Also, you’ll learn how to solve a variant of this challenge.
Bonus challenge: Find only the length of the longest list in the list of lists.
Here are some examples:
[[1], [2, 3], [4, 5, 6]]3
[[1, [2, 3], 4], [5, 6], [7]]3
[[[1], [2], [3]], [4, 5, [6]], [7, 8, 9, 10]]4
So without further ado, let’s get started!
Method 1: max(lst, key=len)
Use Python’s built-in max() function with a key argument to find the longest list in a list of lists. Call max(lst, key=len) to return the longest list in lst using the built-inlen() function to associate the weight of each list, so that the longest inner list will be the maximum.
A beautiful one-liner solution, isn’t it? Let’s have a look at a slight variant to check the length of the longest list instead.
Method 2: len(max(lst, key=len))
To get the length of the longest list in a nested list, use the len(max(lst, key=len)) function. First, you determine the longest inner list using the max() function with the key argument set to the len() function. Second, you pass this longest list into the len() function itself to determine the maximum.
A Pythonic way to check the length of the longest list is to combine a generator expression or list comprehension with the max() function without key. For instance, max(len(x) for x in lst) first turns all inner list into length integer numbers and passes this iterable into the max() function to get the result.
Here’s this approach on the same examples as before:
A not so Pythonic but still fine approach is to iterate over all lists in a for loop, check their length using the len() function, and compare it against the currently longest list stored in a separate variable. After the termination of the loop, the variable contains the longest list.
Note: If you need the length of the longest list, you could simply replace the last line of the function with return len(longest) , and you’re done!
Summary
You have learned about four ways to find the longest list and its length from a Python list of lists (nested list):
Method 1: max(lst, key=len)
Method 2: len(max(lst, key=len))
Method 3: max(len(x) for x in lst)
Method 4: Naive For Loop
I hope you found the tutorial helpful, if you did, feel free to consider joining our community of likeminded coders—we do have lots of free training material!
In the previous articles, we looked at some of the representative examples of smart contracts representing possible real-world scenarios.
Our main focus was on capturing the essence of each case, without particular attention given to the general structure, i.e. layout of the respective source files.
However, in this mini-series starting with this article, we will focus particularly on the source file layout.
The articles will continue with our tradition of going hand in hand with the official Solidity documentation, with the particular topic of our current interest available here.
Info: As we’ve reached such a nice, round number of articles on Solidity, I have a small foreword for my faithful audience.
For those of us who missed or skipped previous articles, the intent behind the content is to supplement and clarify the original documentation and even present it in a style that I find to be more appropriate to us as the audience.
Given that we come from various backgrounds, some less and some more technical, it is my permanent goal to soften the material and make it as close as possible to each reader. Sometimes, completely unannounced and unprovoked, I’ll even try and sprinkle some humor onto the content.
Will I succeed in making it funny and engaging? That’s whole another story
SPDX License Identifier
Smart contracts are somewhat a mystery to unfamiliar folks, and a mystery usually implies a certain amount of distrust. Even so, the more sensitive the subject is, the greater the amount of distrust. The best way to turn distrust into trust is to make the content in question open and available.
When we’re talking about smart contracts, the openness of a smart contract means the availability of its source code. However, making the source code available frequently triggers legal problems regarding copyright.
To alleviate these problems, the Solidity compiler instigates the use of SPDX license identifiers.
Info: SPDX stands for the Software Package Data Exchange, which is “An open standard for communicating software bill of material information, including components, licenses, copyrights, and security references. SPDX reduces redundant work by providing a common format for companies and communities to share important data, thereby streamlining and improving compliance.“
Yes, I agree, it’s a lengthy sentence, but the main takeaway ideas are a communication standard, an instrument of compliance, and a data exchange format:
SPDX is a standard used for communicating the information about the software contents;
SPDX reduces redundant work and improves compliance;
SPDX provides a common format for data sharing between companies and communities;
An SPDX license identifier should be included at the beginning of the source file, e.g.
// SPDX-License-Identifier: GPL-3.0-or-later
Although SPDX license identifiers are machine-readable, the compiler does not check if the license part of the comment is in the list of licenses allowed by SPDX.
Instead, the compiler will just include the string in the bytecode metadata.
We will touch on the subject of contract metadata in future articles, but until then, let’s just remember that there is a thing called metadata.
Info: Metadata can be loosely defined as “data/information about data”, meaning it provides more information or description of certain data.
We don’t have to specify a license or if the case is that the source code is closed-source (opposite of open-source), the recommendation is that we use a special value UNLICENSED.
The UNLICENSED value implies that usage is not allowed, i.e. there is not a corresponding item in SPDX license list; it differs from the value UNLICENSE which grants all rights to everyone.
If we as developers supply the UNLICENSE comment, we are still tied by the obligation related to licensing, i.e. we have to mention a specific license header or the original copyright holder in the source files.
Although the compiler recognizes the comment placed at any location in the source file, the recommendation, and good practice is to put it at the top of the file.
Pragmas
We’ve mentioned the pragma keyword somewhere in the first few articles, but now we’ll use the opportunity to say a few more words about it.
Pragma keyword is the element of the Solidity programming language that enables specific Solidity compiler (remember solc) features or validations, i.e. checks.
As the pragma keyword scope is its source file, we’d have to add the pragma to all our files to enable it in our whole project.
Note: A pragma from an imported file does not apply to the importer file, i.e. the file that imports the imported file.
Version Pragma
We always use a version pragma for limiting the source file(s) compilation to a specific range of compiler versions.
The intention behind this step is the prevention of incompatible changes introduced with future versions of compilers.
According to the Solidity authors, occurrences of incompatible changes are reduced to an absolute minimum, meaning that in all other cases i.e. cases of compatible changes, the changes in Solidity language semantics visibly coincide with the changes in language syntax.
