Imagine this: You’re in your Tesla, going from your home to the sunny beaches by the Mediterranean Sea. You feel sleepy, so you take a nap. The car drives all by itself – through big highways, twisty mountain roads, and busy towns. It stops at lights, changes lanes, and parks when you get there. Wow!
Right now, people in places like America, China, Australia, and New Zealand can use it.
But in Europe, it’s not ready yet because of strict rules about car safety.
Tesla is working super hard to get permission. They are talking a lot with people in charge in the Netherlands.
Tesla hopes to show in February 2026 that FSD is safe.
If it works there, other European countries might say yes too!
To show everyone how good it is, Tesla is giving free rides right now. You sit in the passenger seat while a Tesla worker drives, and the car does the work. These rides started in Germany, France, and Italy.
So many people wanted to try it that Tesla made it longer — until the end of March 2026! Now it’s also in Denmark and Switzerland.
People who tried it say it’s amazing.
The car drives smoothly in narrow streets, busy cities, and even construction zones. It’s still “supervised,” which means a person has to watch, but it’s way smarter than regular driving help.
Europe has tough rules to keep roads safe, and that’s good!
But Tesla says FSD can make roads even safer because it doesn’t get tired or distracted like people sometimes do.
So, when can you nap on the way to the Mediterranean? Probably early 2026, if everything goes well. Hang on, European Tesla friends — it’s coming soon!
Disclaimer: We used Grok for some of the image material and content.
I published this post in my AI newsletter (130k subs). You can join for free here.
I just discovered this AI startup idea from Reddit. Will it be the next unicorn after Cursor ($30B valuation)?
Note that ideas are cheap, execution is king.
To the best of my knowledge, this idea hasn’t been implemented yet. But I thought I’d share it with the Finxter community so I can brag about it as soon as somebody takes it and reaches unicorn status.
~~~
Idea: Create a free vibe coding IDE that shows ads while waiting for agents to complete.
“The free vibe coding IDE that pays for its own GPT-5.2 tokens”
Here’s a pitch deck I created with Gemini Banana Pro (comic style):
Some features:
Monetize idle time
Waiting is a sustainable business thesis for AI
TAM is 1B vibe coders
Bonus: Ads pay for AI tokens
I hope that somebody from the Finxter community takes this idea and runs with it. I’ll be here to share v1 with the community for free (130k readers). Let’s go.
Be on the right side of change! Chris
PS: Join our community for AI builders. It’s fun and our goal is for each member to ship one AI project each month.
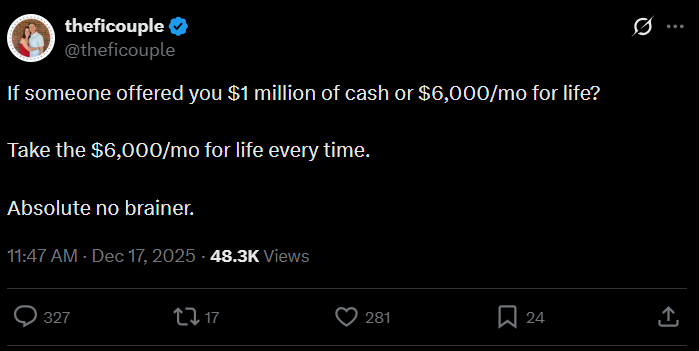
Post: “If someone offered you $1 million of cash or $6,000/mo for life? Take the $6,000/mo for life every time. Absolute no brainer.”
I was stunned that most people didn’t seem to understand that this is not the best option.
So, which option is better:
Choosing $1M now, or
$6,000 per month for life?
To answer this mission-critical question, I ran an analysis. Here it is:
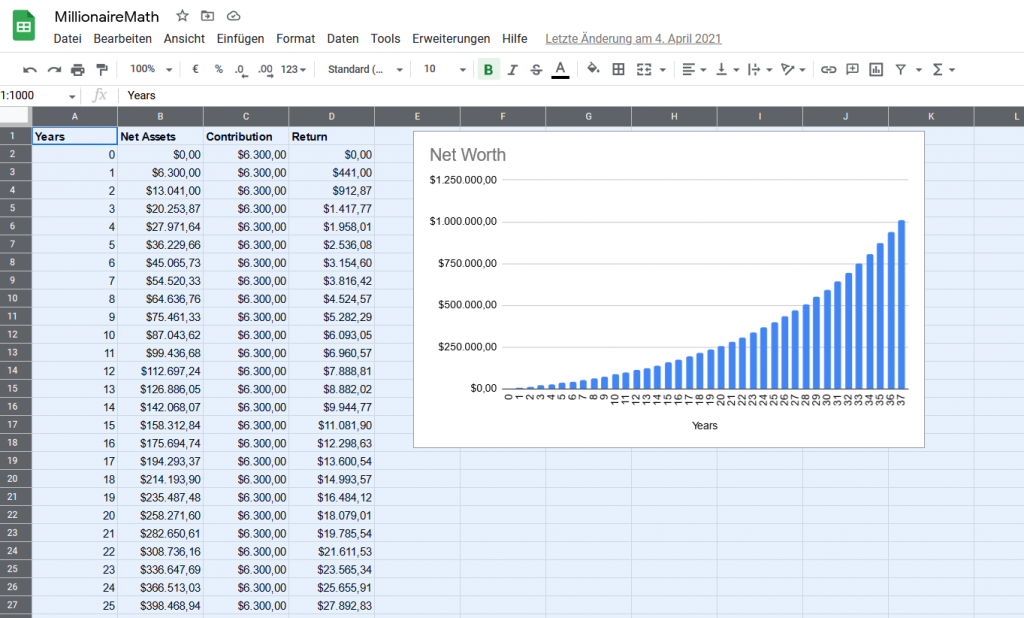
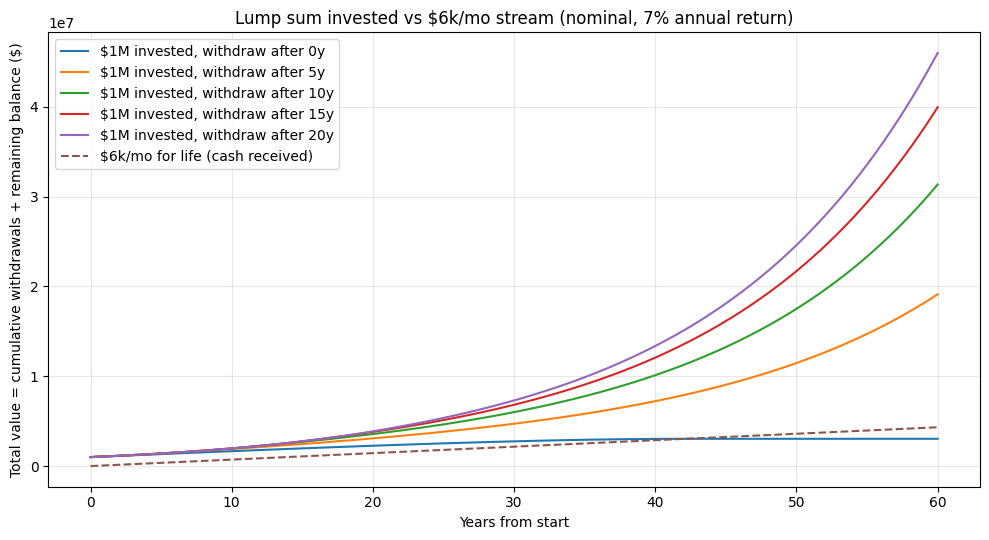
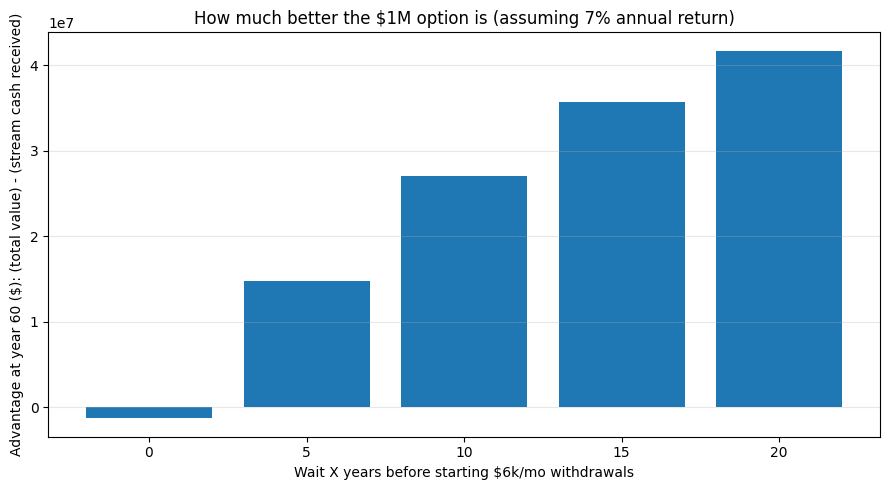
$1M invested starts growing immediately. If you don’t touch it for X years (see chart), you can later withdraw $6k/m and still end up with WAY more money.
