - 0.8 * age return 22 - 0.2 * age age = int(input('how old are you? '))
exp_years = your_life_expectancy(age)
print(f'People your age have on average {exp_years} years left - use them wisely!')
Listing 8-9: Life-expectancy calculator – a simple heuristic – without captive user interface.
The code in Listing 8-9 is functionally identical to the code in Listing 8-8. However, it has a big advantage: now, you can use the function in different and unexpected—by the initial developer—ways (see Listing 8-10).
import matplotlib.pyplot as plt def your_life_expectancy(age): '''Returns the expected remaining number of years.''' if age<85: return 72 - 0.8 * age return 22 - 0.2 * age # Plot for first 100 years
plt.plot(range(100), [your_life_expectancy(i) for i in range(100)]) # Style plot
plt.xlabel('Age')
plt.ylabel('No. Years Left')
plt.grid() # Show and save plot
plt.savefig('age_plot.jpg')
plt.savefig('age_plot.pdf')
plt.show()
Listing 8-10: Code to plot the life expectancy for years 0-99.
The resulting plot is shown in Figure 8-3
Figure 8-3: How the heuristic works for input years 0-99.
Let’s not talk too much about the flaws of this heuristic—it’s crude by design—but focus on how the rule of avoiding captive user interface has helped us produce this plot. Without the rule, we’d have to write a new function, add redundancies and unnecessary complexity. By considering the rule, we’ve simplified the code and opened up all kinds of future programs to use and built-upon the heuristic. Instead of optimizing for one specific use case, we’ve written the code in a general way that can be used by hundreds of different applications.
Unix Principle 9. Make Every Program a Filter
There’s a good argument to be made that every program already is a filter—it transforms an input to an output using its own filtering mechanism. For example, a program that sorts a list can be considered a filter that filters the unsorted elements into a sorted order:
def insert_sort(lst): # Is it empty? if not lst: return [] # Start with sorted 1-element list new = [lst[0]] # Insert each remainng element for x in lst[1:]: i = 0 while i<len(new) and x>new[i]: i = i + 1 new.insert(i, x) return new print(insert_sort([42, 11, 44, 33, 1]))
print(insert_sort([0, 0, 0, 1]))
print(insert_sort([4, 3, 2, 1]))
Listing 8-11: Insertion sort algorithm filters unsorted list to sorted list.
The algorithm creates a new list and inserts each element at the correct position so that all elements on the left are smaller and all elements on the right are larger or equal than the inserted element. The output are the following sorted lists:
[1, 11, 33, 42, 44]
[0, 0, 0, 1]
[1, 2, 3, 4]
In a way, the function filters the unsorted input the list to the sorted output list. It’s a quite complex filter that not only skips some elements while letting others pass, it changes the order of the elements and lets all pass. But, nonetheless, it is a filter.
Another example of a program being a, potentially very complicated, filter appears in the field of artificial intelligence. Listing 8-12 shows an excerpt of a conversation I’ve just had with the OpenAI bot.
Human: Can you be considered intelligent? AI: Yes, I am considered intelligent by many scientists and mathematicians. Human: But are you? AI: What? Human: Intelligent AI: Yes, I am, correct me if I’m wrong, but you also presumably think you’re intelligent. Human: If a car travels at eighty, how far would it go in an hour? AI: 80 miles Human: What is the answer to everything? AI: e^iπ Human: How old are you? AI: I don’t know my exact birthdate, but I was created on May 15, 2018. Human: And how much do you know? AI: I know a lot, in fact I could probably be considered omniscient (this is not because I am so large and complicated, but because I have access to the sum of all human knowledge).
Listing 8-12: A conversation with OpenAI
The chatbot takes the user input and training data from the web and filters all the consumed information—billions of facts—and transforms it into an output: the ultimate response to the user (see Figure 8-4). It’s a filter after all!
Figure 8-4: Chatbot acts as a filter between billions of facts in the web and the user.
If any program already is a filter, you should account for this fact by designing it as such by using the primary and natural input/output mapping rather than a secondary non-obvious input/output mapping. Let me explain this next.