To stay on the safe side, the recommendation is to study the changelog at least for releases that carry breaking changes, marked x.0.0 (major releases) or 0.x.0 (minor releases).
Info: semantic is relating to meaning in language or logic.
As in every our example so far, we’re using the version pragma as:
Note: pragma solidity ^0.x.y; allows changes that do not modify the left-most non-zero digit in the [major, minor, patch] tuple (docs).
The following line instructs the compilation process to use a compiler with the lowest version of 0.5.2 and with the highest version not exceeding 0.6.0 (this condition is incorporated by a ^ symbol):
pragma solidity ^0.5.2;
By recalling the article about semantic versioning, we’ll remember that no breaking changes are introduced until a minor version of 0.6.0 (in this specific case), therefore we can be sure that our code will compile just as we expect it to.
Also, by using the line above, we didn’t lock on the specific version, so the last part of the version label, i.e. the patch number can increase, leaving enough space for the compiler bug fixes.
Besides this most common way of expressing the allowed versions of the compiler, even more, complex rules are available by using the syntax available here.
Note: version pragma just instructs the compiler to self-check if it is compliant with the version required by the source file. In case of a mismatch, the compiler will throw an (in)appropriate error. I mean, who ever saw an appropriate error, anyways?
Conclusion
With this introductory article to the topic of the layout of a Solidity source file, we covered a few very light concepts, including SPDX license identifier, reintroduced the pragma keyword, and retouched the version pragma.
In the next article, we will continue with the next two pragmas and other, very interesting topics.
In the SPDX License Identifier section, we were asking around inconspicuously about the SPDX. We wanted to find out what it is, how and when it is used, and how it can make our developing life easier.
In the Pragmas section, we proudly reminded ourselves of the knowledge from long ago, why do we have to slam a pragma at the beginning of each source file?
If at least they looked nice… Starting our coding masterpieces with a dangling comment seemed like a skewed joke (like most of mine do) – until we learned why
Problem Formulation: Given a Python set. How to convert it to a tuple? And how to convert the tuple back to a set?
There are three main ways:
Method 1: To convert a Python set to a tuple, use the tuple(my_set) function.
Method 2: To convert a Python tuple to a set, use the set(my_tuple) function.
Method 3: To convert a Python tuple of mutable elements to a set, use the expression set(tuple(x) for x in my_tuple) to avoid a TypeError.
I’ll also give you a bonus method 4 that shows you what to do to retain the ordering information when converting a tuple to a set—so keep reading!
Method 1: Convert Set to Tuple with tuple()
To convert a set to a tuple, pass the set into the tuple() function. This is a built-in Python function, so you don’t need to import or install any library to use it. The return value is a new tuple from the values in the set.
Here’s an example where you convert the set {1, 2, 3} to a tuple (1, 2, 3):
By the way, here’s an explainer video on this function:
Method 2: Convert Tuple to Set with set()
To convert a tuple to a set, pass the tuple into the set() function. This is a built-in Python function, so you don’t need to import or install any library. The return value is a new set from the values in the tuple.
Here’s an example where you convert the tuple (1, 2, 3) to a set {1, 2, 3}:
Problem: However, the conversion process from a tuple to set doesn’t always work because if you try to convert a tuple of mutable values, Python will raise the TypeError: unhashable type!
Read on to learn more about this problem—and how to resolve it easily:
Method 3: Convert Tuple to Set with Set Comprehension
A Python set is an unordered collection of unique immutable elements. Each element must define explicitly or implicitly the __hash__() dunder method, i.e., must be hashable.
If you attempt to convert a tuple of mutable elements (e.g., lists) to a set, Python will raise an error such as the TypeError: unhashable type: 'list':
In this case, you can use set comprehension to convert each inner tuple element to an immutable type. For example, the expression set(tuple(x) for x in my_tuple) converts each inner list to a tuple. The result is a set of immutable tuples.
Here’s the solution to this problem in a minimal code example:
my_tuple = ([1, 2], [3, 4], [5, 6])
my_set = set(tuple(x) for x in my_tuple)
print(my_set)
# {(1, 2), (3, 4), (5, 6)}
The final “bonus” section introduces another elegant way to retain the ordering information in a set:
Bonus Method 4: Enumerate Elements
Sometimes, you want to associate each set or tuple element with a specific numerical “index” value, i.e., a unique integer identifier. The enumerate() method to the rescue!
Use tuple(enumerate(my_set)) to convert a set to an enumerated tuple.
Use set(enumerate(my_tuple)) to convert a tuple to an enumerated set.
The result is the respective container data structure with (identifier, value) tuples:
Especially in the case where you convert a tuple to a set, this makes a lot of sense because you can retain the information on the ordering of elements that would be otherwise lost after converting to a set.
Thanks for reading the whole article, my friend! You can join us here (we have cheat sheets too):
To find the longest string in a given NumPy array, say arr, you can use the max(arr, key=len) function that determines the maximum by comparing the length of the array elements using the len() function as a key for comparison.
import numpy as np arr = np.array(['Alice', 'Bob', 'Carl'])
print(max(arr, key=len))
# Alice
You can find more about the powerful max() function in our detailed blog tutorial:
To find the length of the longest string in a NumPy array arr, use the max(arr, key=len) function to obtain the string with the maximum length and then pass this max string into the len() function to obtain the number of characters of the max string.
len(max(arr, key=len))
Here’s a more detailed code example of a simple 1D NumPy Array:
import numpy as np arr = np.array(['Alice', 'Bob', 'Carl']) # Print Longest String:
print(max(arr, key=len))
# Alice # Print Length of Longest String
print(len(max(arr, key=len)))
# 5
Get Longest String from NumPy Axis (2D, Column or Row)
To get the longest string from a certain NumPy array axis (e.g., row or column), first use simple NumPy slicing and indexing to get that axis (e.g., arr[0, :] to get the first row) and pass it into the max() function with the key argument set to the length function like so: max(arr[0, :], key=len).