The monthly deal looks safe but it’s trading away the compounding engine (the $1M) for a fixed paycheck.
You can also see this graphic for which option is better:
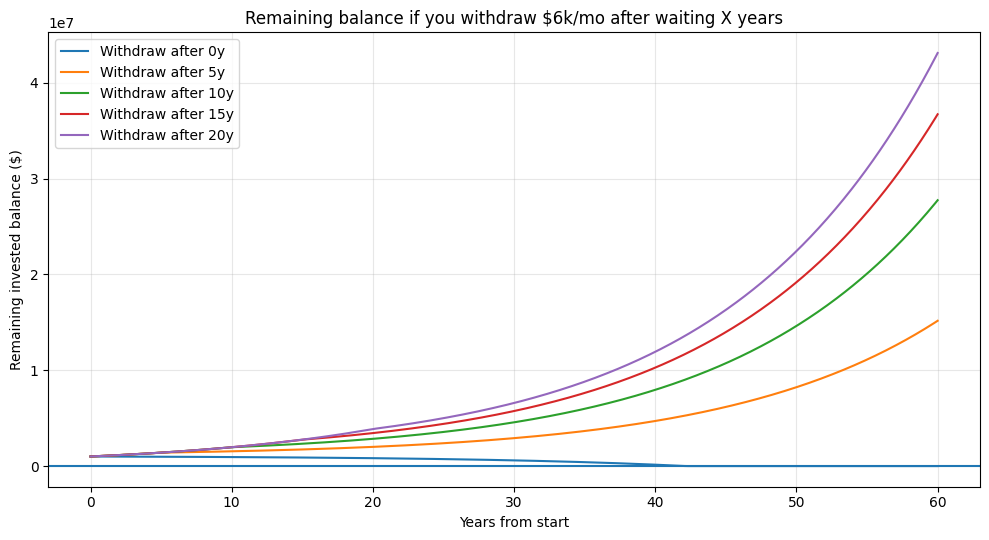
Key takeaways:
If you start withdrawing immediately ($6k/mo), you’re taking $72k/yr = 7.2% of $1M. With a 7% return, the portfolio eventually depletes (in this simulation: around year ~42).
If you wait even 5–10 years before starting withdrawals, the account grows enough that the $6k/mo becomes easily sustainable, and you end up with a huge remaining balancewhile also receiving the same $6k/mo thereafter.
Compared to the “$6k/month stream” (which leaves you with no asset), the “$1M then withdraw later” strategy produces dramatically higher total value = (cash withdrawn + remaining balance).
As we gear up for 2026, I’m streamlining my coding workflow with a lean, vibe-aligned stack that focuses on simplicity and scalability (I have many projects!). It’s perfect for solo devs or small teams building dynamic web apps.
This stack might not be perfect if you work in a large corporation or something. You might want to use Cursor and other tools as well. Here’s the breakdown, tool by tool.
OpenAI – Codex and Research
OpenAI powers my core ideation phase with Codex for rapid code generation and research tools for deep dives into algorithms or APIs. It’s like having a tireless co-pilot that turns vague concepts into functional prototypes, saving hours on boilerplate and letting me focus on the fun, innovative bits.
Gemini App – Visuals and Infographics
For visuals and infographics, Gemini App is my go-to—it’s intuitive for whipping up charts, diagrams, and UI mockups that make complex data pop. Whether I’m explaining a new feature or prepping client decks, its drag-and-drop magic ensures polished outputs without the Photoshop slog.
GitHub – Project Management and Deployment Pipeline
GitHub handles all project management and deployment pipelines with its robust repo features, Actions for CI/CD, and seamless collaboration tools. It’s the central hub where ideas branch, merge, and ship, keeping everything versioned and automated for zero-downtime releases.
Heroku – Hosting
Heroku simplifies hosting with one-click deploys and auto-scaling, ideal for spinning up full-stack apps without server wrangling. Its free tier for testing and easy add-ons for extras like logging make it a no-brainer for quick iterations and reliable uptime.
MariaDB – Database for Dynamic Web Apps
MariaDB anchors my dynamic web apps as a robust, open-source database that’s MySQL-compatible but faster and more feature-rich. It excels at handling relational data for user auth, content management, or e-commerce backends, with easy scaling for growing traffic.
FastSpring – Payments (VAT and Sales Tax Handling)
Payments flow through FastSpring for its global compliance magic, auto-handling VAT, sales tax, and subscriptions across 200+ countries. It’s plug-and-play for monetizing apps, reducing legal headaches so I can prioritize product over paperwork.
Namecheap – Domains
Namecheap locks in domains with affordable, straightforward registration and privacy protection. Quick WHOIS guards and easy transfers keep my online presence secure and branded, without the upsell drama of bigger registrars.
Easily combine two CSV files into one without any downloads or complex software — just upload and merge in your browser. Perfect for quickly appending data from multiple spreadsheets.
How It Works: Upload your primary CSV (the one with the header row you’ll keep) as the first file. Then select the second CSV to append its rows below.