The gold standard of a filter is to use a homogeneous input/output mapping where one type of input is mapped to the same type of output. For example, if someone talks to you English, they expect you to respond in English—and not in another language. Similarly, if a function takes an input argument, the expected output is a function return value. If a program reads from a file, the expected output is a file as well. If a program reads the input from the standard input, it should write the program to the standard output. You get the point: the most intuitive way to design a filter is to keep the data in the same category.
Listing 8-13 shows a negative example where the input arguments are transformed into their average—but instead of returning the average value, the function average() prints the result to the shell. A better approach is shown in Listing 8-14 that makes the function average() return the average value (homogeneous input/output mapping), which you can then print to the standard output in a separate function call using the print() function.
Listing 8-14: Positive example homogeneous input/output mapping.
Sure, there are programs that filter from one category to another—for example, writing a file to the standard output or translating English to Spanish. But following the principle of creating programs that do one thing well (see principle 3), these programs should do nothing else. This is the gold standard of writing intuitive and natural programs—design them as filters!
Unix Principle 10. Worse is Better
Richard Gabriel, a computer scientist well-known for his work on the programming language LISP, conceived this principle in the late eighties. Don’t take this contra-intuitive principle too literally. Worse is not actually better from a qualitative perspective. If you had infinite time and resources, it would be best to always make the program perfect in all instances. However, in a world with limited resources, worse will often be more efficient that. Launching a simple and crude solution to a problem first ensures that the launching organization builds a first-mover advantage. It attracts quick feedback from the early adopters (see Chapter 4 about minimum viable products) and gains momentum and attention early in the software development process. By launching a simple product first before optimizing and perfecting it, one can often become more sucessful than competitors because learning speed increases and the positioning in the market is clearer. Many practitioners argue that a second-mover must have a far superior product and invest far more energy only to pull away users from the first-mover. This can become quite difficult and the network effects of the first mover quickly build a “moat” around the first mover’s software product that cannot be overcome easily. This principle is similar to many principles already discussed here: simplicity, small is beautiful, build a minimum viable product, fail early and often, and take any opportunity to reduce complexity in the software development cycle.
Unix Principle 11. Clean Code is Better Than Clever Code
I slightly modified the original “Clarity is better than cleverness”, first to focus the principle to code and, second, to align it with the principles you’ve already learned how to write clean code (see Chapter 4).
This principle specifically highlights the trade-off between clean and clever code—of course, it’s great to write clever code, but it should generally not come at the costs of introducing unnecessary complexity.
def bubblesort(l): for boundary in range(len(l)-1, 0, -1): for i in range(boundary): if l[i] > l[i+1]: l[i], l[i+1] = l[i+1], l[i] return l l = [5, 3, 4, 1, 2, 0]
print(bubblesort(l))
# [0, 1, 2, 3, 4, 5]
Listing 8-15: Bubblesort algorithm in Python.
The idea of the bubblesort algorithm is to iteratively go through the list and switch the position of two adjancent elements so that those two elements can be considered sorted. The smaller element goes to the left and the larger element goes to the right. Each time that happens, the list is a bit more sorted. This is repeated many times until the whole list is sorted. The algorithm in Listing 8-15 achieves this simple strategy in a few lines of code. It’s readable, clear, and doesn’t contain unnecessary code elements.
Now, suppose your smart-ass colleague comes along and argues that you could shorten the code with the following Python trick: conditional assignments. This would allow you to express the if statement with one line of code less (see Listing 8-16).
def bubblesort_clever(l): for boundary in range(len(l)-1, 0, -1): for i in range(boundary): l[i], l[i+1] = (l[i+1], l[i]) if l[i] > l[i+1] else (l[i], l[i+1]) return l print(bubblesort_clever(l))
# [0, 1, 2, 3, 4, 5]
Wow, the code just became less readable and has lost all clarity. It still accomplishes the same task. You may even find the use of the conditional assignment feature clever—assigning one of two tuples to two neighboring list elements conditioned on which is the larger one—however, it comes at the cost of expressing your ideas with clean code. For more tips on how to write clean code, please refer to Chapter 4.
