

Motivation and Vision
The core motivation behind data analysis pipelines, and the focus of this article, is the need to establish a clear path from unprocessed data to actionable insights for contributor engagement and impact. The key question is “what are we trying to measure to ensure the continuity of community work?”
As a side note, my preparation for the ADSP (Advanced Data Analysis Semi-Professional) certification in Korea utilized RStudio Desktop, running on a Fedora Linux environment. I got hands-on with R’s core statistical toolkit, leveraging base functions. Among these were summary()1 and lm()2 as the basis for fundamental hypothesis testing and regression analysis3. I became more intrigued by R’s power after testing its data manipulation packages (especially the key package dplyr).
With this background in mind, the article focuses on the design of an analysis pipeline that fulfills three objectives:
- it leverages the power of DuckDB4 and S3 storage,
- it redefines the workflow,
- it ensures scalable data transformation and analysis capabilities
Establishing such a robust foundation is essential for producing reliable and validated metrics for the contributor community, which itself is subject to ongoing definition and validation.
Acknowledgement: I extend my sincere gratitude to Justin Wheeler for connecting me with the Fedora Data Working Group (FDWG), and to Michael Winters and K Naraian for their guidance, discussion, and support throughout the design and validation of this data analysis pipeline.
Scope and Tool Selection: Please note that this analysis pipeline represents a combination of tools and methods chosen from my perspective as a data analyst, particularly one with a background in the CRM (Customer Relationship Management) domain and consumer electronics industry. Therefore, other analysts or data engineers may utilize different combinations of technologies based on their own expertise or project requirements.
Why data analysts must engage with ELT5/ETL6
The role of the analyst is undergoing a fundamental transformation in 2025. We are moving beyond the traditional responsibility of performing statistical analysis and presenting visualization on pre-cleaned data. Today, the modern analyst must evolve into a “Data Ops(Operations)”. This requires a holistic understanding of the data lifecycle and bridging the gap between business context and data engineering. This expansion mandates a familiarity with ELT/ETL processes to examine the quality and structure of the data source.
Moreover, data analysts must be adept at processing diverse data types such as semi-structured data (for example, schema-less JSON strings or variant) and understanding various data access methods such as leveraging the efficiency of in-situ processing over the constraints of in-memory loading of datasets.
RStudio: The Unified IDE for Hybrid R and Python workflows
My ADSP examination requirements motivated my initial deep dive into RStudio. However, it is worth highlighting its utility as a tool for any data professional. The most significant benefit of using RStudio is its seamless ability to leverage the best tools from both the R and Python language ecosystems. This eliminates the need for the analyst to switch environments which leads to dramatically higher operational efficiency. This unified approach streamlines the analysis lifecycle from code execution to final reporting.
Python for data engineering
Use Python’s libraries like Pandas for efficient ETL/ELT operations, data manipulation on large datasets, and integrating with production environments or machine learning workflows (TensorFlow/PyTorch).
R for analysis and visualization
Utilize R’s statistical packages and its superior data visualization capabilities (ggplot2, R Shiny) for data analysis modeling, beautiful reporting, and creating customized, publication-ready graphics.
RStudio Desktop: Installation Instructions7 for Fedora Linux
Install R base packages using the terminal and verify:
$ sudo dnf install R
$ R --version
Now, install RStudio from the Fedora COPR repository. Note that these COPR packages conflict with the binary package provided by Posit. Remove the existing Posit RStudio binary package if you installed it.
$ sudo dnf copr enable iucar/rstudio
$ sudo dnf install rstudio-desktop
Dependencies and dev tools are required so install them:
$ sudo dnf install @development-tools
$ sudo dnf install libxml2-devel openssl-devel curl-devel
Launch the RStudio. When the < prompt appears on the RStudio Console enter the following commands. Note that this prompt should appear in the bottom-left pane of the default layout.