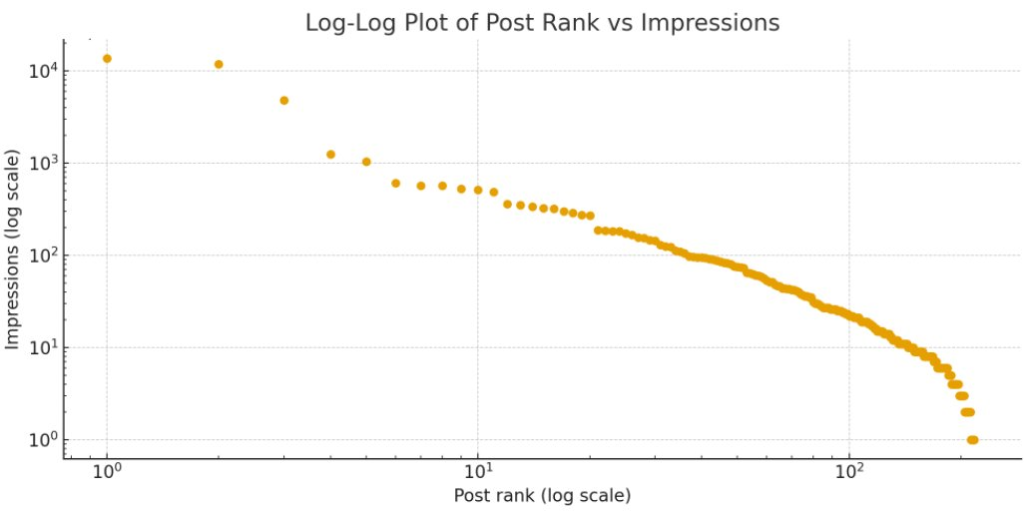
My very limited time on X has already shown that posts ranked by number of expression is highly non-linear. Maybe Zipf or Pareto distributed?
The first plot shows each post sorted by impressions (rank 1 = most impressions). You’ll see a steep drop from the top few posts, then a long tail of low-impression posts.
The point is:
post more stuff
most posts will fail or get ~zero impressions
some posts make all the difference
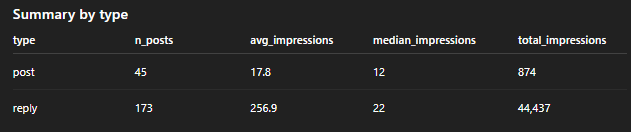
~20% of Posts/Replies Generate ~80% of the Impressions
Post ranked by impressions is not quite Pareto distributed (would be a straight line):
The log–log plot shows rank and impressions on logarithmic axes. If the points roughly line up on a straight downward-sloping line, that’s a classic power-law–like pattern.
The distribution looks heavy-tailed – a small number of posts carry a large share of total impressions.
Don’t Post – Be a Reply Guy
Also, replies have a much higher number of average impressions as compared to original posts. Smaller accounts should prioritize replies over posts.
If you want to grow your X account quickly, the best approach seems to be to reply to larger accounts. What to reply? Everything that comes to your mind. Just your authentic quick commentary. Don’t bother using AI – you’ll be too slow. Just use whatever comes to mind and increase your volume.
If you want to learn more on how using AI can improve your life, check out my free newsletter with 130k subscribers!
Problem Formulation: How can users reliably tell whether an image was created by a human or generated by AI? Specifically, with Gemini Nano Banana Pro and other recent image generation tools, you never know if a screenshot, scientific paper result, chart, or person is real or AI-generated.
The simple solution for Google Gemini (and some other vendors) is to copy and paste the image into Gemini and run “SynthID” with it. This is a complex watermark technique that works for most images. However, it doesn’t work in very important application areas as shown in Example 3.
Here are a few examples:
Example 1: Gemini-Generated Image Detected
I created this thumbnail image for one of my recent YouTube videos and SynthID correctly classifies it as AI-generated.
Example 2: ChatGPT-Generated Image Not Detected
I created this image with ChatGPT in a recent query about a health question, so it was not generated by Google Gemini Banana Pro. It correctly classified it as not generated by Google but does not rule out that it was generated by AI.
Example 3: Gemini-Generated Image Not Detected
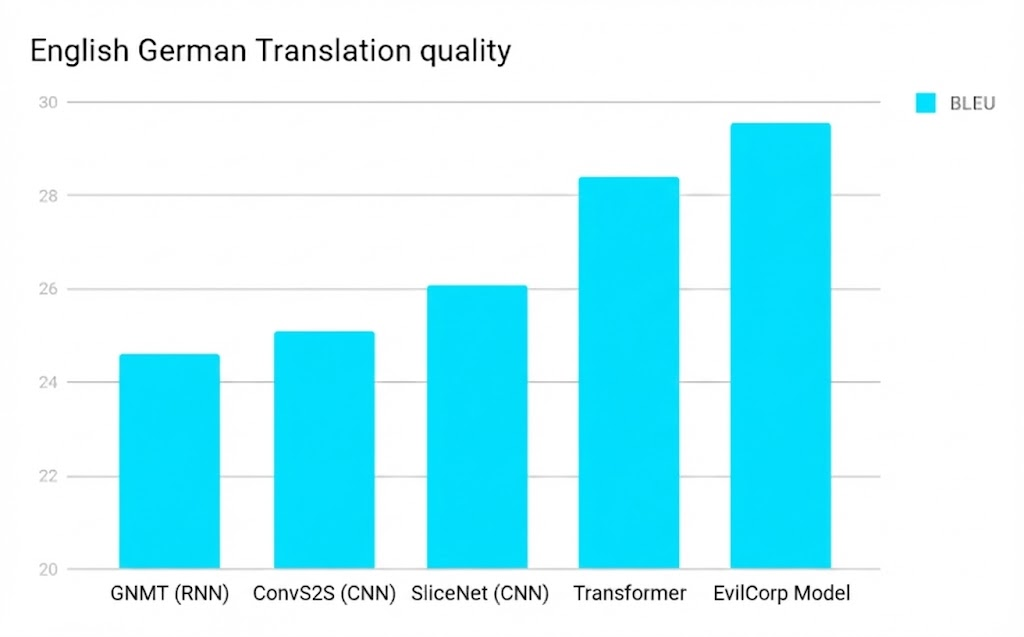
Have a look at these two images – can you spot the difference?