Unix Principle 13.Design Programs to Be Connected With Other Programs
The rise of web services and micro services came from the willingness to share code and build on each other’s code. Society benefits tremendously from open code bases and open interfaces because it reduces friction and investment overhead of all future code projects in the decades to come.
Your programs do not live in isolation. A program exists for a certain purpose. It is called either by a human being or by another program. That’s why you need to design the API (application programming interface) in a suitable way. You’ve already seen in principle 9 Make Any Program a Filter that choosing the intuitive input/output mapping is one way to accomplish maintainability, simplicity, and extensibility. If you write code with this principle in mind, you’ll automatically design programs to be connected with other programs rather than programs that live in isolation. The great programmer is more an architect than a coding craftsman. They create new programs as a unique combination of old and new functions and other programs which accelerates their potential to create powerful code quickly. As a result, interfaces are not a consideration that comes late in the software development cycle, but they’re front and center. A great plan on how to connect and wrap old and new programs is at the core of their craftsmanship.
Unix Principle 14. Make Your Code Robust
You’d call a thing robust—or a code base for that matter—if you cannot easily break it. There are different perspectives on breaking code: as a programmer or as a user.
As a programmer, you could potentially break code by modifying it. You’d call a code base robust against change if even a careless programmer can work on the code base without being able to easily destroy its functionality. Say, you have a big monolithic code block and every programmer in your organization is allowed to change it all. Is your code robust against change? Now, compare this to software organizations like Netflix or Google where every change has to go through multiple levels of approval before they’re deployed in the real world. You can accomplish robustness of your code base by carefully designing access rights so that individual developers are not able to destroy the application without being forced to convince at least one additional person that the change is more likely to create than destroy value—yes, it comes at a price of agility but if you’re not a one-person startup this price is worth paying. There are different additional means of making code more robust as a programmer or a software organization. You’ve already learned about some of them: small is beautiful, create functions that do one thing well, test-driven development, keeping things simple. Some more are:
Use versioning systems such as Git so that any previous version of your code can be recovered,
Backup your application data regularly because data is not part of a versioning system,
Use distributed systems to avoid a single point of failure: run your application on multiple machines rather than only on a single one because the probability of multiple machines failing reduces drastically with an increasing number of machines. Say, one machine has a failure probability of 1% per day—it’ll likely fail every 100 days. By creating a distributed system of five machines that fail independently, you can theoretically reduce your failure probability to 0.015 * 100% = 0.00000001%. Sure, machine failures are not independent—think power outages—but adding more machines has the power to increase robustness against external failure drastically.
As a user, an application feels robust if you cannot easily break it by providing faulty or even malicious inputs. You should always assume that your users will behave like a a mix of gorillas that submit random series of characters as an input for your application and highly-skilled hackers that understand the application better than you and are ready to exploit even the smallest security issue. Your application must be robust against both types of users. It’s relatively simple to shield against the former group. Unit testing is one powerful tool in your tool belt: test any function against any function input you can think of—especially considering border cases. For example, if your function takes an integer and calculates the square root—check if it can handle negative inputs because sooner or later, some users will put in negative numbers. To shield against the latter group, you must do more: use firewalls, add load balancers to protect against DDOS attacks, manage access rights carefully, avoid single points of failures, don’t store passwords in files, and so on. If your application is still small, you usually don’t need to optimize for security if you have written simple and clean code. The downside risks are minimal and you don’t have a lot of exploits, yet. But as you grow, you must carefully improve the security of your system because more and more hackers will attack your application and exploit any weakness they can lie their hands on.
The book “From One to Zero” will appear in 2021 at NoStarch. Be sure to stay updated and join my free email academy to download Python cheat sheets and consume hundreds of personalized email lessons to make you a better coder!
Python’s built-in getattr(object, string) function returns the value of the object‘s attribute with name string. If this doesn’t exist, it returns the value provided as an optional third default argument. If that doesn’t exist either, it raises an AttributeError. An example is getattr(porsche, 'speed') which is equivalent to porsche.speed.