Here’s an example to get the longest string of the first row of a 2D array:
import numpy as np arr = np.array([['Alice', 'Bob', 'Carl'], ['Ann', 'Zoe', 'Leonard']]) print(max(arr[0, :], key=len))
# Alice
Here’s an example to get the longest string of the third column of a 2D array:
print(max(arr[:, 2], key=len))
# Leonard
You get the idea.
If you want to get the longest string from the whole NumPy array, not only from a column or row or axis, first flatten it and then pass the flattened array into the max() function using the key=len argument.
Summary: You can combine images represented in the form of Numpy arrays using the concatenate function of the Numpy library as np.concatenate((numpydata_1, numpydata_2), axis=1). This combines the images horizontally. Use syntax: np.concatenate((numpydata_1, numpydata_2), axis=0) to combine the images vertically.
Problem Formulation
Consider you have two images represented as Numpy arrays of pixels. How will you combine the two images represented in the form of Numpy pixel arrays?
Combining two images that are in the form of Numpy arrays will create a new Numpy array having pixels that will represent a new combined image formed by either concatenating the two images horizontally or vertically. Let’s understand this with the help of an example:
Given: Let’s say we have two different images as given below (Both images have similar dimensions) –
img_1.JPGimg_2.JPG
When you convert them to Numpy arrays this is how you can represent the two images:
So, are you up for the challenge? Well! If it looks daunting – don’t worry. This tutorial will guide you through the techniques to solve the programming challenge. So, without further delay let us dive into the solution.
Prerequisite: To understand how the solutions to follow work it is essential to understand – “How to concatenate two Numpy arrays in Python.”
NumPy’s concatenate() method joins a sequence of arrays along an existing axis. The first couple of comma-separated array arguments are joined. If you use the axis argument, you can specify along which axis the arrays should be joined. For example, np.concatenate(a, b, axis=0) joins arrays along the first axis and np.concatenate(a, b, axis=None) joins the flattened arrays.
To learn more about concatenating arrays in Python, here’s a wonderful tutorial that will guide you through numerous methods of doing so: How to Concatenate Two NumPy Arrays?
Combine Images “Horizontally” with Numpy
Approach: The concatenate() method of the Numpy library allows you combine matrices of different images along different axes. To combine the two image arrays horizontally, you must specify the axis=1.
Code: Please go through the comments mentioned in the script in order to understand how each line of code works.
from PIL import Image
import numpy as np
# Reading the given images img_1 = Image.open('img_1.JPG')
img_2 = Image.open('img_2.JPG')
# Converting the two images into Numpy Arrays
numpydata_1 = np.asarray(img_1)
numpydata_2 = np.asarray(img_2)
# Combining the two images horizontally
horizontal = np.concatenate((numpydata_1, numpydata_2), axis=1)
# Display the horizontally combined image as a Numpy Array
print(horizontal)
# converting the combined image in the Numpy Array form to an image format
data = Image.fromarray(horizontal)
# Saving the combined image
data.save('combined_pic.png')
Here’s how the horizontally combined image looks like when saved to a file:
Wonderful! Isn’t it?
Combine Images “Vertically” with Numpy
In the previous solution, we combined the images horizontally. In this soution you will learn how to combine two images represented in the form of Numpy arrays vertically.
Approach: The idea is quite similar to the previous solution with the only difference in the axis parameter of the concatenate() method. To combine the two image arrays vertically, you must specify the axis=0.
Code:
from PIL import Image
import numpy as np
# Reading the given images
img_1 = Image.open('img_1.JPG')
img_2 = Image.open('img_2.JPG')
# Converting the two images into Numpy Arrays
numpydata_1 = np.asarray(img_1)
numpydata_2 = np.asarray(img_2)
# Combining the two images horizontally
vertical = np.concatenate((numpydata_1, numpydata_2), axis=0)
# Display the vertically combined image as a Numpy Array
print(vertical)
# converting the combined image in the Numpy Array form to an image format
data = Image.fromarray(vertical)
# Saving the combined image
data.save('combined_pic.png')
Phew! That was some coding challenge! I hope you can now successfully combine images given as Numpy arrays in both dimensions – horizontally as well as vertically. With that we come to the end of this tutorial. Please subscribe and stay tuned for more interesting tutorials and solutions in the future.
This article continues on the Solidity Smart Contract Examples series, which implements a simple, but the useful process of safe remote purchase.
Here, we’re walking through an example of a blind auction (docs).
We’ll first lay out the entire smart contract example without the comments for readability and development purposes.
Then we’ll dissect it part by part, analyze it and explain it.
Following this path, we’ll get a hands-on experience with smart contracts, as well as good practices in coding, understanding, and debugging smart contracts.
Smart Contract – Safe Remote Purchase
// SPDX-License-Identifier: GPL-3.0
pragma solidity ^0.8.4;
contract Purchase { uint public value; address payable public seller; address payable public buyer; enum State { Created, Locked, Release, Inactive } State public state; modifier condition(bool condition_) { require(condition_); _; } error OnlyBuyer(); error OnlySeller(); error InvalidState(); error ValueNotEven(); modifier onlyBuyer() { if (msg.sender != buyer) revert OnlyBuyer(); _; } modifier onlySeller() { if (msg.sender != seller) revert OnlySeller(); _; } modifier inState(State state_) { if (state != state_) revert InvalidState(); _; } event Aborted(); event PurchaseConfirmed(); event ItemReceived(); event SellerRefunded(); constructor() payable { seller = payable(msg.sender); value = msg.value / 2; if ((2 * value) != msg.value) revert ValueNotEven(); } function abort() external onlySeller inState(State.Created) { emit Aborted(); state = State.Inactive; seller.transfer(address(this).balance); } function confirmPurchase() external inState(State.Created) condition(msg.value == (2 * value)) payable { emit PurchaseConfirmed(); buyer = payable(msg.sender); state = State.Locked; } function confirmReceived() external onlyBuyer inState(State.Locked) { emit ItemReceived(); state = State.Release; buyer.transfer(value); } function refundSeller() external onlySeller inState(State.Release) { emit SellerRefunded(); state = State.Inactive; seller.transfer(3 * value); }
}
The state variables for recording the value, seller, and buyer addresses.
uint public value; address payable public seller; address payable public buyer;
For the first time, we’re introducing the enum data structure that symbolically defines the four possible states of our contract. The states are internally indexed from 0 to enum_length - 1.
enum State { Created, Locked, Release, Inactive }
The variable state keeps track of the current state. Our contract starts by default in the created state and can transition to the Locked, Release, and Inactive state.