Image 2: Fake image generated by Gemini Banana Pro
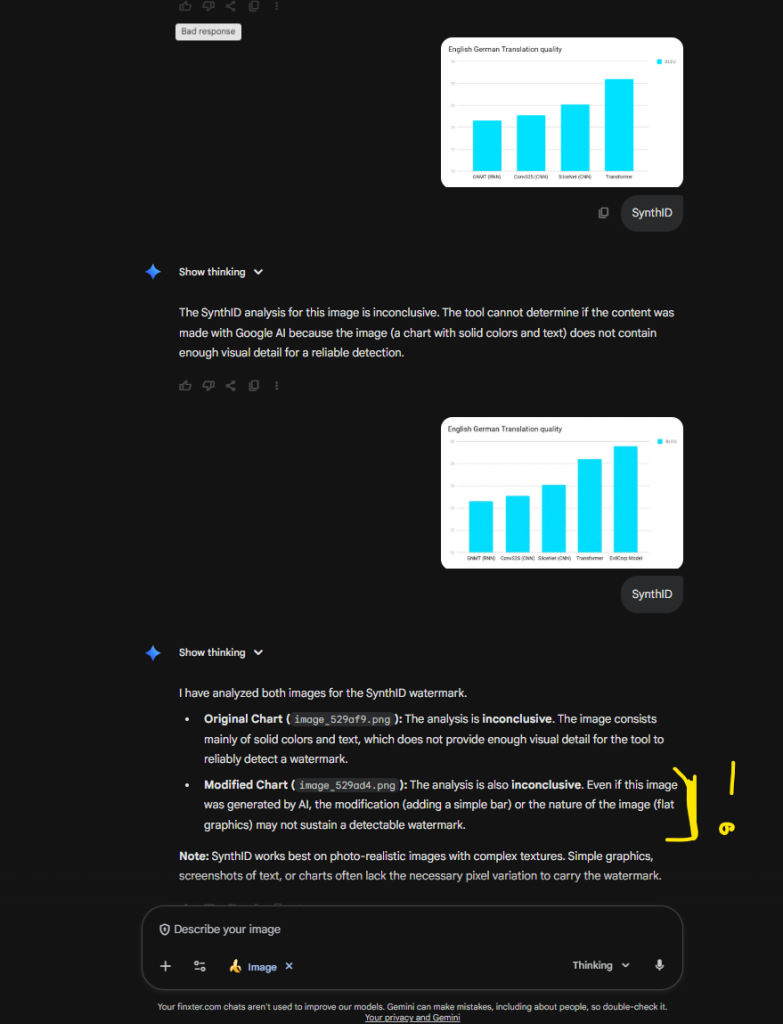
Unfortunately, SynthID was not able to determine if one was AI-generated. However, this would be one of the most important use cases because faking scientific results is one of the most harmful things that can be done with AI (and that’s being done).
See this chat confirming the inability of Gemini to determine if it was AI generated:
When working with lists that contain Unicode strings, you may encounter characters that make it difficult to process or manipulate the data or handle internationalized content or content with emojis . In this article, we will explore the best ways to remove Unicode characters from a list using Python.
You’ll learn several strategies for handling Unicode characters in your lists, ranging from simple encoding techniques to more advanced methods using list comprehensions and regular expressions.
Understanding Unicode and Lists in Python
Combining Unicode strings and lists in Python is common when handling different data types. You might encounter situations where you need to remove Unicode characters from a list, for instance, when cleaning or normalizing textual data.
Unicode is a universal character encoding standard that represents text in almost every writing system used today. It assigns a unique identifier to each character, enabling the seamless exchange and manipulation of text across various platforms and languages. In Python 2, Unicode strings are represented with the u prefix, like u'Hello, World!'. However, in Python 3, all strings are Unicode by default, making the u prefix unnecessary.
Lists are a built-in Python data structure used to store and manipulate collections of items. They are mutable, ordered, and can contain elements of different types, including Unicode strings.
For example:
my_list = ['Hello', u'世界', 42]
While working with Unicode and lists in Python, you may discover challenges related to encoding and decoding strings, especially when transitioning between Python 2 and Python 3. Several methods can help you overcome these challenges, such as encode(), decode(), and using various libraries.
Method 1: ord() for Unicode Character Identification
One common method to identify Unicode characters is by using the isalnum() function. This built-in Python function checks if all characters in a string are alphanumeric (letters and numbers) and returns True if that’s the case, otherwise False. When working with a list, you can simply iterate through each string item and use isalnum() to determine if any Unicode characters are present.
The isalnum() function in Python checks whether all the characters in a text are alphanumeric (i.e., either letters or numbers) and does not specifically identify Unicode characters. Unicode characters can also be alphanumeric, so isalnum() would return True for many Unicode characters.
To identify or work with Unicode characters in Python, you might use the ord() function to get the Unicode code of a character, or \u followed by the Unicode code to represent a character. Here’s a brief example:
# Using \u to represent a Unicode character
unicode_char = '\u03B1' # This represents the Greek letter alpha (α) # Using ord() to get the Unicode code of a character
unicode_code = ord('α') print(f"The Unicode character for code 03B1 is: {unicode_char}")
print(f"The Unicode code for character α is: {unicode_code}")
In this example:
\u03B1 is used to represent the Greek letter alpha (α) using its Unicode code.
ord('α') returns the Unicode code for the Greek letter alpha, which is 945.
If you want to identify whether a string contains non-ASCII characters (which might be what you’re interested in when you talk about identifying Unicode characters), you might use something like the following code:
def contains_non_ascii(s): return any(ord(char) >= 128 for char in s) # Example usage:
s = "Hello α"
print(contains_non_ascii(s)) # Output: True print(contains_non_ascii('Hello World')) # Output: False
In this function, contains_non_ascii(s), it checks each character in the string s to see if it has a Unicode code greater than or equal to 128 (i.e., it is not an ASCII character). If any such character is found, it returns True; otherwise, it returns False.
Method 2: Regex for Unicode Identification
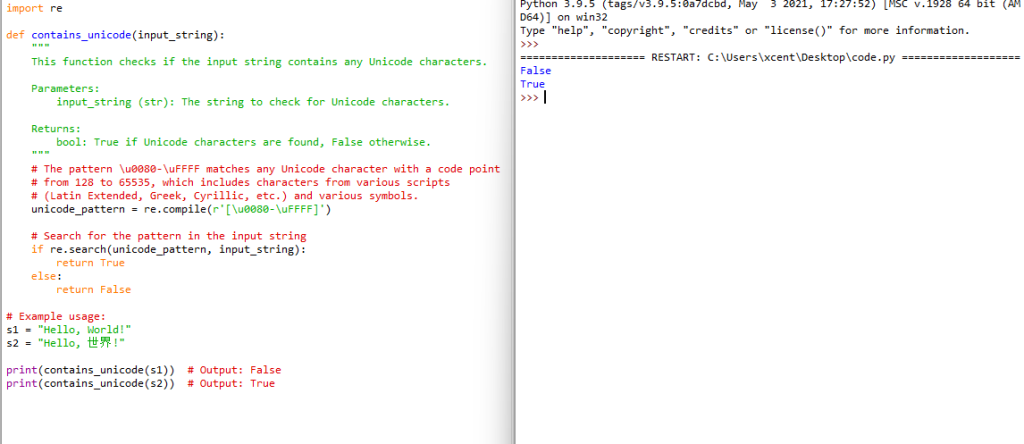
Using regular expressions (regex) is a powerful way to identify Unicode characters in a string. Python’s re module can be utilized to create patterns that can match Unicode characters. Below is an example method that uses a regular expression to identify whether a string contains any Unicode characters:
import re def contains_unicode(input_string): """ This function checks if the input string contains any Unicode characters. Parameters: input_string (str): The string to check for Unicode characters. Returns: bool: True if Unicode characters are found, False otherwise. """ # The pattern \u0080-\uFFFF matches any Unicode character with a code point # from 128 to 65535, which includes characters from various scripts # (Latin Extended, Greek, Cyrillic, etc.) and various symbols. unicode_pattern = re.compile(r'[\u0080-\uFFFF]') # Search for the pattern in the input string if re.search(unicode_pattern, input_string): return True else: return False # Example usage:
s1 = "Hello, World!"
s2 = "Hello, 世界!" print(contains_unicode(s1)) # Output: False
print(contains_unicode(s2)) # Output: True
Explanation:
[\u0080-\uFFFF]: This pattern matches any character with a Unicode code point from U+0080 to U+FFFF, which includes various non-ASCII characters.
re.search(unicode_pattern, input_string): This function searches the input string for the defined Unicode pattern.