Install the reticulate package and execute the function reticulate::py_install() to manage Python dependencies:
install.packages("reticulate")
reticulate::py_install(packages = c("duckdb", "pandas"))
Set the global options for all code chunks within the R Markdown Canvas:
knitr::opts_chunk$set(echo = TRUE, message = FALSE, warning = FALSE)
ragg is an indirect but critical dependency of core Tidyverse packages (such as ggplot2):
install.packages("ragg")
Install base packages for data manipulation:
install.packages("tidyverse")
DBI, tools for database interface, is an essential R package that provides a standardized, vendor-agnostic interface for connecting to and interacting with various database systems (both local and remote)
install.packages("DBI")
Install tools for Parquet files and S3 data lake access:
install.packages("arrow")
Install R Markdown for combining R code, and install Quarto for combining R/Python/SQL with its execution results, and explanatory text into reproducible data pipelines directly within the environment. The Quarto (.qmd) file runs code chunks in R, Python, and SQL in a single document.
install.packages(c("rmarkdown","quarto"))
Load packages for ELT and EDA:
library(tidyverse)
library(arrow)
Data architecture pipeline
The specific dataset chosen, Datanommer (Fedora Messaging Streams), aligns with the strategic objectives of the Fedora Data Working Group, where I contribute. The data is stored in the Bronze Data Layer where raw data from source systems is ingested and stored, as-is, for scalable data lake storage. The Bronze Layer allows for schema evolution without breaking downstream processes.
To provide the Working Group with transparent access and initial insight into this data, I have prepared a shared Initial Exploratory Data Analysis (EDA) Notebook. This notebook serves as the initial public view of the data quality and patterns, and it informed the subsequent architectural decisions for the scalable pipeline I am about to outline.
Given the complexity of the architecture, I will proceed with an outline of the core components, organized by their role in the ELT pipeline:
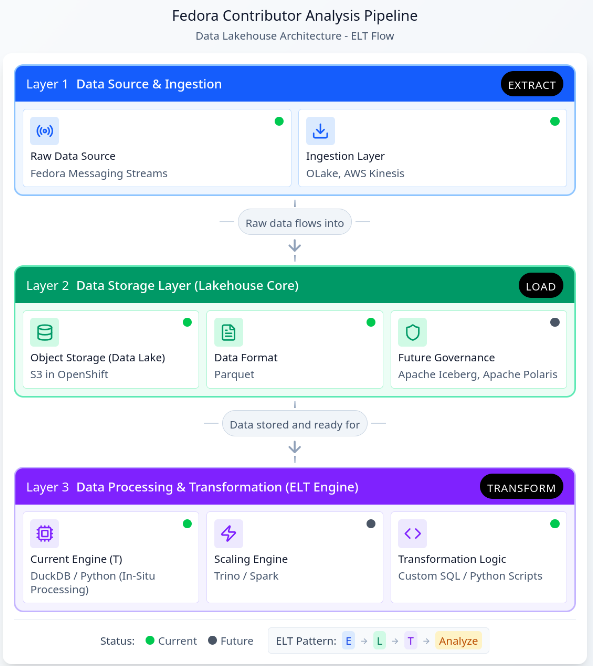
This restructured pipeline, leveraging the new Lakehouse architecture, unlocks several core benefits crucial for scaling contributor analysis and enabling future insights:
Elimination of Memory Constraints via In-Situ Processing
DuckDB acts as a high-performance analytical engine that enables In-Situ Processing. It queries data directly from storage (specifically the Parquet files) without requiring the entire dataset to be loaded into RAM. This not only solves the memory problem but also delivers rapid query execution and significantly lowers operational costs associated with large computational clusters hosted on the OpenShift/Fedora AWS infrastructure.
Future-Proofing
The shift to a Lakehouse model ensures the pipeline is ready for growth and evolving data complexity. Future integration of Apache Iceberg and Apache Polaris will provide schema evolution capabilities. This ensures the pipeline is fully future-proofed against changes in underlying data structures.
Streamlined ELT Workflow and Multi-Lingual Access
I have redefined the processing workflow from a bottlenecked ETL model to a resilient Extract-Load-Transform (ELT) pattern. Parquet files with the variant type store semi-structured data (like JSON/nested structures), loaded raw into S3, simplifies the ingestion stage. When using R, it is recommended to read Parquet files using the Apache Arrow library.
The parsed data is then accessible by multiple analytical platforms (R Shiny, Python, BI tools) without duplication or manual preparation. This multi-lingual access maximizes the utility of the clean data layer, supporting a growing number of analytical users and more complex queries necessary for defining long-term contributor metrics.
Initial EDA Notebook
The preliminary Exploratory Data Analysis (EDA) was conducted within the Jupyter Notebook format. This allowed broad compatibility with the existing execution and review environment of the Fedora Data Working Group.
The Initial EDA Notebook is documented to ensure complete reproducibility. This included all necessary steps for the Python library installation and environment setup. Any standard Python script containing ELT logic can be seamlessly run within RStudio’s Python mode or “knitting8” an R Markdown document or rendering a Quarto file.