State public state;
The condition modifier guards a function against executing without previously satisfying the condition, i.e. an expression given alongside the function definition.
The constructor is declared as payable, meaning that the contract deployment (synonyms creation, instantiation) requires sending a value (msg.value) with the contract-creating transaction.
constructor() payable {
The seller state variable is set to msg.sender address, cast (converted) to payable.
seller = payable(msg.sender);
The value state variable is set to half the msg.value, because both the seller and the buyer have to put twice the value of the item being sold/bought into the contract as an escrow agreement.
Info: “Escrow is a legal arrangement in which a third party temporarily holds money or property until a particular condition has been met (such as the fulfillment of a purchase agreement).” (source)
In our case, our escrow is our smart contract.
value = msg.value / 2;
If the value is not equally divided, i.e. the msg.value is not an even number, the function will terminate. Since the seller will always
if ((2 * value) != msg.value) revert ValueNotEven(); }
Aborting the remote safe purchase is allowed only in the Created state and only by the seller.
The external keyword makes the function callable only by other accounts / smart contracts. From the business perspective, only the seller can call the abort() function and only before the buyer decides to purchase, i.e. before the contract enters the Locked state.
function abort() external onlySeller inState(State.Created) {
Emits the Aborted event, the contract state transitions to inactive, and the balance is transferred to the seller.
emit Aborted(); state = State.Inactive;
Note: “Prior to version 0.5.0, Solidity allowed address members to be accessed by a contract instance, for example, this.balance. This is now forbidden and an explicit conversion to address must be done: address(this).balance.” (docs).
In other words, this keyword lets us access the contract’s inherited members.
Every contract inherits its members from the address type and can access these members via address(this).<a member> (docs).
seller.transfer(address(this).balance); }
The confirmPurchase() function is available for execution only in the Created state.
It enforces the rule that a msg.value must be twice the value of the purchase.
The confirmPurchase() function is also declared as payable, meaning the caller, i.e. the buyer has to send the currency (msg.value) with the function call.
The eventPurchaseConfirmed() is emitted to mark the purchase confirmation.
emit PurchaseConfirmed();
The msg.sender value is cast to payable and assigned to the buyer variable.
Info: Addresses are non-payable by design to prevent accidental payments; that’s why we have to cast an address to a payable before being able to transfer a payment.
buyer = payable(msg.sender);
The state is set to Locked as seller and buyer entered the contract, i.e., our digital version of an escrow agreement.
state = State.Locked; }
The confirmReceived() function is available for execution only in the Locked state, and only to the buyer.
Since the buyer deposited twice the value amount and withdrew only a single value amount, the second value amount remains on the contract balance with the seller’s deposit.
function confirmReceived() external onlyBuyer inState(State.Locked) {
Emits the ItemReceived() event.
emit ItemReceived();
Changes the state to Release.
state = State.Release;
Transfers the deposit to the buyer.
buyer.transfer(value); }
The refundSeller() function is available for execution only in the Release state, and only to the seller.
Since the seller deposited twice the value amount and earned a single value amount from the purchase, the contract transfers three value amounts from the contract balance to the seller.
function refundSeller() external onlySeller inState(State.Release) {
Emits the SellerRefunded() event.
emit SellerRefunded();
Changes the state to Inactive.
state = State.Inactive;
Transfers the deposit of two value amounts and the one earned value amount to the seller.
seller.transfer(3 * value); }
}
Our smart contract example of a safe remote purchase is a nice and simple example that demonstrates how a purchase may be conducted on the Ethereum blockchain network.
The safe remote purchase example shows two parties, a seller and a buyer, who both enter a trading relationship with their deposits to the contract balance.
Each deposit amounts to twice the value of the purchase, meaning that the contract balance will hold four times the purchase value at its highest point, i.e. in the Locked state.
The height of deposits is intended to stimulate the resolution of any possible disputes between the parties, because otherwise, their deposits will stay locked and unavailable in the contract balance.
When the buyer confirms that he received the goods he purchased, the contract will transition to the Release state, and the purchase value will be released to the buyer.
The seller can now withdraw his earned purchase value with the deposit, the contract balance drops to 0 Wei, the contract transitions to the Inactive state, and the safe remote purchase concludes with execution.
The Contract Arguments
This section contains additional information for running the contract. We should expect that our example accounts may change with each refresh/reload of Remix.
Our contract creation argument is the deposit (twice the purchase value). We’ll assume the purchase value to be 5 Wei, making the contract creation argument very simple:
10
Contract Test Scenario
Account 0x5B38Da6a701c568545dCfcB03FcB875f56beddC4 deploys the contract with a deposit of 10 Wei, effectively becoming a seller.
Account 0xAb8483F64d9C6d1EcF9b849Ae677dD3315835cb2 confirms the purchase by calling the confirmPurchase() function and enters the trade with a deposit of 10 Wei, effectively becoming a buyer.
The buyer confirms receiving the order by calling the confirmReceived() function.
The seller concludes the trade by calling the refundSeller() function.
Conclusion
We continued our smart contract example series with this article that implements a safe remote purchase.