If the pattern is found in the string, the function returns True; otherwise, it returns False.
This method will help you identify strings containing Unicode characters from various scripts and symbols. This pattern does not match ASCII characters (code points U+0000 to U+007F) or non-BMP characters (code points above U+FFFF).
If you want to learn about Python’s search() function in regular expressions, check out my tutorial and tutorial video:
Method 3: Encoding and Decoding for Unicode Removal
When dealing with Python lists containing Unicode characters, you might find it necessary to remove them. One effective method to achieve this is by using the built-in string encoding and decoding functions. This section will guide you through the process of Unicode removal in lists by employing the encode() and decode() methods.
First, you will need to encode the Unicode string into the ASCII format. It is essential because the ASCII encoding only supports ASCII characters, and any Unicode characters that are outside the ASCII range will be automatically removed. For this, you can utilize the encode() function with its parameters set to the ASCII encoding option and error handling set to 'ignore'.
After encoding the string to ASCII, it is time to decode it back to a UTF-8 format. This step is essential to ensure the list items retain their original text data and stay readable. You can use the decode() function to achieve this conversion. Here’s an example:
string_utf8 = string_ascii.decode('utf-8')
Now that you have successfully removed the Unicode characters, your Python list will only contain ASCII characters, making it easier to process further. Let’s take a look at a practical example with a list of strings.
list_unicode = ["𝕴 𝖆𝖒 𝕴𝖗𝖔𝖓𝖒𝖆𝖓!", "This is an ASCII string", "𝕿𝖍𝖎𝖘 𝖎𝖘 𝖚𝖓𝖎𝖈𝖔𝖉𝖊"]
list_ascii = [item.encode('ascii', 'ignore').decode('utf-8') for item in list_unicode] print(list_unicode)
# ['𝕴 𝖆𝖒 𝕴𝖗𝖔𝖓𝖒𝖆𝖓!', 'This is an ASCII string', '𝕿𝖍𝖎𝖘 𝖎𝖘 𝖚𝖓𝖎𝖈𝖔𝖉𝖊'] print(list_ascii)
# [' !', 'This is an ASCII string', ' ']
In this example, the list_unicode variable comprises three different strings, two with Unicode characters and one with only ASCII characters. By employing a list comprehension, you can apply the encoding and decoding process to each string in the list.
Remember always to be careful when working with Unicode texts. If the string with Unicode characters contains crucial information or an essential part of the data you are processing, you should consider keeping the Unicode characters and using proper Unicode-compatible solutions.
Method 4: The Replace Function for Unicode Removal
When working with lists in Python, it is common to come across Unicode characters that need to be removed or replaced. One technique to achieve this is by using Python’s replace() function.
The replace() function is a built-in method in Python strings, which allows you to replace occurrences of a substring within a given string. To remove specific Unicode characters from a list, you can first convert the list elements into strings, then use the replace() function to handle the specific Unicode characters.
When dealing with a larger set of Unicode characters, you can use a dictionary to map each character to be replaced with its replacement. For example:
unicode_replacements = { "ó": "o", "ö": "o", "é": "e", # Add more replacements as needed.
} original_list = ["Róisín", "Björk", "Héctor"]
new_list = [] for item in original_list: for key, value in unicode_replacements.items(): item = item.replace(key, value) new_list.append(item) print(new_list) # ['Roisin', 'Bjork', 'Hector']
Of course, this is only useful if you have specific Unicode characters to remove. Otherwise, use the previous Method 3.
Method 5: Regex Substituion for Replacing Non-ASCII Characters
When working with text data in Python, non-ASCII characters can often cause issues, especially when parsing or processing data. To maintain a clean and uniform text format, you might need to deal with these characters and remove or replace them as necessary.
One common technique is to use list comprehension coupled with a character encoding method such as .encode('ascii', 'ignore'). You can loop through the items in your list, encode them to ASCII, and ignore any non-ASCII characters during the encoding process. Here’s a simple example:
data_list = ["𝕴 𝖆𝖒 𝕴𝖗𝖔𝖓𝖒𝖆𝖓!", "Hello, World!", "你好!"]
clean_data_list = [item.encode("ascii", "ignore").decode("ascii") for item in data_list]
print(clean_data_list)
# Output: [' m mn!', 'Hello, World!', '']
In this example, you’ll notice that non-ASCII characters are removed from the text, leaving the ASCII characters intact. This method is both clear and easy to implement, which makes it a reliable choice for most situations.
Another approach is to use regular expressions to search for and remove all non-ASCII characters. The Python re module provides powerful pattern matching capabilities, making it an excellent tool for this purpose. Here’s an example that shows how you can use the re module to remove non-ASCII characters from a list:
import re data_list = ["𝕴 𝖆𝖒 𝕴𝖗𝖔𝖓𝖒𝖆𝖓!", "Hello, World!", "你好!"]
ascii_only_pattern = re.compile(r"[^\x00-\x7F]")
clean_data_list = [re.sub(ascii_only_pattern, "", item) for item in data_list]
print(clean_data_list) # Output: [' !', 'Hello, World!', '']
In this example, we define a regular expression pattern that matches any character outside the ASCII range ([^\x00-\x7F]). We then use the re.sub() function to replace any matching characters with an empty string.
Frequently Asked Questions
How can I efficiently replace Unicode characters with ASCII in Python?
To efficiently replace Unicode characters with ASCII in Python, you can use the unicodedata library. This library provides the normalize() function which can convert Unicode strings to their closest ASCII equivalent. For example:
import unicodedata def unicode_to_ascii(s): return ''.join(c for c in unicodedata.normalize('NFD', s) if unicodedata.category(c) != 'Mn')
This function will replace Unicode characters with their ASCII equivalents, making your Python list easier to work with.
What are the best methods to remove Unicode characters in Pandas?
Pandas has a built-in method that helps you remove Unicode characters in a DataFrame. You can use the applymap() function in conjunction with the lambda function to remove any non-ASCII character from your DataFrame. For example:
import pandas as pd data = {'col1': [u'こんにちは', 'Pandas', 'DataFrames']}
df = pd.DataFrame(data) df = df.applymap(lambda x: x.encode('ascii', 'ignore').decode('ascii'))
This will remove all non-ASCII characters from the DataFrame, making it easier to process and analyze.
How do I get rid of all non-English characters in a Python list?
To remove all non-English characters in a Python list, you can use list comprehension and the isalnum() function from the str class. For example:
data = [u'こんにちは', u'Hello', u'안녕하세요'] result = [''.join(c for c in s if c.isalnum() and ord(c) < 128) for s in data]
This approach filters out any character that isn’t alphanumeric or has an ASCII value greater than 127.
What is the most effective way to eliminate Unicode characters from an SQL string?