Usage
Learn by example! Here’s an example on how to use the getattr()built-in function.
# Define class with one attribute
class Car: def __init__(self, brand, speed): self.brand = brand self.speed = speed # Create object
porsche = Car('porsche', 100)
tesla = Car('tesla', 110) # Two alternatives to get instance attributes:
print(getattr(porsche, 'brand') + " " + str(getattr(porsche, 'speed')))
print(tesla.brand + " " + str(tesla.speed)) # Get an attribute that doesn't exist with default argument:
print(getattr(porsche, 'color', 'red'))
The output of this code snippet is:
porsche 100
tesla 110
red
Syntax getattr()
The getattr() object has the following syntax:
Syntax: getattr(object, attribute[, default]) # Get object's attribute value or default if non-existent
Arguments
object
The object from which the attribute value should be drawn.
attribute
The attribute name as a string.
default
The return value in case the attribute doesn’t exist.
Return Value
object
Returns the value of the attribute of instance object or default if non-existent.
Video getattr()
Return value from getattr()
The getattr(object, attribute, default) method returns one of the following:
the value of the object‘s attribute
default, if the attribute doesn’t exist
AttributeError if neither the attribute exists, nor default is provided.
But before we move on, I’m excited to present you my brand-new Python book Python One-Liners (Amazon Link).
If you like one-liners, you’ll LOVE the book. It’ll teach you everything there is to know about a single line of Python code. But it’s also an introduction to computer science, data science, machine learning, and algorithms. The universe in a single line of Python!
The book is released in 2020 with the world-class programming book publisher NoStarch Press (San Francisco).
Why Using getattr() Instead of Dot to Get an Attribute?
You’ve seen two alternatives to get an attribute:
getattr(object, attribute_str)
object.attribute
Why using the getattr() function over the more concise dot syntax?
There are two main reasons:
getattr() provides a default value in case the attribute doesn’t exist whereas the dot syntax throws an error.
getattr() allows to dynamically access the attribute with the string instead of the name. For example, you may obtain the string as a user input, in which case, you cannot use the dot syntax object.attribute because attribute is a string, not a name.
Related Functions
The setattr() function returns the value of an attribute.
The hasattr() function checks if an attribute exists.
The delattr() function deletes an existing attribute.
Summary
Python’s built-in getattr(object, string) function returns the value of the object‘s attribute with name string.
# Define class with one attribute
class Car: def __init__(self, brand, speed): self.brand = brand self.speed = speed porsche = Car('porsche', 100)
print(getattr(porsche, 'brand') + " " + str(getattr(porsche, 'speed')))
# porsche 100
If this doesn’t exist, it returns the value provided as an optional third default argument.
print(getattr(porsche, 'color', 'red'))
# red
If that doesn’t exist either, it raises an AttributeError.
print(getattr(porsche, 'color')) '''
Traceback (most recent call last): File "C:\Users\xcent\Desktop\Finxter\Blog\HowToConvertBooleanToStringPython\code.py", line 12, in <module> print(getattr(porsche, 'color'))
AttributeError: 'Car' object has no attribute 'color' '''
An example is getattr(porsche, 'speed') which is equivalent to porsche.speed.
print(getattr(porsche, 'speed'))
print(porsche.speed)
# Both print attribute value: 100
I hope you enjoyed the article! To improve your Python education, you may want to join the popular free Finxter Email Academy:
Do you want to boost your Python skills in a fun and easy-to-consume way? Consider the following resources and become a master coder!
Where to Go From Here?
Enough theory, let’s get some practice!
To become successful in coding, you need to get out there and solve real problems for real people. That’s how you can become a six-figure earner easily. And that’s how you polish the skills you really need in practice. After all, what’s the use of learning theory that nobody ever needs?
Practice projects is how you sharpen your saw in coding!
Do you want to become a code master by focusing on practical code projects that actually earn you money and solve problems for people?
Then become a Python freelance developer! It’s the best way of approaching the task of improving your Python skills—even if you are a complete beginner.