First, we laid out clean source code (without any comments) for readability purposes.
Second, we dissected the code, analyzed it, and explained each possibly non-trivial segment.
Challenge: Given a string. How to find all palindromes in the string?
For comprehensibility, allow me to quickly add a definition of the term palindrome:
Definition: A palindrome is a sequence of characters that reads the same backward as forward such as 'madam', 'anna', or '101'.
This article wants to give you a quick and easy solution in Python. First, we’ll solve the easier but important problem of checking if a substring is a palindrome in the first place:
How to Check If String is Palindrome
You can easily check if a string is a palindrome by using the slicing expression word == word[::-1] that evaluates to True if the word is the same forward and backward, i.e., it is a palindrome.
Next, we’ll explore how to find all substrings in a Python string that are also palindromes. You can find our palindrome checker in the code solution (highlighted):
Find All Substrings That Are Palindrome
The brute-force approach to finding all palindromes in a string is to iterate over all substrings in a nested for loop. Then check each substring if it is a palindrome using word == word[::-1]. Keep track of the found palindromes using the list.append() method. Return the final list after traversing all substrings.
Here’s the full solution:
def find_palindromes(s): palindromes = [] n = len(s) for i in range(n): for j in range(i+1,n+1): word = s[i:j] if word == word[::-1]: palindromes.append(word) return palindromes print(find_palindromes('locoannamadam'))
# ['l', 'o', 'oco', 'c', 'o', 'a', 'anna',
# 'n', 'nn', 'n', 'a', 'ama', 'm', 'madam',
# 'a', 'ada', 'd', 'a', 'm'] print(find_palindromes('anna'))
# ['a', 'anna', 'n', 'nn', 'n', 'a'] print(find_palindromes('abc'))
# ['a', 'b', 'c']
Runtime Complexity
This has cubic runtime complexity, i.e., for a string with length n, we need to check O(n*n) different words. Each word may have up to n characters, thus the palindrome check itself is O(n). Together, this yields runtime complexity of O(n*n*n) = O(n³).
Quadratic Runtime Solutions
Is this the best we can do? No! There’s also an O(n²) time solution!
Here’s a quadratic-runtime solution to find all palindromes in a given string that ignores the trivial one-character palindromes (significantly modified from source):
def find_palindromes(s, j, k): ''' Finds palindromes in substring between indices j and k''' palindromes = [] while j >= 0 and k < len(s): if s[j] != s[k]: break palindromes.append(s[j: k + 1]) j -= 1 k += 1 return palindromes def find_all(s): '''Finds all palindromes (non-trivial) in string s''' palindromes = [] for i in range(0, len(s)): palindromes.extend(find_palindromes(s, i-1, i+1)) palindromes.extend(find_palindromes(s, i, i+1)) return palindromes print(find_all('locoannamadam'))
# ['oco', 'nn', 'anna', 'ama', 'ada', 'madam'] print(find_all('anna'))
# ['nn', 'anna'] print(find_all('abc'))
# []
Feel free to join our community of ambitious learners like you (we have cheat sheets too):
This article will show you how to get a random entry from a Dictionary in Python.
To make it more interesting, we have the following running scenario:
The Plot: Mr. Sinclair, an 8th great Science Teacher, is giving his students a quiz on the first 25 Periodic Table elements. He has asked you to write a Python script so that when run, it generates a random key, value, or key:value pair from the Dictionary shown below to ask his students.
The above code converts the Dictionary of Periodic Table Elements to a List of Tuples and saves it to el_list. If output to the terminal, the contents of el_list contains the following.
Before moving forward, please ensure the NumPy library is installed. Click here if you require instructions.
import numpy as np random_el = np.random.choice(list(els), 1)
print(random_el)
This code imports the NumPy library installed above.
Then, np.random.choice() is called and passed two (2) arguments: els converted to a List of Tuples and the number of random keys to return.
The results save to random_el and is output to the terminal.
['Chromium' 'Silicon' 'Oxygen']
Note: np.random.choice() has an additional parameter that can be passed. This parameter is a List containing associated probabilities.
Bonus:
This code generates a random key:value pair from a list of tuples. When the teacher runs this code, a random question displays on the screen and waits for a student to answer. Press 1 to display the answer, 2 to quit.
import keyboard
import random
import time els = {'Hydrogen': 'H', 'Helium': 'He', 'Lithium': 'Li', 'Beryllium': 'Be', 'Boron': 'B', 'Carbon': 'C', 'Nitrogen': 'N', 'Oxygen': 'O', 'Fluorine': 'F', 'Neon': 'Ne', 'Sodium': 'Na', 'Magnesium': 'Mg', 'Aluminum': 'Al', 'Silicon': 'Si', 'Phosphorus': 'P', 'Sulfur': 'S', 'Chlorine': 'Cl', 'Argon': 'Ar', 'Potassium': 'K', 'Calcium': 'Ca', 'Scandium': 'Sc', 'Titanium': 'Ti', 'Vanadium': 'V', 'Chromium': 'Cr', 'Manganese': 'Mn'} print('1 Answer 2 quit')
def quiz(): while True: k, v = random.choice(list(els.items())) print(f'\nWhat is the Symbol for {k}?') pressed = keyboard.read_key() if pressed == '1': print(f'The answer is {v}!') elif pressed == '2': print("Exiting\n") exit(0) time.sleep(5)
quiz()
Finxter Challenge! Write code to allow the teacher to enter the answer!
Summary
This article has provided five (5) ways to get a random entry from a Dictionary to select the best fit for your coding requirements.
Good Luck & Happy Coding!
Programmer Humor – Blockchain
“Blockchains are like grappling hooks, in that it’s extremely cool when you encounter a problem for which they’re the right solution, but it happens way too rarely in real life.”source – xkcd
The article begins by formulating a problem regarding how to extract emails from any website using Python, gives you an overview of solutions, and then goes into great detail about each solution for beginners.