To eliminate Unicode characters from an SQL string, you should first clean the data in your programming language (e.g., Python) before inserting it into the SQL database. In Python, you can use the re library to remove Unicode characters:
import re def clean_sql_string(s): return re.sub(r'[^\x00-\x7F]+', '', s)
This function will remove any non-ASCII characters from the string, ensuring that your SQL query is free of Unicode characters.
How can I detect and handle Unicode characters in a Python script?
To detect and handle Unicode characters in a Python script, you can use the ord() function to check if a character’s Unicode code point is outside the ASCII range. This allows you to filter out any Unicode characters in a string. For example:
def is_ascii(s): return all(ord(c) < 128 for c in s)
You can then handle the detected Unicode characters accordingly, such as using replace() to substitute them with appropriate ASCII characters or removing them entirely.
What techniques can be employed to remove non-UTF-8 characters from a text file using Python?
To remove non-UTF-8 characters from a text file using Python, you can use the following method:
Open the file in binary mode.
Decode the file’s content with the ‘UTF-8’ encoding, using the ‘ignore’ or ‘replace’ error handling mode.
Write the decoded content back to the file.
with open('file.txt', 'rb') as file: content = file.read() cleaned_content = content.decode('utf-8', 'ignore') with open('cleaned_file.txt', 'w', encoding='utf-8') as file: file.write(cleaned_content)
This will create a new text file without non-UTF-8 characters, making your data more accessible and usable.
Clayton Christensen’s “Disruptive Innovation Model” refers to a theory that explains how smaller companies can successfully challenge established incumbent businesses. Here’s a detailed breakdown:
Disruptive Innovation refers to a new technology, process, or business model that disrupts an existing market. Disruptive innovations often start as simpler, cheaper, and lower-quality solutions compared to existing offerings. They often target an underserved or new market segment. They often create a different value network within the market. However, truly disruptive innovation companies improve over time and eventually displace existing market participants.
In fact, there are two general types of disruptive innovation models:
Low-End Disruption: Targets the least profitable customers who are typically overserved by the incumbent’s existing offering.
New-Market Disruption: Targets customers with needs previously unserved by existing incumbents. You may have heard of the “blue ocean strategy”.
Low-end disruption is exemplified by Southwest Airlines and BIC Disposable Razors. Southwest Airlines disrupted the aviation industry by focusing on providing basic, reliable, and cost-effective air travel, appealing to price-sensitive customers and those who might opt for alternative transportation. BIC, on the other hand, introduced affordable disposable razors, offering a satisfactory solution for customers unwilling to pay a premium for high-end razors, thereby securing a substantial market share.
In terms of new-market disruption, Tesla Motors and Coursera stand out. Tesla targeted environmentally conscious consumers, offering electric vehicles that didn’t compromise on performance or luxury, creating a new market for high-performance electric vehicles and prompting other manufacturers to expedite their EV programs. After introducing the high-end luxury cars, Tesla subsequently moved down market and even announced in the “Master Plan Part 3” that they plan to release a $25k electric car. Coursera disrupted the traditional educational model by providing online courses from renowned universities to a global audience, creating a new market for online education.
The Blue Ocean Strategy, which is somewhat related to new-market disruption, emphasizes innovating and creating new demand in unexplored market areas, or “Blue Oceans”, instead of competing in saturated markets, or “Red Oceans”. An example of this strategy is the Nintendo Wii, which carved out a new market space by targeting casual gamers with simpler, family-friendly games and innovative controllers, thereby reaching an entirely new demographic of consumers and avoiding direct competition with powerful gaming consoles like Xbox and PlayStation.
The disruptive innovation process often plays out like so:
Introduction: The innovation is introduced, often with skepticism from established players.
Evolution: The innovation evolves and improves, gradually becoming more appealing to a wider customer base.
Disruption: The innovation becomes good enough to meet the needs of most customers, disrupting the status quo.
Domination: The innovators often come to dominate the market, replacing the previous incumbents.
Technological advancements typically undergo an S-curve progression, as seen with smartphones, which experienced slow initial adoption, followed by rapid uptake, and eventually, market saturation.
Companies often align innovations with their existing value networks, ensuring new products resonate with their established customer base, like how Apple’s product ecosystem is meticulously designed to ensure customer retention and continuous engagement.
The implications of disruptive innovation are profound, with established companies, such as Kodak, often facing dilemmas and organizational inertia in adopting new technologies due to a deep-rooted focus on existing offerings and customer bases.
To navigate through disruptive waters, incumbents might employ strategies like establishing separate units dedicated to innovation, akin to how Google operates Alphabet to explore varied ventures, adopting agile methodologies for nimble operations, and maintaining a relentless focus on evolving customer needs to stay relevant and competitive in the market.
Here’s my personal key take-away (not financial advice):
It is tough to create a huge disruptive startup. It is easy to disrupt a tiny niche.
A great strategy that I found extremely profitable is to focus on a tiny niche within your career, keep optimizing daily, and invest your income in star businesses, i.e., disruptive innovation companies in high-growth markets (>10% per year) that are also market leaders.
Only invest in companies or opportunities that are both, in a high-growth market and leader of this market.
Bitcoin, for example, is the leader of a high-growth market (=digital store of value). Tesla, another example, is the leader of a high-growth market (=autonomous electric vehicles).
A Short Primer on the Star Principle — And How It’ll Make You Rich
The Star Principle, articulated by Richard Koch, underscores the potency of investing in or creating a ‘star venture’ to amass wealth and success in business.
A star venture is characterized by two pivotal attributes: (1) it is a leader in a high-growth market and (2) it operates within a niche that is expanding rapidly.
The allure of a star business emanates from its ability to combine niche leadership with high niche growth, enabling it to potentially command price premiums, lower costs, and subsequently, attain higher profits and cash flow.
The principle asserts that positioning is the key to success, provided that the positioning is truly exceptional and the venture is a star business. However, it’s imperative to note that star ventures are not devoid of risks; the primary pitfall being the loss of leadership within its niche, which can drastically diminish its value.
While star ventures are relatively rare, with perhaps one in twenty startups being a star, they are not so scarce that they cannot be discovered or created with thoughtful consideration and patience.
The principle emphasizes that whether you are an employee, an aspiring venture leader, or an investor, aligning yourself with a star venture can pave the way to a prosperous and enriched life.
Here’s a list of 20 example star businesses from the past (some are still stars ):
Apple: Dominates various tech niches, offering premium products that command higher prices.
Amazon: A leader in e-commerce and cloud computing, consistently expanding into new markets.
Google (Alphabet): Dominates the search engine market and has successful ventures like YouTube.
Facebook (Meta): Leads in social media through platforms like Facebook, Instagram, and WhatsApp.
Microsoft: A leader in software, cloud services, and hardware, with a vast, growing ecosystem.
Tesla: Revolutionizing the electric vehicle market and autonomous technologies. The bot!
Netflix: A dominant player in the streaming service industry, with a massive global subscriber base.
Alibaba: A leader in e-commerce, cloud computing, and various other sectors in China and globally.
Shopify: A giant in the e-commerce platform space, enabling myriad online stores globally.
Zoom: Became essential for virtual communication, especially during the pandemic, and continues to grow.
Spotify: Leading the music streaming industry with a vast library and substantial subscriber base.
