

The best way to convert a CSV file to a Python dictionary is to create a CSV file object f using open("my_file.csv") and pass it in the csv.DictReader(f) method. The return value is an iterable of dictionaries, one per row in the CSV file, that maps the column header from the first row to the specific row value.
Let’s have a look at a simple example to demonstrate this solution next!
Basic Solution: CSV to Dict Example
Here’s the content of an example CSV file "my_file.csv" used in our code snippet below:
Name,Job,Age,Income
Alice,Programmer,23,110000
Bob,Executive,34,90000
Carl,Sales,45,50000If you visualize this CSV in table form, it looks like this:
| Name | Job | Age | Income |
|---|---|---|---|
| Alice | Programmer | 23 | 110000 |
| Bob | Executive | 34 | 90000 |
| Carl | Sales | 45 | 50000 |
Here’s the code to convert that CSV file to multiple dictionaries, one dictionary per row by using the csv.DictReader(file) function:
import csv csv_filename = 'my_file.csv' with open(csv_filename) as f: reader = csv.DictReader(f) for row in reader: print(row)
A dictionary is a data structure that maps keys to values.
The output of the previous code snippet shows how the first row of the CSV is used as a header to determine the keys of the dictionary that are mapped to the values defined in the individual rows of the CSV file:
{'Name': 'Alice', 'Job': 'Programmer', 'Age': '23', 'Income': '110000'}
{'Name': 'Bob', 'Job': 'Executive', 'Age': '34', 'Income': '90000'}
{'Name': 'Carl', 'Job': 'Sales', 'Age': '45', 'Income': '50000'}The csv.DictReader(f) method takes a file object f as an input argument. So, you first need to open the file using the built-in Python open() function.
 Note: A common error is to pass the filename as a string—but this doesn’t work! The
Note: A common error is to pass the filename as a string—but this doesn’t work! The csv.DictReader(f) method expects a file object as a required argument.
One-Liner Solution: CSV to Dict
I love Python one-liners. That’s why I have written a book on those after all. 
So, can we convert a CSV to a list of dictionaries in a single line of Python?
Of course, we can!
Here’s the one-liner that accomplishes the same as the code discussed before:
import csv; print(*csv.DictReader(open('my_file.csv')), sep='\n')
 Explanation: We import the
Explanation: We import the csv module, use the semicolon ; to package two statements in one line, unpack * all rows from the csv.DictReader() output in a print statement, and use the newline character '\n' as a separator between two dictionary rows.
The output is the same as before:
{'Name': 'Alice', 'Job': 'Programmer', 'Age': '23', 'Income': '110000'}
{'Name': 'Bob', 'Job': 'Executive', 'Age': '34', 'Income': '90000'}
{'Name': 'Carl', 'Job': 'Sales', 'Age': '45', 'Income': '50000'}If you just want to store the CSV contents in a list of dictionaries rather than printing them, you can use the following technique:
import csv; lst=[*csv.DictReader(open('my_file.csv'))]; print(lst)
The output is a list of dictionaries, one per (non-header) row of the original CSV:
[{'Name': 'Alice', 'Job': 'Programmer', 'Age': '23', 'Income': '110000'}, {'Name': 'Bob', 'Job': 'Executive', 'Age': '34', 'Income': '90000'}, {'Name': 'Carl', 'Job': 'Sales', 'Age': '45', 'Income': '50000'}]
If you’re interested in learning one-liners as well, feel free to check out my book:
Python One-Liners Book: Master the Single Line First!
Python programmers will improve their computer science skills with these useful one-liners.

Python One-Liners will teach you how to read and write “one-liners”: concise statements of useful functionality packed into a single line of code. You’ll learn how to systematically unpack and understand any line of Python code, and write eloquent, powerfully compressed Python like an expert.
The book’s five chapters cover (1) tips and tricks, (2) regular expressions, (3) machine learning, (4) core data science topics, and (5) useful algorithms.
Detailed explanations of one-liners introduce key computer science concepts and boost your coding and analytical skills. You’ll learn about advanced Python features such as list comprehension, slicing, lambda functions, regular expressions, map and reduce functions, and slice assignments.
You’ll also learn how to:
- Leverage data structures to solve real-world problems, like using Boolean indexing to find cities with above-average pollution
- Use NumPy basics such as array, shape, axis, type, broadcasting, advanced indexing, slicing, sorting, searching, aggregating, and statistics
- Calculate basic statistics of multidimensional data arrays and the K-Means algorithms for unsupervised learning
- Create more advanced regular expressions using grouping and named groups, negative lookaheads, escaped characters, whitespaces, character sets (and negative characters sets), and greedy/nongreedy operators
- Understand a wide range of computer science topics, including anagrams, palindromes, supersets, permutations, factorials, prime numbers, Fibonacci numbers, obfuscation, searching, and algorithmic sorting
By the end of the book, you’ll know how to write Python at its most refined, and create concise, beautiful pieces of “Python art” in merely a single line.
 online sources such as the following:
online sources such as the following: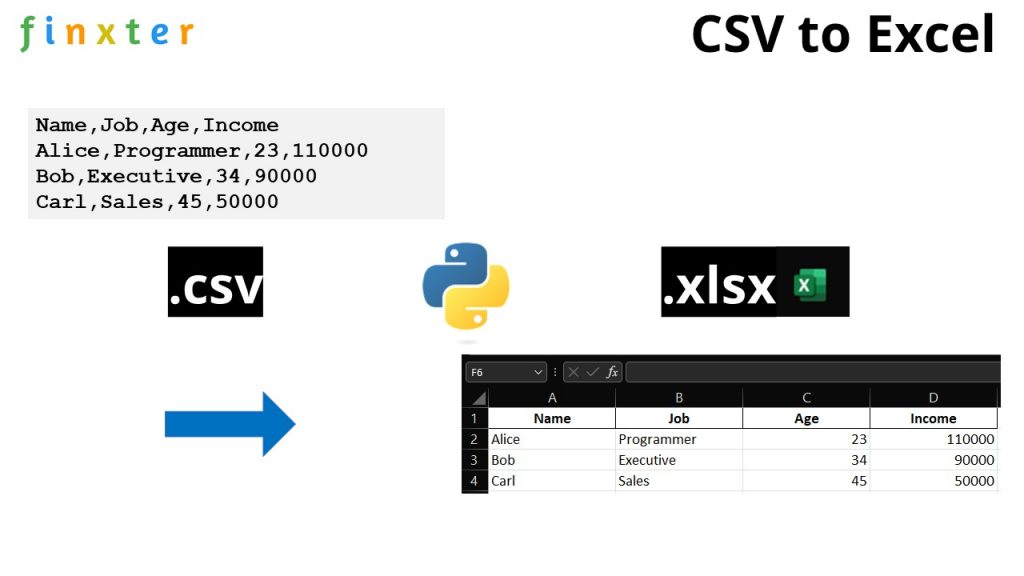

 Tutorial:
Tutorial:  If your answer is YES!, consider becoming a
If your answer is YES!, consider becoming a 


















 Question: How would we write code to erase the contents of a file?
Question: How would we write code to erase the contents of a file? Tip: A file object is returned whenever a file is opened in Python. This object allows access to process/manipulate the open file.
Tip: A file object is returned whenever a file is opened in Python. This object allows access to process/manipulate the open file.




 Are you interested in the intersection of finance and coding?
Are you interested in the intersection of finance and coding?