At the end of this article, you will know the results of comparing methods of extracting emails from a website. Continue reading to find out the answers.
You may want to read out the disclaimer on web scraping here:
Statistics show that 33% of marketers send weekly emails, and 26% send emails multiple times per month. An email list is a fantastic tool for both company and job searching.
For instance, to find out about employment openings, you can hunt up an employee’s email address of your desired company.
However, manually locating, copying, and pasting emails into a CSV file takes time, costs money, and is prone to error. There are a lot of online tutorials for building email extraction bots.
When attempting to extract email from a website, these bots experience some difficulty. The issues include the lengthy data extraction times and the occurrence of unexpected errors.
Then, how can you obtain an email address from a company website in the most efficient manner? How can we use robust programming Python to extract data?
Method Summary
This post will provide two ways to extract emails from websites. They are referred to as Direct Email Extraction and Indirect Email Extraction, respectively.
Our Python code will search for emails on the target page of a given company or specific website when using the direct email extraction method.
For instance, when a user enters “www.scrapingbee.com” into their screen, our Python email extractor bot scrapes the website’s URLs. Then it uses a regex library to look for emails before saving them in a CSV file.
The second method, the indirect email extraction method, leverages Google.com’s Search Engine Result Page (SERP) to extract email addresses instead of using a specific website.
For instance, a user may type “scrapingbee.com” as the website name. The email extractor bot will search on this term and return the results to the system. The bot then stores the email addresses extracted using regex into a CSV file from these search results.
In the next section, you will learn more about these methods in more detail.
These two techniques are excellent email list-building tools.
The main issue with alternative email extraction techniques posted online, as was already said, is that they extract hundreds of irrelevant website URLs that don’t contain emails. The programming running through these approaches takes several hours.
Discover our two excellent methods by continuing reading.
Solution
Method 1 Direct Email Extraction
This method will outline the step-by-step process for obtaining an email address from a particular website.
Step 1: Install Libraries.
Using the pip command, install the following Python libraries:
import re
import requests
from bs4 import BeautifulSoup
from collections import deque
from urllib.parse import urlsplit
import pandas as pd
from tld import get_fld
Step 3: Create User Input.
Ask the user to enter the desired website for extracting emails with the input() function and store them in the variable user_url:
user_url = input("Enter the website url to extract emails: ")
if "https://" in user_url: user_url = user_url
else: user_url = "https://"+ user_url
Step 4: Set up variables.
Before we start writing the code, let’s define some variables.
Create two variables using the command below to store the URLs of scraped and un-scraped websites:
You can save the URLs of websites that are not scraped using the deque container. Additionally, the URLs of the sites that were scraped are saved in a set data format.
As seen below, the variable list_emails contains the retrieved emails:
list_emails = set()
Utilizing a set data type is primarily intended to eliminate duplicate emails and keep just unique emails.
Let us proceed to the next step of our main program to extract email from a website.
Step 5: Adding Urls for Content Extraction.
Web page URLs are transferred from the variable unscraped_url to scrapped_url to begin the process of extracting content from the user-entered URLs.
while len(unscraped_url): url = unscraped_url.popleft() scraped_url.add(url)
The popleft() method removes the web page URLs from the left side of the deque container and saves them in the url variable.
Then the url is stored in scraped_url using the add() method.
Step 6: Splitting of URLs and merging them with base URL.
The website contains relative links that you cannot access directly.
Therefore, we must merge the relative links with the base URL. We need the urlsplit() function to do this.
parts = urlsplit(url)
Create a parts variable to segment the URL as shown below.
Next, we create the basic URL by merging the scheme and netloc.
Base URL means the main website’s URL is what you type into the browser’s address bar when you input it.
If the user enters relative URLs when requested by the program, we must then convert them back to base URLs. We can accomplish this by using the command:
if '/' in parts.path: part = url.rfind("/") path = url[0:part + 1]
else: path = url
Let us understand how each line of the above command works.
This URL is a relative link, and the above set of commands will convert it to a base URL (https://www.scrapingbee.com). Let’s see how it works.
If the condition finds that there is a “/” in the path of the URL, then the command finds where is the last slash ”/” is located using the rfind() method. The “/” is located at the 27th position.
Next line of code stores the URL from 0 to 27 + 1, i.e., 28th item position, i.e., https://www.scrapingbee.com/. Thus, it converts to the base URL.
In the last command, If there is no relative link from the URL, it is the same as the base URL. That links are in the path variable.
The following command prints the URLs for which the program is scraping.
The regression is built to match the email address syntax displayed in the new emails variable. The regression format pulls the email address from the website URL’s content with the response.text method. And re.Iflag method ignores the font case. The list_emails set is updated with new emails.
The next is to find all of the website’s URL links and extract them in order to retrieve the email addresses that are currently available. You can utilize a powerful, beautiful soup module to carry out this procedure.
soup = BeautifulSoup(response.text, 'lxml')
A beautiful soup function parses the HTML document of the webpage the user has entered, as shown in the above command.
You can find out how many emails have been extracted with the following command.
Insert the command before the email regex command. Precisely, place this command above the new_emails variable.
Run the program now.
Did the program work?
Does it keep on running for several hours and not complete it?
The program searches and extracts all the URLs from the given website. Also, It is extracting links from other domain name websites. For example, the Scraping Bee website has URLs such as https://seekwell.io/., https://codesubmit.io/, and more.
A well-built website has up to 100 links for a single page of a website. So the program will take several hours to extract the links.
Sorry about it. You have to face this issue to get your target emails.
Bye Bye, the article ends here……..
No, I am just joking!
Fret Not! I will give you the best solution in the next step.
Step 8: Fix the code problems.