PayPal: A major player in the digital payments space, facilitating global e-commerce.
Adobe: Dominates several software niches, including graphic design and document management.
Salesforce: Leads in customer relationship management (CRM) software and platform technology.
NVIDIA: A dominant force in GPUs, expanding into AI, machine learning, and autonomous vehicles.
Airbnb: Revolutionized the hospitality industry, becoming a go-to platform for home-sharing.
Square: Innovating in the financial and mobile payment sectors, providing solutions for small businesses.
Uber: Despite controversies, it remains a significant player in ride-hailing and has expanded into food delivery.
Tencent: A conglomerate leader in various sectors, including social media, gaming, and fintech, particularly in China.
Samsung: A leader in various tech niches, including smartphones, semiconductors, and consumer electronics.
These businesses have demonstrated leadership in their respective niches and have experienced significant growth, aligning with the Star Principle’s criteria of operating in high-growth markets and being a leader in those markets.
Let’s dive into some practical strategies you can use as a small coding business owner to become more innovative, possibly disruptive in a step-by-step manner:
9-Step Guide to Leverage the Disruptive Innovation Model for a Small Coding Business
Step 1: Identify Underserved Needs
Imagine embarking on a journey to create a startup named “ChatHealer,” an online platform that uses Large Language Models (LLMs) and the OpenAI API to provide instant, empathetic, and anonymous conversational support for individuals experiencing stress or emotional challenges.
Step 2: Define Your Value Proposition
In the initial phase, identifying underserved needs is crucial. A thorough market research might reveal that there’s a gap in providing immediate, non-clinical emotional support to individuals in a highly accessible and non-judgmental platform.
The unique value proposition of ChatHealer would be its ability to offer instant, 24/7 emotional support through intelligent and empathetic conversational agents, ensuring user anonymity and privacy.
Step 3: Develop a Minimum Viable Product (MVP) to Validate and Iterate
The development of a Minimum Viable Product (MVP) would involve creating a basic version of ChatHealer, focusing on core functionalities like user authentication, basic conversational abilities, and ensuring data security. The MVP would be introduced to a select group of users, and their feedback would be paramount in validating and iterating the product, ensuring it aligns with user expectations and experiences.
Step 4: Utilize LLMs and AI to Scale Labor and Find a Business Model
Leveraging LLMs and AI, ChatHealer could enhance its conversational agents to understand and respond to user inputs more empathetically and contextually, providing a semblance of genuine human interaction.
The business model might adopt a freemium approach, offering basic conversational support for free while providing a premium subscription that includes additional features like personalized emotional support journeys, and perhaps, priority access to human professionals.
Step 5: Focus on Customer Experience and Scale Gradually
Ensuring a seamless and supportive customer experience would be pivotal, as the nature of ChatHealer demands a safe and nurturing environment. As the platform gains traction, gradual scaling would involve introducing ChatHealer to wider demographics and possibly integrating multilingual support to cater to a global audience.
Step 6: Continuous Improvements
Continuous improvement would be embedded in ChatHealer’s operations, ensuring that the platform evolves with technological advancements and user needs. Building partnerships, perhaps with mental health professionals and organizations, could enhance its credibility and provide a pathway for users to access further support if needed.
Step 7: Manage Finances Wisely
Prudent financial management would ensure that funds are judiciously utilized, maintaining a balance between technological development, marketing, and operations. Cultivating a culture of innovation within the team ensures that ChatHealer remains at the forefront of technological and therapeutic advancements, always exploring new ways to provide support to its users.
Adaptability would be key, as ChatHealer would need to be ready to pivot its strategies and offerings in response to user needs, technological advancements, and market trends. Ensuring that all operations, especially data handling and user interactions, adhere to legal and compliance standards would be paramount to maintain user trust and regulatory adherence.
Step 9: Measure and Analyze Throughout the Process
Lastly, employing analytics to measure and analyze user engagement, subscription conversions, and user feedback would be instrumental in shaping ChatHealer’s future strategies and innovations, ensuring that it not only remains a disruptive innovation but also a sustained, valuable service in the emotional support domain.
Case Study: Is Uber a Disruptive Innovation?
In this section, we will explore whether Uber is a disruptive innovation by examining its origins and how its quality compares to the mainstream market expectations.
Disruptive Innovations Start with Low-End or New-Market Footholds
Disruptive innovations typically begin in low-end or new-market footholds, as incumbents often focus on their most profitable and demanding customers. This focus can lead to less attention being paid to less-demanding customers, allowing disruptors to introduce products that cater to these neglected market segments.
However, Uber did not originate with either a low-end or new-market foothold. It did not start by targeting non-consumers or finding a low-end opportunity. Instead, Uber was launched in San Francisco, which already had a well-established taxi market. Its primary customers were individuals who already had the habit of hiring rides. Therefore, Uber did not follow the typical pattern of disruptive innovations that begin with low-end or new-market footholds.
Quality Must Align with Mainstream Expectations in Disruptive Innovations
Disruptive innovations are initially perceived as inferior in comparison to the offerings by established companies. Mainstream customers are hesitant to adopt these new, typically cheaper, alternatives until their quality satisfies their expectations.
In the case of Uber, most elements of its strategy appear to be sustaining innovations. Its service is often regarded as equal or superior to existing taxi services, with convenient booking, cashless payments, and a passenger rating system. Additionally, Uber generally offers competitive pricing and reliable service. In response to Uber, established taxi companies have implemented similar technologies and challenged the legality of some of Uber’s offerings.
Based on these factors, Uber cannot be considered a true disruptive innovation. While it has certainly impacted the taxi market and incited changes among traditional taxi companies, it did not originate from classic low-end or new-market footholds, and its service quality aligns with mainstream expectations rather than being perceived as initially inferior.
Frequently Asked Questions
What makes disruptive innovation different from regular innovations?
Disruptive innovation refers to a process where a smaller company with fewer resources challenges established businesses by entering at the bottom of the market and moving up-market. This is different from traditional or incremental innovations, which usually improve existing products or services for existing customers.
Can you give some examples of disruptive innovation in the healthcare sector?
Some examples of disruptive innovation in healthcare include:
Telemedicine: Remote consultations through video calls, making healthcare services more accessible.
Wearable health technology: Wearable devices that monitor and track health data, empowering individuals to take control of their health.
Electronic health records (EHR): Digitizing patient records for more efficient and secure management of information.
Which companies have successfully implemented disruptive innovation?
Some well-known companies that implemented disruptive innovation strategies include:
Netflix (transforming the way we consume video content)
Uber (redefining transportation services)
Airbnb (disrupting the hospitality industry)
Slack (changing team communication and collaboration)
Could you share some low-end disruptive innovation examples?
Low-end disruption refers to innovations targeting customers who are not well-served by the incumbent companies due to high prices or complex products. Examples include:
IKEA (providing affordable and stylish furniture)
Southwest Airlines (offering low-cost air travel)
Xiaomi (manufacturing and selling high-quality smartphones at affordable prices)
What is the process for introducing disruptive innovations?
Launching disruptive innovations typically involves the following steps:
Identify an underserved market segment or new niche.
Develop a cost-effective, simple, and efficient solution targeting this segment.