Conclusion
The establishment of this analysis pipeline represents a crucial step in transforming unprocessed Fedora data into actionable insights. By addressing the core challenges of scaling and in-memory processing through DuckDB, and enabling transparent analysis via the hybrid RStudio/Jupyter workflow, I have demonstrated viable methods for performing Exploratory Data Analysis (EDA) and Extract, Load, Transform (ELT) processes on vast community datasets. In conclusion, the purpose of this work is to foster deeper engagement across a broader community by analyzing data with a view that relates to the Fedora Project community.
I hope this pipeline will serve as the technical foundation that activates and focuses the community discussion around the specific variables and metrics needed to define and ensure the continuity of community contributions.
AI Assistance
The ideation, structural planning, and terminology refinement of the pipelines were assisted by Gemini and Figma.
Software version
RStudio Desktop 2025.05.1 Build 513 (Fedora COPR repository)
R version 4.5.2 (2025-10-31) / Python 3.14.0
Notes
- summary(): When used on a data object (for example, DataFrame), it provides basic statistics (min, max, mean, median). When used on a fitted linear model object (lm), it delivers key diagnostic information like coefficient estimates and p-values.
 ︎
︎ - lm(): Stands for Linear Model. This is the core function for fitting linear regression models in R, allowing the user to examine and model the linear relationship between variables. ︎
- Regression analysis examines which factors affect the other and which ones are irrelevant for statistical and business context. ︎
- DuckDB is a column-oriented database architecture.
– Direct Querying: It directly queries data from file formats such as Parquet, CSV, and JSON.
– Local compute engine: It is widely used as a high-performance local compute engine for analytical workloads. It runs in-process, meaning it operates within your application (like a Python script or R session) without needing a separate server or cluster management.
– Cloud Integration: It supports querying data stored in cloud storage services like AWS S3, GCS (Google Cloud Storage), and Azure Blob Storage.
︎ - ELT (Extract, Load, Transform): In a modern data environment like a Lakehouse, ELT is preferred: data is first extracted from the source and loaded raw into the cloud data lake (S3), and then transformed in place by the processing engine like DuckDB. ︎
- ETL (Extract, Transform, Load): transformations occur before loading the data into the final destination. ︎
- Key Advantages of RStudio over Jupyter Notebook for Production Workflows;
Even with its slightly more complex initial setup compared to Jupyter Notebooks, the advantages become significant when moving from exploration (Jupyter’s strength) to reproducible, production-ready workflows (RStudio’s strength).
– Integrated Console, Source, Environment, and Files: RStudio offers a cohesive, four-pane layout that allows for seamless navigation between writing code, running commands, inspecting variables, and managing files/plots. Jupyter requires constant shifting between code cells and external tabs.
– Superior Debugging Tools: RStudio includes a powerful, visual debugger that allows you to set breakpoints, step through code line-by-line, and inspect variable states directly in the environment pane. Jupyter’s debugging is typically cell-based and less intuitive.
– Native Project Management: RStudio Projects (.Rproj files) automatically manage the working directory and history. This makes it easy to switch between different analytical tasks without conflicts.
– Integrated Environment Management (renv): RStudio integrates seamlessly with tools like renv (R Environment) to create isolated, reproducible R environments. This addresses dependency hell by ensuring the exact package versions used in development are used in production, which is crucial for data pipeline version control.
– Quarto/R Markdown Integration: RStudio provides dedicated tools and buttons for easily compiling and rendering complex analytical documents (like your Quarto file) into HTML, PDF, or presentation slides.
– Shiny Integration: RStudio is the native environment for developing Shiny web applications—interactive dashboards and tools that turn analysis into deployable products. Jupyter requires separate frameworks (like Dash or Streamlit) for similar deployment.
– Focus on Scripting: RStudio’s source editor is optimized for writing clean, structured R/Python scripts, which are preferred for building robust, scheduled pipeline components (like those managed by Airflow).
– Code Chunk Execution (Quarto): Even when using Quarto, RStudio allows for superior navigation and execution of code chunks compared to the often sequential and state-dependent nature of Jupyter Notebook cells.︎ - knitr executes code in R Markdown (.Rmd) file by chunks or as a whole (typically by clicking the “Knit” button in RStudio or using rmarkdown::render() in R) ︎