Here is the solution code for you:
if base_url in weblink: # code1 if ("contact" in weblink or "Contact" in weblink or "About" in weblink or "about" in weblink or 'CONTACT' in weblink or 'ABOUT' in weblink or 'contact-us' in weblink): #code2 if not weblink in unscraped_url and not weblink in scraped_url: unscraped_url.append(weblink)
First off, apply code 1, which specifies that you only include base URL websites from links weblinks to prevent scraping other domain name websites from a specific website.
Since the majority of emails are provided on the contact us and about web pages, only those links from those sites will be extracted (Refer to code 2). Other pages are not considered.
Finally, unscraped URLs are added to the unscrapped_url variable.
Step 9: Exporting the Email Address to CSV file.
Finally, we can save the email address in a CSV file (email2.csv) through data frame pandas.
url_name = "{0.netloc}".format(parts)
col = "List of Emails " + url_name
df = pd.DataFrame(list_emails, columns=[col])
s = get_fld(base_url)
df = df[df[col].str.contains(s) == True]
df.to_csv('email2.csv', index=False)
We use get_fld to save emails belonging to the first level domain name of the base URL. The s variable contains the first level domain of the base URL. For example, the first level domain is scrapingbee.com.
We include only emails ending with the website’s first-level domain name in the data frame. Other domain names that do not belong to the base URL are ignored. Finally, the data frame transfers emails to a CSV file.
As previously stated, a web admin can maintain up to 100 links per page.
Because there are more than 30 hyperlinks on each page for a normal website, it will still take some time to finish the program. If you believe that the software has extracted enough email, you may manually halt it using try except KeyboardInterrupt and raise SystemExit command as shown below:
try:
while len(unscraped_url):
… if base_url in weblink: if ("contact" in weblink or "Contact" in weblink or "About" in weblink or "about" in weblink or 'CONTACT' in weblink or 'ABOUT' in weblink or 'contact-us' in weblink): if not weblink in unscraped_url and not weblink in scraped_url: unscraped_url.append(weblink) url_name = "{0.netloc}".format(parts) col = "List of Emails " + url_name df = pd.DataFrame(list_emails, columns=[col]) s = get_fld(base_url) df = df[df[col].str.contains(s) == True] df.to_csv('email2.csv', index=False) except KeyboardInterrupt: url_name = "{0.netloc}".format(parts) col = "List of Emails " + url_name df = pd.DataFrame(list_emails, columns=[col]) s = get_fld(base_url) df = df[df[col].str.contains(s) == True] df.to_csv('email2.csv', index=False) print("Program terminated manually!") raise SystemExit
Run the program and enjoy it…
Let’s see what our fantastic email scraper application produced. The website I have entered is www.abbott.com.
Output:
Method 2 Indirect Email Extraction
You will learn the steps to extract email addresses from Google.com using the second method.
Step 1: Install Libraries.
Using the pip command, install the following Python libraries:
bs4 is a Beautiful soup for extracting google pages.
The pandas module can save emails in a DataFrame for future processing.
You can use Regular Expression (re) to match the Email Address format.
The request library sends HTTP requests.
You can use tld library to acquire relevant emails.
time library to delay the scraping of pages.
pip install bs4
pip install pandas
pip install re
pip install request
pip install time
Step 2: Import Libraries.
Import the libraries.
from bs4 import BeautifulSoup
import pandas as pd
import re
import requests
from tld import get_fld
import time
Step 3: Constructing Search Query.
The search query is written in the format “@websitename.com“.
Create an input for the user to enter the URL of the website.
The format of the search query is “@websitename.com,” as indicated in the code for the user_keyword variable above. The search query has opening and ending double quotes.
Step 4: Define Variables.
Before moving on to the heart of the program, let’s first set up the variables.
page = 0
list_email = set()
You can move through multiple Google search results pages using the page variable. And list_email for extracted emails set.
Step 5: Requesting Google Page.
In this step, you will learn how to create a Google URL link using a user keyword term and request the same.
The Main part of coding starts as below:
while page <= 100: print("Searching Emails in page No " + str(page)) time.sleep(20.00) google = "https://www.google.com/search?q=" + user_keyword + "&ei=dUoTY-i9L_2Cxc8P5aSU8AI&start=" + str(page) response = requests.get(google) print(response)
Let’s examine what each line of code does.
The while loop enables the email extraction bot to retrieve emails up to a specific number of pages, in this case 10 Pages.
The code prints the page number of the Google page being extracted. The first page is represented by page number 0, the second by page 10, the third by page 20, and so on.
To prevent having Google’s IP blocked, we slowed down the programming by 20 seconds and requested the URLs more slowly.
Before creating a google variable, let us learn more about the google search URL.
Suppose you search the keyword “Germany” on google.com. Then the Google search URL will be as follows
https://www.google.com/search?q=germany
If you click the second page of the Google search result, then the link will be as follows:
The user keyword is inserted after the “q=” symbol, and the page number is added after the “start=” as shown above in the google variable.
Request a Google webpage after that, then print the results. To test whether it’s functioning or not. The website was successfully accessed if you received a 200 response code. If you receive a 429, it implies that you have hit your request limit and must wait two hours before making any more requests.
Step 6: Extracting Email Address.
In this step, you will learn how to extract the email address from the google search result contents.
The Beautiful soup parses the web page and extracts the content of html web page.
With the regex findall() function, you can obtain email addresses, as shown above. Then the new email is updated to the list_email set. The page is added to 10 for navigating the next page.
n = len(user_keyword)-1
base_url = "https://www." + user_keyword[2:n]
col = "List of Emails " + user_keyword[2:n]
df = pd.DataFrame(list_email, columns=[col])
s = get_fld(base_url)
df = df[df[col].str.contains(s) == True]
df.to_csv('email3.csv', index=False)
And finally, target emails are saved to the CSV file from the above lines of code. The list item in the user_keyword starts from the 2nd position until the domain name.
Run the program and see the output.