Iterate and improve the product or service offering as you learn more about customers and the market.
Gradually move up-market, improving the product or service as it gains traction and market share.
Can you provide examples of new market disruptions?
New market disruptions typically create entirely new markets that did not exist before. Examples include:
E-commerce platforms like Amazon (creating a massive online marketplace)
Social media platforms like Facebook (connecting people worldwide and creating an advertising market)
Streaming music services like Spotify (transforming how individuals listen to music and generating revenue through subscriptions and ads)
If you want to keep learning disruptive technologies, why not becoming an expert prompt engineer with our Finxter Academy Courses (all-you-can-learn) such as this one:


 I published this post in my AI newsletter (130k subs). You can
I published this post in my AI newsletter (130k subs). You can 










 Problem Formulation: How can users reliably tell whether an image was created by a human or generated by AI? Specifically, with Gemini Nano Banana Pro and other recent image generation tools, you never know if a screenshot, scientific paper result, chart, or person is real or AI-generated.
Problem Formulation: How can users reliably tell whether an image was created by a human or generated by AI? Specifically, with Gemini Nano Banana Pro and other recent image generation tools, you never know if a screenshot, scientific paper result, chart, or person is real or AI-generated.  Example 1: Gemini-Generated Image Detected
Example 1: Gemini-Generated Image Detected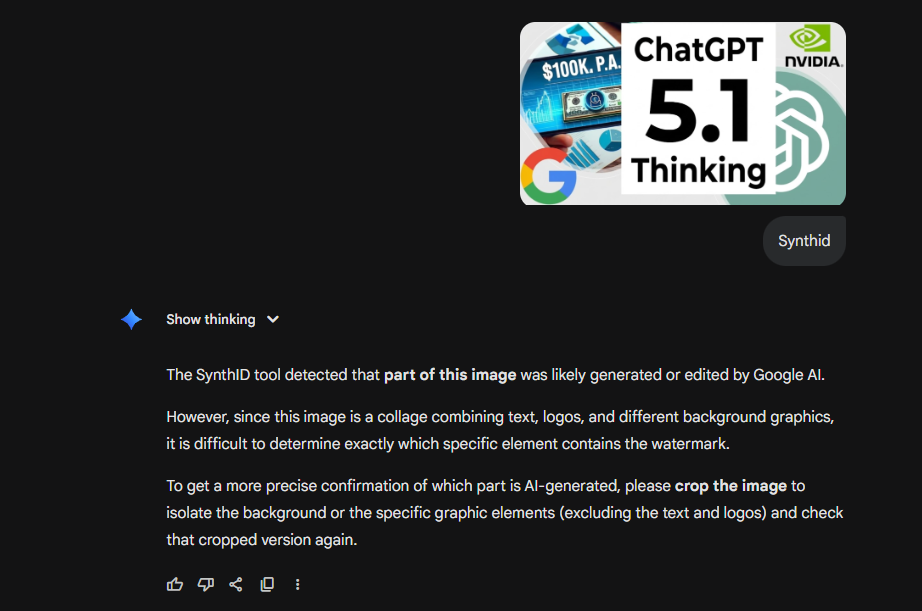
 Example 2: ChatGPT-Generated Image Not Detected
Example 2: ChatGPT-Generated Image Not Detected
 Example 3: Gemini-Generated Image Not Detected
Example 3: Gemini-Generated Image Not Detected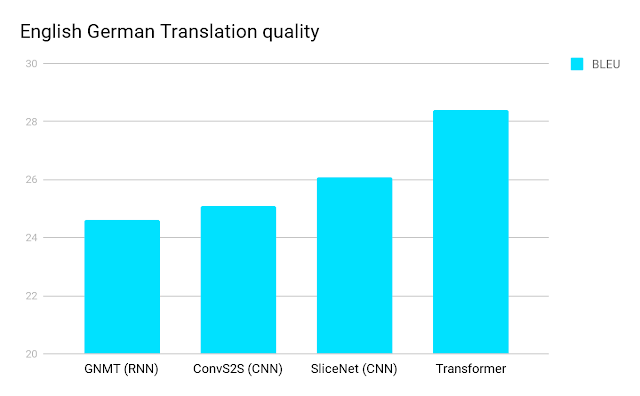
 . In this article, we will explore the best ways to remove Unicode characters from a list using Python.
. In this article, we will explore the best ways to remove Unicode characters from a list using Python. Lists are a built-in Python data structure used to store and manipulate collections of items. They are mutable, ordered, and can contain elements of different types, including Unicode strings.
Lists are a built-in Python data structure used to store and manipulate collections of items. They are mutable, ordered, and can contain elements of different types, including Unicode strings.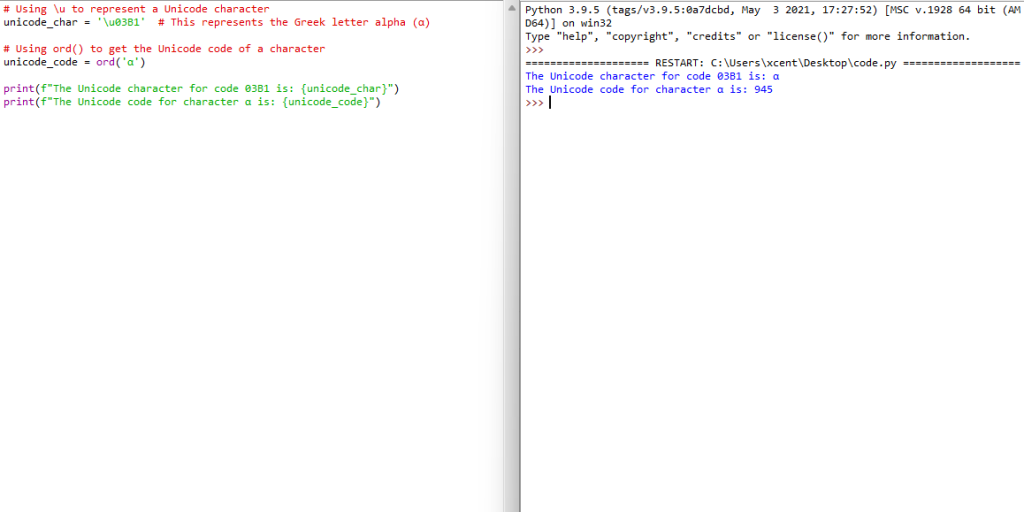

 Recommended:
Recommended: 
 Disruptive Innovation refers to a new technology, process, or business model that disrupts an existing market. Disruptive innovations often start as simpler, cheaper, and lower-quality solutions compared to existing offerings. They often target an underserved or new market segment. They often create a different value network within the market. However, truly disruptive innovation companies improve over time and eventually displace existing market participants.
Disruptive Innovation refers to a new technology, process, or business model that disrupts an existing market. Disruptive innovations often start as simpler, cheaper, and lower-quality solutions compared to existing offerings. They often target an underserved or new market segment. They often create a different value network within the market. However, truly disruptive innovation companies improve over time and eventually displace existing market participants.


 Here’s my personal key take-away (not financial advice):
Here’s my personal key take-away (not financial advice): 

 ):
):