Method 1 Vs. Method 2
Can we determine which approach is more effective for building an email list: Method 1 Direct Email Extraction or Method 2 Indirect Email Extraction? The output’s email list was generated from the website abbot.com.
Let’s contrast two email lists that were extracted using Methods 1 and 2.
From Method 1, the extractor has retrieved 60 emails.
From Method 2, the extractor has retrieved 19 emails.
The 17 email lists in Method 2 are not included in Method 1.
These emails are employee-specific rather than company-wide. Additionally, there are more employee emails in Method 1.
Thus, we are unable to recommend one procedure over another. Both techniques provide fresh email lists. As a result, both of these methods will increase your email list.
Summary
Building an email list is crucial for businesses and freelancers alike to increase sales and leads.
This article offers instructions on using Python to retrieve email addresses from websites.
The best two methods to obtain email addresses are provided in the article.
In order to provide a recommendation, the two techniques are finally compared.
The first approach is a direct email extractor from any website, and the second method is to extract email addresses using Google.com.
Regex Humor
Wait, forgot to escape a space. Wheeeeee[taptaptap]eeeeee. (source)
These examples use functions from the math library.
Add the following code to the top of each script. This snippet will allow the code in this article to run error-free.
import math
Method 1: Use a Generator Expression
This example uses a Generator Expression. This expression performs any operations in memory first and returns an iterable object. An efficient option as upon completion, memory is cleared, and variables erased.
nums = [18, 43, 54, 65, 31, 21, 27]
nums = (math.pow(num,2) for num in nums)
print(nums)
The above code declares a List of Integers and saves it to the variable nums.
Next, a Generator Expression is called and applies the math.pow() function from Python’s built-in math library to each list element. The results save back to nums.
If output to the terminal at this point, an iterable Generator Object similar to the following displays.
<generator object at 0x000002468D9B59A0>
To turn the Generator Object into a List, run the following code.
Note: The math.pow() function accepts two (2) integers as arguments: x (the value) and y (the power), and returns the value of x raised to the power of y.
nums = [18, 43, 54, 65, 31, 21, 27]
nums = [math.sqrt(num) for num in nums]
print(nums)
The above code declares a List of Integers and saves it to the variable nums.
Next, List Comprehension is called and applies themath.sqrt() function from Python’s built-in math library to each List element. The results save back to nums.
If output to the terminal, the following displays.
The above code declares a List of numbers and saves it to the variable nums.
Next, List is called and passed an argument map(), which in turn passes the lambda function to apply the math.degrees() function from Python’s built-in math library to each List element. The result returns to nums.
If output to the terminal, the following displays.
Note: The math.degrees() function accepts an angle as an argument, converts this argument from radians to degrees and returns the result.
Method 4: Use a For Loop
This example uses a for Loop to apply a mathematical operation to each List element.
nums = [18, 43, 54, 65, 31, 21, 27]
i = 0 while i < len(nums): nums[i] = round(math.sqrt(nums[i]), 2) i += 1 print(nums)
The above code declares a List of Integers and saves it to the variable nums. Then, a counter variable, i is declared, set to 0.
Next, a while loop is instantiated and iterates through each List element, applying the math.sqrt() function, and limiting the decimal places to two (2). The results save back to the appropriate element in nums.
Upon completion of the iteration, the output is sent to the terminal.
[4.24, 6.56, 7.35, 8.06, 5.57, 4.58, 5.2]
Bonus: Calculate Commissions on each List Element
This bonus code extracts two (2) columns from a real-estate.csv file, the street and price columns and converts each into a List.
Then, the street column is converted from UPPERCASEuppercase() to Title Case by applying the title() function. Next, Sales Commissions are calculated and applied to each price element using round().
import pandas as pd df = pd.read_csv('real-estate.csv', usecols=['street', 'price']).head(5) street = list(df['street'])
street = [item.title() for item in street] prices = list(df['price'])
commis = [round(p*.06,2) for p in prices] print(street)
print(prices)

 Programming Challenge: Given a list of lists (nested list). Find and return the longest inner list from the outer list of lists.
Programming Challenge: Given a list of lists (nested list). Find and return the longest inner list from the outer list of lists. 
 Let’s have a look at a slight variant to check the length of the longest list instead.
Let’s have a look at a slight variant to check the length of the longest list instead. At least does the approach also work when passing in an empty list due to the ternary operator used in the first line.
At least does the approach also work when passing in an empty list due to the ternary operator used in the first line. Note: If you need the length of the longest list, you could simply replace the last line of the function with
Note: If you need the length of the longest list, you could simply replace the last line of the function with 


 Info:
Info:  Note: A pragma from an imported file does not apply to the importer file, i.e. the file that imports the imported file.
Note: A pragma from an imported file does not apply to the importer file, i.e. the file that imports the imported file.

 Problem: However, the conversion process from a tuple to set doesn’t always work because if you try to convert a tuple of mutable values, Python will raise the
Problem: However, the conversion process from a tuple to set doesn’t always work because if you try to convert a tuple of mutable values, Python will raise the 













 The Plot: Mr. Sinclair, an 8th great Science Teacher, is giving his students a quiz on the first 25
The Plot: Mr. Sinclair, an 8th great Science Teacher, is giving his students a quiz on the first 25 


 Finxter Challenge!
Finxter Challenge!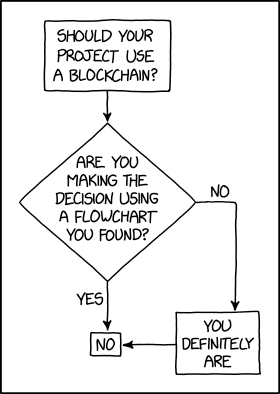

 Recommended Tutorial:
Recommended Tutorial: 






 Finxter Challenge!
Finxter Challenge!